
專案進行過程中,當你想進行某些預測需要搜集特徵,並透過許多感測器許多特徵,但實際上,你只是想知道是不是有些感測器數值對預測是沒有幫助,以利後續拓展設備時的成本評估,或是幫助現場人員訂定一些判斷標準或預警,或許你會想知道這個特徵篩選的方法。AIF工程師整理了專案經驗中遇過的特徵篩選方法並與讀者分享。
在監督式學習的領域中,除了得到一個準確的模型,更多實際的問題是:「如何能夠知道資料中的那些變項/特徵對預測是重要的?」或是「如何能過濾掉那些沒有幫助的特徵?」最常見的莫過於根據機器學習演算法,對特徵的使用程度或依賴程度作估計(e.g. sklearn套件中各類模型的feature_importances屬性)。另外,也可以使用forward/backward elimination的方式,移除特徵並觀察對評估指標的影響,作為特徵的重要程度。
這邊將介紹一種名為Boruta的特徵篩選方法,與上述作法得到每個特徵的重要程度數值不同,使用Boruta後,每個特徵將會被歸類成幾類(重要、無法確定、不重要),而不重要的特徵即代表可被刪除。這個方法在2010年就被提出,並在R語言上被實踐,雖然距離方法提出已有一段時間,身邊也較少人聽過,但這個概念個人認為蠻有趣也對實務有些幫助,因此在這邊介紹給大家了解。
從置換檢定開始說起
從這篇Boruta論文中,可以明顯觀察到作者從生物統計的觀點切入,由於在統計學中,其中一個最重要的觀念為假設檢定,也就是「根據手中取得的資料,判斷在某個特定假設成立的狀況下,觀察到這樣資料的可能性有多高。」例如先前AI生成高解析度人臉照片的技術幾乎能夠以假亂真,為了檢驗「AI產生的照片跟真的一樣」這個說法是不是成立,我們可以利用假設檢定的概念,收集一些AI生成的假人臉與真實人臉的照片,並讓一些人來判斷照片是真的還是假的?
假設AI產生的照片與實際照片真的非常類似,那大家判斷出假照片的正確率應該會在50%左右,如果正確率「顯著」高於50%,那就代表AI產生的照片與實際照片非常類似的可能性非常小,我們就能判斷說:「唉唷,現在AI產生的人臉還不足以騙過我們。」
但正確率51%算不算高於50%?50.5%呢?甚至50.000001%算不算高於50%?這個判斷標準會隨著我們手中觀察到的資料數量而有不同。但可以想像,如果我們手上只有少少的資料,例如只找10個人判斷,那計算出來的正確率需要高於50%非常多,例如 70%,我們才較有信心說:「人真的不會被騙」。但如果我們手上收集了很多的資料,例如請200個人幫忙判斷,那正確率也許高於50%一些些,例如57%,我就有相同的信心程度了。(若有興趣了解更完整的假設檢定概念,歡迎大家參考相關的書籍或資源)
假設檢定中一個很常使用的無母數方法是:置換檢定(Permutation test),也就是不斷隨機打亂數值,得到在虛無假設成立的狀況下,資料的分布狀況(抽樣分布),進而判斷手上的真實資料狀況發生的可能性是否過低?如果過低就代表虛無假設應該是不成立的。同樣舉個例子,現在我們手上有10個男生與10個女生共20筆身高資料。

如果想利用置換的方式檢驗「男生與女生的身高平均數是否相同?」我們可以先將這20個身高隨機打亂,分給10位男生與10位女生,再計算此狀況下,男生與女生身高平均的差異(這次可能身高差異為-2.8公分)。

重複進行多次這樣的動作,會得到許多數字,這些數字的範圍就代表「假設男生與女生身高平均數相同的狀況下,因為抽樣造成的誤差可能的分布範圍」。
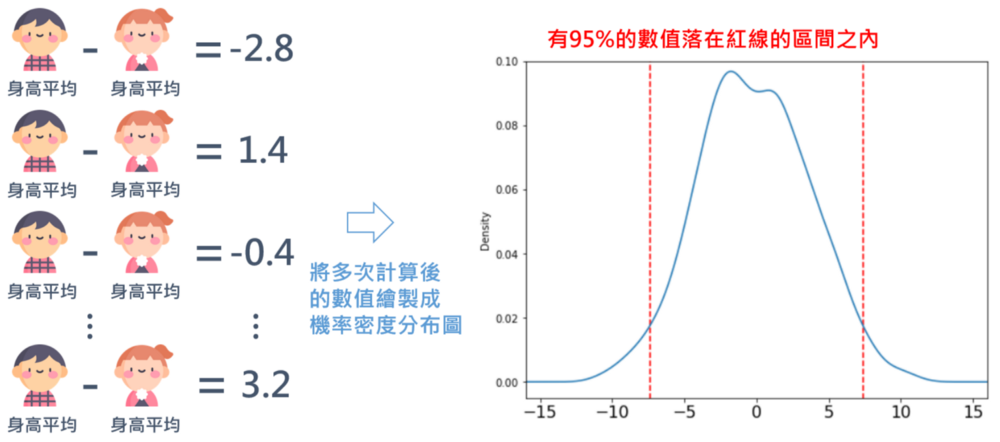
如果手上有10位男性與10位女性的真實身高資料,平均相減後的數字,距離隨機打亂後抽樣的分布範圍很遠的話,那我們就會判斷這樣的資料很難從男生與女生身高相同的情境下觀察到,進而得到「男生與女生身高平均數不相同」的結論。
回到機器學習的領域,一開始,我們提到目前很常使用「特徵重要程度」作為客觀指標做特徵挑選,但即使是完全與y無關的雜訊,也可能在特徵重要程度上有些微的數值,這些數值將依據模型而有所不同。因此,如何找到一個合適的切分點區分無用與可能有用的特徵,就是一件需要注意的事情。Boruta方法結合了置換檢定與特徵重要程度的概念,可以針對各個特徵重要程度,檢定是否顯著大於隨機產生的特徵。
以隨機森林(Random Forest)作為基底
事實上,Boruta大致的概念到此已經結束了,亦即打亂特徵數值(意指:以產生與預測變項完全無關的特徵)後訓練模型,並且記錄打亂過後的特徵對模型的重要程度,多次進行以上步驟後,得到隨機特徵重要程度的分布,再依此判斷真實特徵為隨機特徵的可能性。無論使用何種機器學習模型都可以用這種方式判斷。
然而,作者在提出該演算法時,特別提出了以隨機森林作為計算特徵重要程度的基底模型,隨機森林透過平行建立多棵決策樹、並且在訓練每棵決策樹時以取後放回的方式抽樣資料令每一棵決策樹有一定程度的變異,提高了模型對抗資料中雜訊的能力,這樣平行建立決策樹的方法恰巧與置換檢定中需要重複多次的性質不謀而合。
另外,在模擬無關特徵的效果時,Boruta並非直接將原本特徵作置換處理,而是複製一份特徵後再將其打亂(因此若原本資料有p個特徵,在每次建模時則會有2*p個特徵,其中p個為原始特徵、另外p個為打亂過後的特徵)。
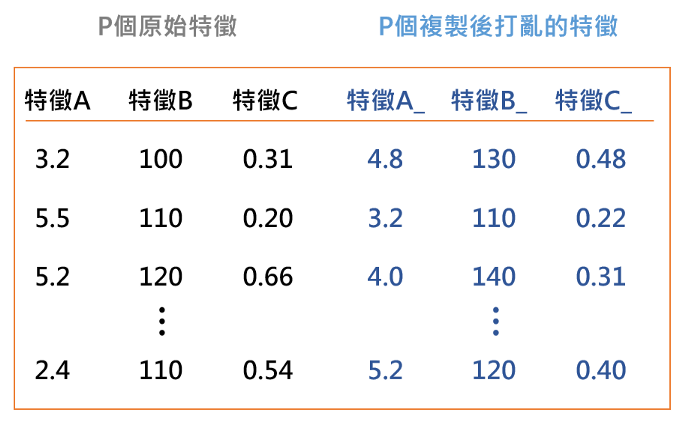
在訓練完模型並得到每個特徵(包含打亂後的p個特徵)的特徵重要性後,Boruta會針對每個特徵進行假設檢定:
虛無假設(H0):特徵重要程度與隨機特徵重要程度的最大值無顯著差異
對立假設(H1):特徵重要程度顯著大於或小於隨機特徵重要程度的最大值
實際在執行時,會執行多次的迭代,並累加計算每個特徵的重要程度大於隨機特徵重要程度的次數,再依二項式分布進行檢定(在虛無假設下,第N次迭代時,期望次數E(N) = 0.5*N,S = (0.25*N)^0.5)。每次檢定中顯著高於/低於隨機特徵重要程度的特徵將被歸類為重要/不重要,並從特徵中剔除,再進行下一次的迭代,直到迭代次數高於最高迭代次數或是所有特徵皆被刪除後停止。最後未被歸類的特徵則會被分為無法判定的類別。
總結
在常見的特徵挑選方法中,多數是針對特徵得到重要程度數值後再進行人工判斷,然而Boruta演算法結合了統計檢定的方式使得我們有一個客觀的基準能夠判斷哪些特徵是重要/不重要的,與Boruta相似的是Permutation Importance,同樣利用置換的方式得到改為隨機變項後模型的效果並與原始效果進行相減,然而此方式仍然需要人為設定閾值作為挑選特徵的基準。
雖然機器學習與統計關係非常密切,但就個人經驗來說,進行機器學習時實際使用到推論統計的場合其實並沒有非常多,當初看到Boruta這個特徵挑選的方法時確實是眼睛為之一亮,透過直觀的方式評估特徵是否可能與目標變項無關,因此在此也分享給大家認識。
Boruta演算法實踐
在Python中也支援Boruta演算法,可以使用pip或conda進行安裝,除了原始Boruta演算法的部分外,boruta_py也相容於sklearn,並且不僅限於隨機森林,可使用不同的機器學習模型進行特徵重要程度的判斷。另外在檢定時也可設定顯著高於n-percentile的隨機特徵重要程度,而不需要被限制在最大值上。若熟悉skearn套件的話在boruta_py的使用上應無太大問題。
本篇轉載自<機器學習中的特徵篩選:Boruta>,原文
本文參考論文:
- 原始論文
- Python Implementation