
人工智慧發展如日中天,如何和電腦對話逐漸成為現代人必備的技能之一。然而,程式語言百百種,如何選擇自己適合的工具就很重要。這篇文章以一個資料科學家的觀點出發,分析當前熱門的三種程式語言,希望對讀者有所裨益。
在「資料分析工具那麼多,該怎麼選? 🛠️」這一篇文章中,有稍微提及了資料科學的工具鏈與生態。「做資料分析一定要寫程式嗎?」是許多分析人會面臨的抉擇與問題,程式的入門是相對比較高的門檻。但隨著資料科學的演進,許多商業軟體都逐漸成熟。從完整的套裝軟體到實現彈性比較強的程式來說,大概可以把常見的資料分析工具分成幾種類型:
① BI 工具
② 分析模型套裝軟體
③ 程式語言
① BI 工具 和 ② 分析模型套裝軟體 可以讓分析者花費較少的精力的程式的負擔上,
對於非工程背景的人來說門檻比較低,更能夠專注在分析上。不過相對來說,就會受限於工具的能力,不同工具可以提供的功能不完全相同。運用 ③ 程式語言 作為分析的工具,主要可以有更彈性的支援。
資料科學當中的程式語言
「程式語言」是分析者的工具中擁有比較大的彈性與使用門檻的手段,想要怎樣的資料操作流程或模型方法都可以自己實現。通常會有兩種情況是只有程式才能達到的:
- 客製化的資料處理過程,例如資料很特別、或是數量很大
- 使用最新或冷門的模型,套裝軟體沒有提供
當然使用程式語言也不是要從零開始寫程式,現在也有很多第三方的工具可以讓分析更有效率也更方便。不同的程式語言對於資料分析的支援程式也不同,以目前主要用於資料分析的程式語言主要有三個:
- 基於統計學的 R 語言
- 程式架構與分析生態完整的 Python
- 集結 Python、R 和 C++ 一體的 Julia
基於統計學的 R 語言
R 語言一開始的設計就是基於「數學」,主要用於統計分析、資料分析的目的。根據官網的介紹,R 是一種用於統計運算與畫圖的語言與環境。R 當中提供了非常多種統計相關的方法,例如線性與分線性的模型、假設檢定、時間序列或是分類/分群等等。另一個優勢是提供了高質量的圖表,也包含了數學符號和公式(蠻多論文都可以一眼看出 R 風格的圖表)。
開發 R 語言的創始者分別是紐西蘭奧克蘭的兩位統計學家 Ross Ihaka 和 Robert Gentleman,現在是由「R 語言開發核心團隊」以開源的方式進行協作。值得一提的是,R 是 S 語言的一個 GNU 開源專案,跟 S 語言有高度的相容性。S 語言是統計研究當中的工具,而 R 則提供開源的方式提供開發。
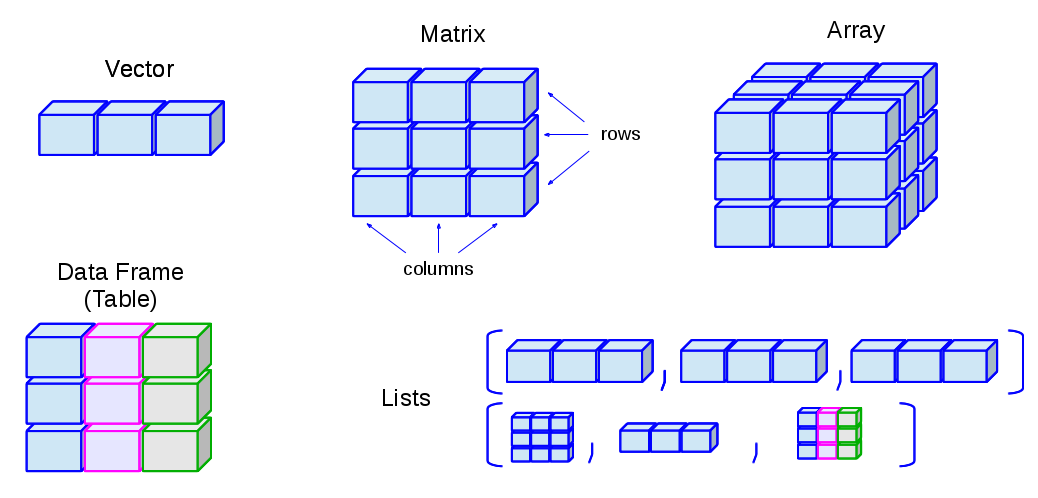
R 的特定是他以函數型編程(Functional Programming)與統計分析作為設計理念,在程式當中的基本型態是以向量(Vector)和矩陣(Matrix)的概念為最小單位,是一種高度數學化的特性。
另外介紹兩個重要的開發夥伴: RStudio 和 CRAN。 RStudio 作為 R 最主要的編譯開發環境(IDE), CRAN(Comprehensive R Archive Network)是 R 當中的套件管理平台,收錄/維護了官方與第三方的套件提供下載。
程式架構與分析生態完整的 Python
Python 是一個作為各種開發使用的程式語言,直譯與強型別的程式語言。Python 支援多種開發的混合模型,包含物件導向(OOP)與函數式編程(FP)。Python 也可以作為 Script 語言使用,是一種膠水語言。Python 的設計哲學強調簡潔的語法,規定使用空格縮排的特性讓程式碼有較高的可讀與一致性。網路上也流傳一句經典的話:「人生苦短,我用 Python」來描述的 Python 的精妙之處。
Python 的初始開發者是 Guido van Rossum ,第一版在 1991 年發布。據說 Guido van Rossum 當時是「為了打發時間而開發 Python」。他在開發完 Python 之後先後在 Google 及 Dropbox 工作,前幾年短暫退休後覺得太無聊近期又加入了 MicroSoft。
Python 僅僅作為一個程式的話,是難以扛起資料分析當中的數學底子。那為什麼 Python 會在數據分析當中扮演一席之地呢?原因是 Python 的另外一個優點是擁有強大的開源生態,在 Python 當中的套件幾乎無奇不有,絕大部分的資訊工作都可以看到 Python 的身影。在資料分析當中有 Numpy 和 Pandas 打下了 Python 在數學與資料的重要元件之後,也奠定了 Python 的地位 - 具有程式架構與數據分析的整合。除此之外也陸續發展出各種套件:

- 資料收集: Request、beatifulsoup、Scrapy
- 資料前處理與科學計算: NumPy、 SciPy、 Pandas
- 資料視覺化: Matplotlib、 Seaborn、 Bokeh、 Plotly
- 模型訓練: Statsmodels、SciKit-Learn、xgboost
- 深度學習: TensorFlow、Pytorch、Keras
- 自然語言與文本資料處理: NLTK、Gensim
集結 Python、R 和 C++ 一體的 Julia
Julia 是一種動態程式語言,最初是為了滿足高效能的數值分析和科學計算而設計的。為了達到效能的需求, Julia 具備即時編譯的效能。換句話說,Julia 集結 Python 的簡潔、R 的數學特性 與 C++ 的效能於一體。而在資料分析方面,Julia 也支援許多科學分析套件與機器學習的套件,例如醫療、AR擴增實境、基因組學及風險管理等領域。
原始的三位設計者分別是 Jeff Bezanson、 Stefan Karpinski 以及 Viral B. Shah 與 Alan Edelman 教授 指導,最早是從 MIT 的 Julia Lab 所發展。Julia 語言是全球熱度上升最快的程式語言之一,2012 年正式公開此計畫,也在 2018 由 MIT 實驗室正式發布了 Julia 1.0。
身為分析工作者,應該如何選擇呢?
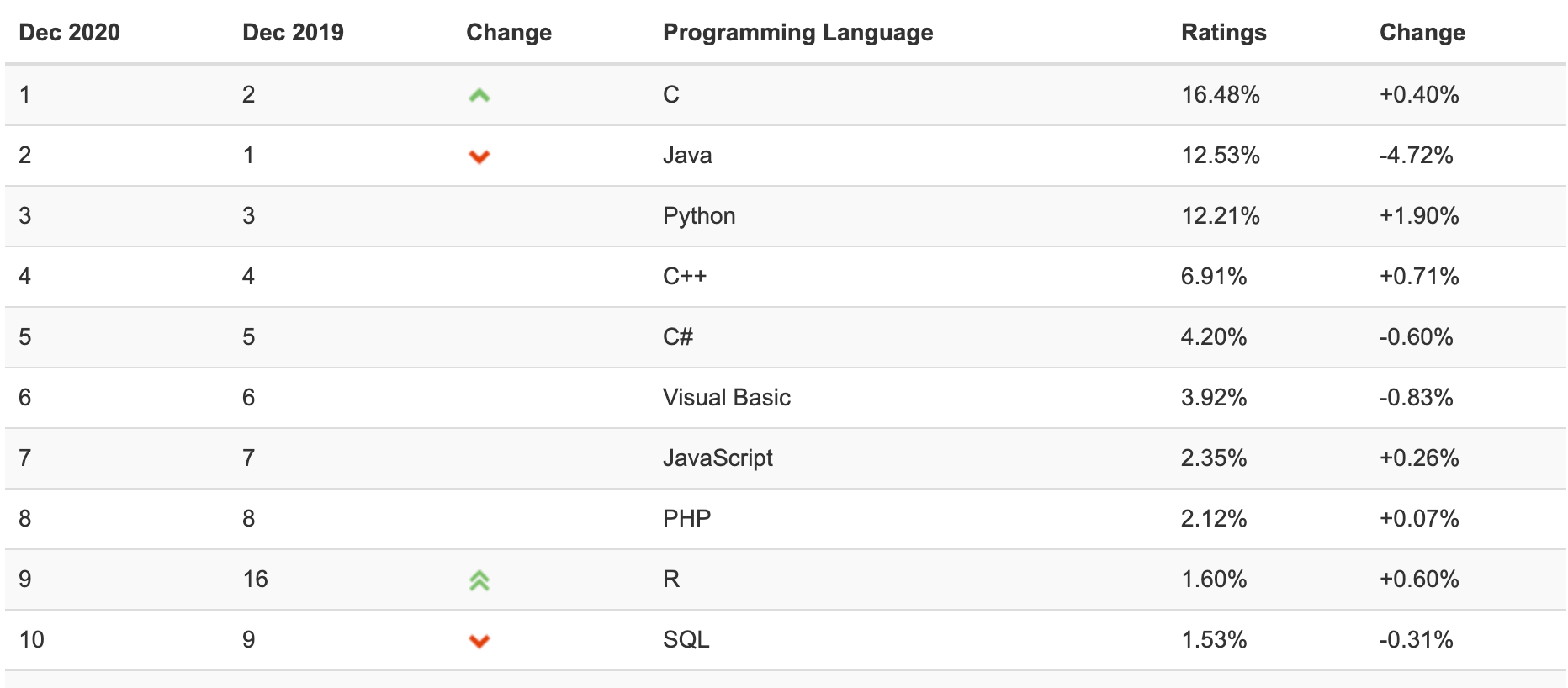
從最新一期 TIOBE 的程式語言排行來看,Python 跟 R 都持續的在熱門的名單當中。
去年 Python 超過 C++ 達到了第三名,而後續幾個月也持續上升。值得觀察的是 Java 在 的百分比持續往下(五月時第一名的被 C 取代),而穩定上升的 Python 也持續逼近 Java。R 語言也在七月的時候,因為武漢肺炎疫苗研發需求而網上,達到 Tiobe 排名新高第八 名,目前也維持在前十名內。Julia 從 2016 首次進入前五十名的行列之後持續的往前,今年從去年的三十名進入的第二十六的位置。
另外一個我們來看 Stack Overflow Trends,不管放在一起比較討論量:
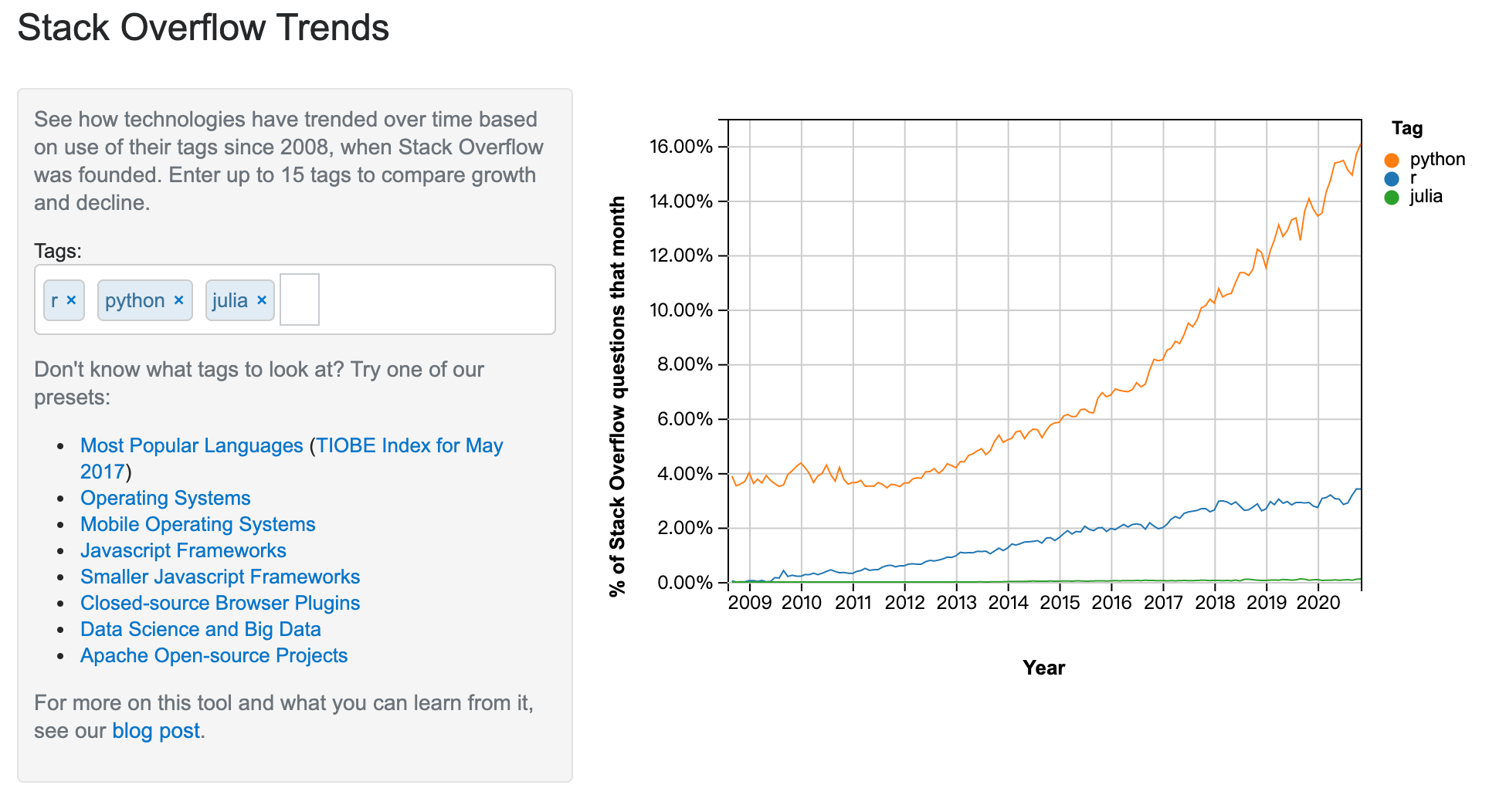
或是分開看趨勢:
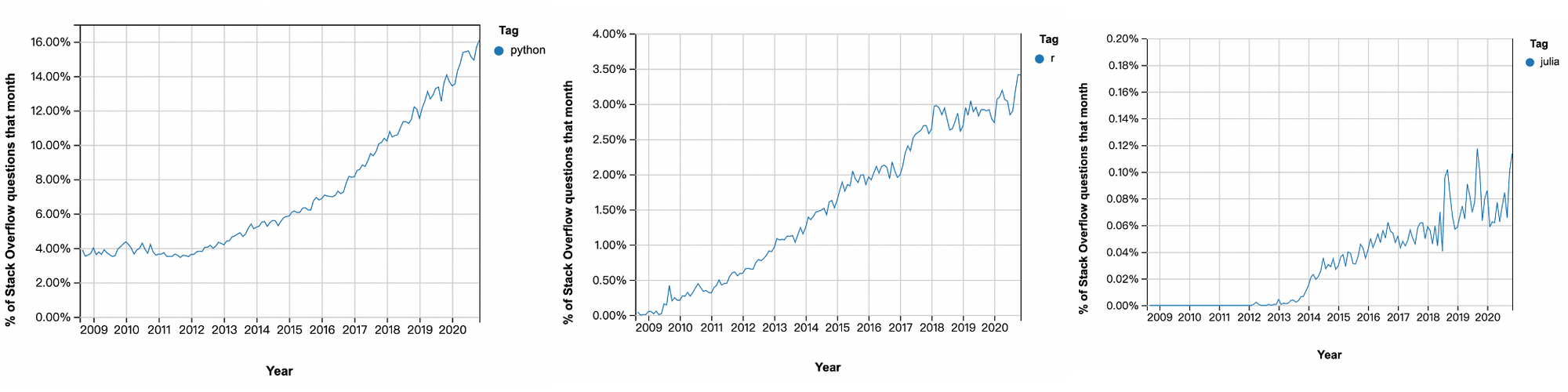
基本上你會發現這個 Python 網上趨勢還是蠻明顯的而 Julia 的討論還是相對有限。
R、Python 與 Julia 號稱是資料科學的三大程式語言,而他們也有各自的優缺點與一席之地。R 有著原生統計特性的優勢、對於各種數值運算與分析模型可以完美的結合,而 Python 加上適合的套件提供一個強大完善的數據分析程式生態系。近期由 MIT 所引領的 Julia 更號稱是結合 Python、C++、R 於一體的新程式語言,搭著資料分析新女神的名號橫空出世。那麼在 2020 這個時間點,想踏入資料分析領域的我們究竟該如何選擇呢?
就我自己的觀點來看:目前看起來 Python 是首選、有些比較專業的統計方法可以考慮 R ,至於 Julia 還要觀望一下。
原文刊登於: 資料科學家的工作日常