

科技帶動人工智慧等技術的進步,不僅幫助數據的收集與處理,各種厲害的演算法不斷突破。但實際上,除了電商及網路服務能取得大量數據之外,仍有許多產業的資料量並不大,Landing AI創辦人吳恩達日前透過網路直播分享自己對於模型及資料的看法,並提出一個機器學習工程師應該將 80% 的工作放在資料準備上,以確保資料品質,這番說法也讓許多人重新思索數據與模型的關係。
我們知道,要完成一個AI專案必須要有模型或是演算法再加上資料。在一個鋼板表面瑕疵檢測AI專案中,需要檢測的瑕疵種類有39種,目前完成的系統主要是以神經網路模型訓練並經過調教,正確率為76.2%,距離目標的90%正確率還有一段距離,作為一個專案的領導人,你會選擇先調整模型還是檢查資料?
許多人在開發AI系統時,為了獲得最佳的結果,通常會將大部份的精力放在模型的修改調整或是演算法上。但是,Landing AI創辦人吳恩達從自己的專案經驗發現,許多問題不是只有調整程式就能解決,而是要系統性的提升資料品質。在上面的例子中,嘗試使用多種SOTA模型後,仍無法提升正確率;改以提升資料品質為主的方式後,兩週內即達到93.1%正確率。證明資料的品質對於模型的表現有極大的幫助。
當AI系統表現不佳時,許多團隊會本能地嘗試優化模型,但實際上,集中精力改善資料也許會更有效。
二八法則,資料更需要被重視
吳恩達提出了八十比二十的法則,他認為:「機器學習工程師 80% 的工作應該在準備高品質的資料上。」但是,當他在arXiv上翻閱了約100篇的AI相關論文後,卻發現有99%都在說明如何改善模型。吳恩達說,如果99%的研究都在討論佔比20%的工作,那麼我們應該轉移些心力在另外80%的工作上。
以模型為中心或是以資料為中心?
吳恩達提到「以模型為中心」以及「以資料為中心」兩種做法策略,「以模型為中心」的策略主要是盡量收集資料,並開發出一個好模型來處理資料中的雜訊。在以模型為中心的做法中,可以將資料集視為固定不變,調整的是模型的能力,主要透過反覆訓練來提升模型的能力。但在「以資料為中心」的做法下,模型是不變的,需要調整的是資料的品質。資料的一致性是該做法重要的目標,需要不斷調整提升資料品質,因而需要透過工具的使用及流程來協助,這樣可以讓多種模型都能得到不錯的結果。
吳恩達舉例,假設語音辨識因為背景有車輛噪音導致效果不好,該如何改善?以模型為中心的做法會是,調整模型架構以提升準確度;而以資料為中心的做法則是變造資料以提升準確度,例如:合成更多有背景車輛噪音的語音資料,以抵抗背景車輛噪音。
吳恩達說,由於目前神經網路的偏差都很小,以小於一萬筆的少量資料來說,大部分模型都能良好地符合資料集,如果要再提升模型的表現,就要解決資料變異性的問題,而提升資料品質正好是減少變異的好方法。
當資料量越少,模型受資料雜訊的影響也就越大,但即使是少量乾淨的資料也能找到好模型。例如吳恩達自己就多次遇到有些專案只能提供40或100張影像資料,這才發現,只要有工具或流程確保資料夠乾淨,模型也能有不錯的結果。
清理資料還是增加資料量?
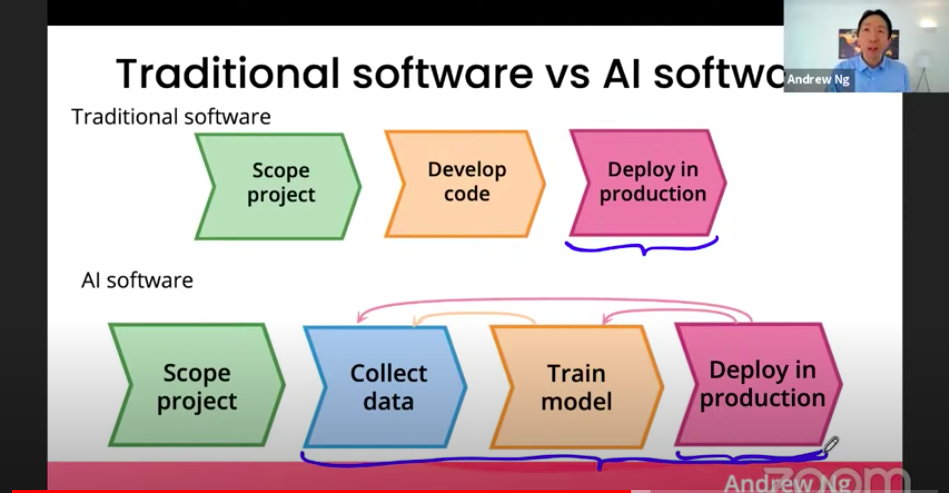
一個機器學習專案的過程可分為以下四個階段:1.專案範圍(Scope project)、2.資料搜集(Collect data)、3.模型訓練(Train model)、4.產品部署(Deploy in production)。
實際上,在專案過程中,光是資料的清理就會耗費許多時間,可能會遇到的問題還包含資料的格式以及雜訊處理部分。例如在資料格式的部分,不同人在標註同一份資料時,需要確認成員的標註規則是否一致,如果不一致,則需要更新並統一標註規則。
吳恩達提到,面對資料時,去除資料雜訊或是增加資料集數量都是可行的方法。假設今天有500筆資料,其中12%為資料錯誤或標註不一致的雜訊問題,透過去除資料中的雜訊,或是將資料集數量加倍,再收集另外500筆資料都能得到相近的效果。第一種方法只要找出60筆有問題的資料重新標註即可解決;但是第二種方法則需要重新收集並標註另外500筆資料,相對較費工。
此外,目前除了電商或是其他以網路為主的互動性服務可能取得非常多資料外,大多產業的資料多在10000筆以下,因此,目前機器學習工程師面對的也多是10000筆以下的資料規模,而這個數量差不多是人力可以逐一檢查的極限,就改進資料品質而言,模型仍有大幅提升的空間。
如何系統化管理資料的品質?MLOps是個方法
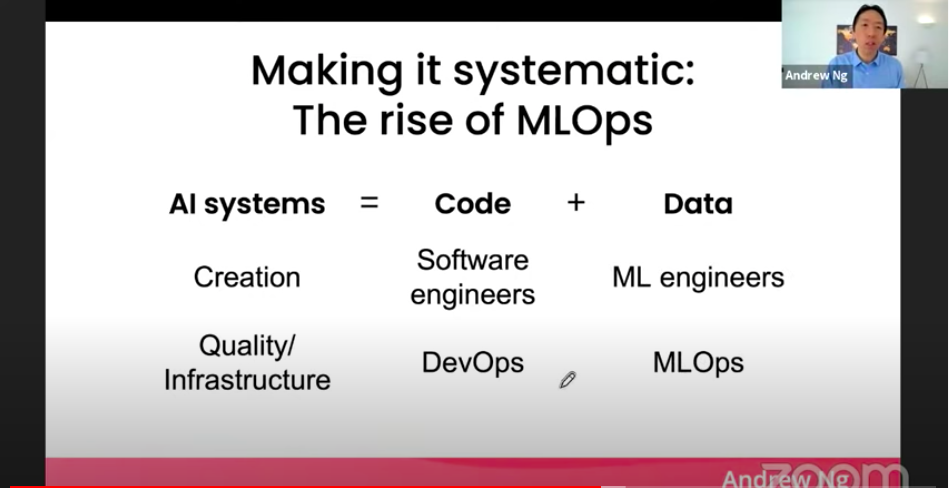
吳恩達認為,可以透過開發MLOps工具幫助AI團隊建立高質量的數據集。他提到,現行的軟體開發有版本控管工具,能幫助管理工程師們開發的程式,但資料不能只透過版本控管,還需要新的工具協助找出問題,讓整個流程更加有效率。
MLOps是Machine learning加上DevOps的組合字,主要目標是透過完整的系統流程,幫助機器學習專案團隊能進行業務、工程與營運等多個團隊的溝通與合作。可以用下圖來理解:
傳統軟體與AI軟體的開發流程比較如下:
由於MLOps主要的目標是要確保整個專案週期中,各個階段都有高品質的資料可以使用,因此在不同的階段也有以下不同的任務:
- 資料搜集階段(Collect data):如何定義與收集資料?
- 模型訓練階段(Train model):如何改變資料來提升模型表現?
- 產品部署階段(Deploy in production):利用哪些資料來追蹤概念或資料分布的漸變?
這邊值得注意的地方是,許多人會以為當機器學習到了部署階段就差不多要結束了,其實不然,此時整個專案只完成一半。因為部署後,資料會一直隨時間改變,所以需要持續監控部署後的表現,並且取回新的資料持續微調模型。
改變心態,從大數據變成好數據
許多人會認為進行機器學習專案時,數據越多越大越好。實際上,比起大數據,品質良好的數據更為重要。但是什麼是好的數據呢?吳恩達提出以下需要注意的重點:
1. 定義需一致,除了好的標註定義之外,標註的一致性也很重要。
2. 資料必須要涵蓋重要案例,也就是必須要包含實際應用的場景與狀況。
3. 產品上線後,資料需要回饋以更新資料分佈。此外,適當的資料集大小以及資料的隱私、偏差等問題,都是需要特別注意的地方。他也特別提醒,當使用數量較少的資料時,提高數據品質的工具與服務也就特別重要。