
在「基礎資料處理與分析」這場活動中,人工智慧科技基金會講師粘美玟(Kelly)透過之前AI在教育領域應用的相關經驗,分享如果現在手上有些資料,想做數據分析或是專案執行,常見的棘手問題及解決方法。
講師:粘美玟 Kelly / 財團法人人工智慧科技基金會 AI 工程師
資料很多,卻不知道怎麼用?
假設主辦單位在活動中蒐集到一些報名者資料及問卷回饋資訊,這些資料該如何利用?有哪些技巧可運用?
在拿到一筆新的資料時,無論是否嫻熟資料狀況,要做的第一件事就是:看這些資料的欄位及每個欄位的狀況。像是檢視今天這場活動參與者的資料,例如性別比、教育程度,藉此知道如果未來要舉辦同類型的活動,能如何推廣到更適合、更想要來聽這場演講的民眾身上。
拿到新的資料後,需要優先檢視資料分布的狀態,我們可以利用哪些工具來做這件事呢?首先可以透過圖型快速掌握一些重要數據,依照資料類型不同可以使用不同圖形。第一類是類別型變項,像是性別(男/女)、縣市(台北/台中/台南)這種標籤的資料,可以試著用長條圖、圓餅圖來呈現,但是,如果是連續的變項,例如:年齡、身高……等數值型的資料,就可以試著使用直方圖來呈現目前資料的狀態。另一種狀況是,如果不只探討一個變項的關係,而是想探討兩個變項間的關聯性,例如身高與體重的變化、或是薪水隨著年資的變化……等,就可以使用散佈圖或折線圖來幫助我們了解。接著,就來介紹這些圖型各自的優缺點及適用的情境。
想看訂單分佈該用長條圖還是直方圖
長條圖:最主要的功能就是呈現不同類別間,數量相對的狀況。例如:今天公司的主管做一個調查,想了解內部工程師所擅長的程式語言是什麼?這時候,就可以利用長條圖來呈現。這裡的程式語言屬於類別變項,我們可以很快的知道各個類別間的差異,也可以很快的讀出重要訊息,快速掌握整個公司的工程師,最擅長的語言與不擅長的語言。
長條圖也有缺點,如果類別數量太多,可能超過10個類別時,圖型就會變得非常的密集,也較難從圖中讀取重要資訊。所以,建議類別數量不要太多,可能5~6類就很多了。
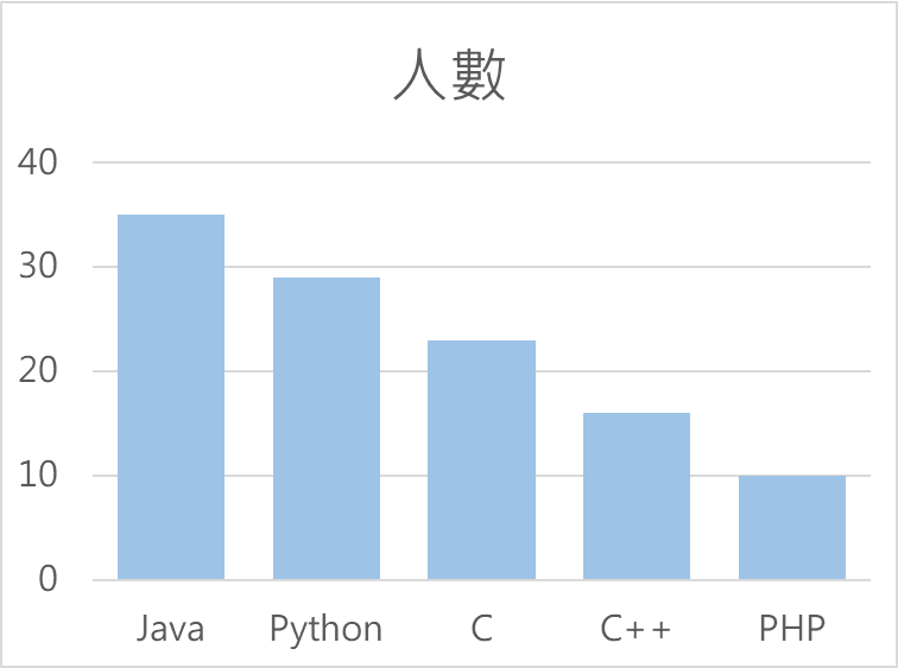
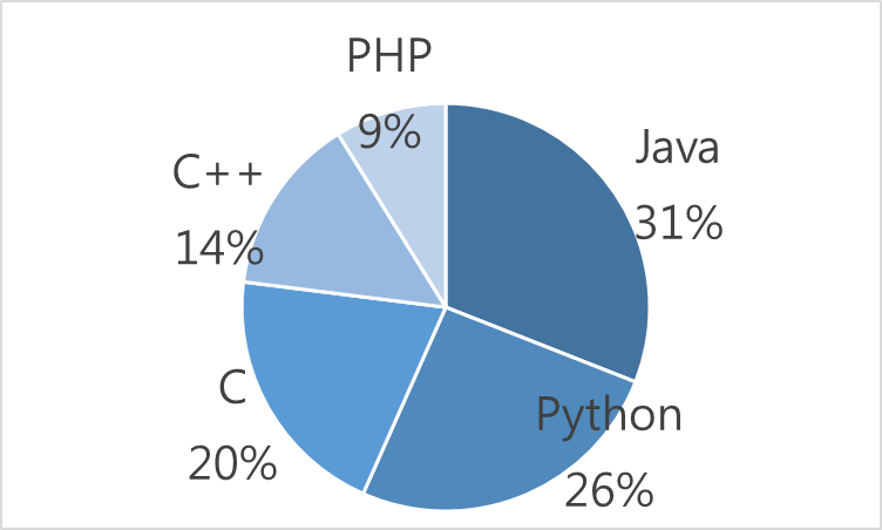
圓餅圖:適合呈現比例分佈,不同於長條圖適合呈現不同類別相對數值的落差,如果把這些頻率的數字轉成百分比的數字,透過圓餅圖,就能了解整個公司不同的程式語言的比例。例如,超過一半都是會寫Java或是Python的人員。
圓餅圖同樣也不太適合用在類別數量太多的時候,呈現效果較不好。
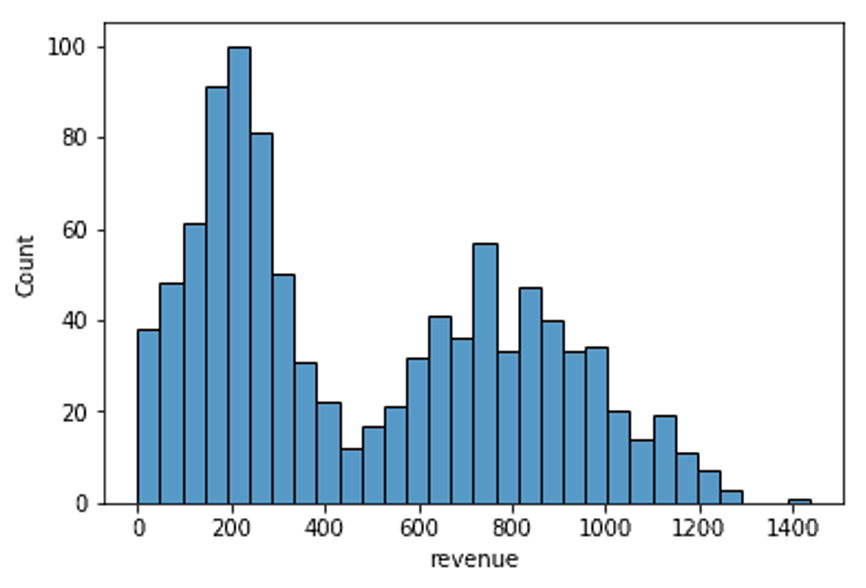
直方圖:針對連續變項較常使用的圖形,可以很快地呈現資料欄位分布的狀況,且能從圖型裡快速讀到重要的統計數值。假設今天想要看公司一年來,訂單金額的分布狀況,就可以把它畫成直方圖。直方圖能統計訂單金額,並切成很多區間,以利我們統計每個區間裡的訂單數量。
一樣是長條形式呈現,直方圖與長條圖的區別為,直方圖的長條間是黏在一起的。因為現在X軸(水平軸)放的是訂單金額這個連續的變項,把訂單收入的直方圖畫出來後,可以很快從圖中得出訂單的金額最小值及最大值的落點與集中的位置。接著,就能依靠自己的專業知識分析為什麼會這樣分佈的原因。
因為很多時候,我們常不知道實際的原因是什麼?這時就能從資料檔本身下手,透過資料檔裡的其他欄位,幫助解釋現在資料的分布狀況。例如,根據訂單記錄中的廠商合作紀錄,可以把訂單分成不同區域檢視協助我們掌握不同地區訂單的狀況。甚至未來如果要更進一步利用手中的資料,進行AI模型的訓練,希望模型幫忙預測訂單成交的金額,讓我們可以選擇哪邊的訂單要特別投入心力。透過直方圖的結果告訴我們,區域這個變項,可能在模型訓練時要納入考慮,幫助電腦做更精準的判斷。
散佈圖:探討兩個連續變項間的關聯性常用的圖表,較適合展示樣本數量比較多的時候,藉此進行下一步的驗證,或是修改之前決策的一些方向。
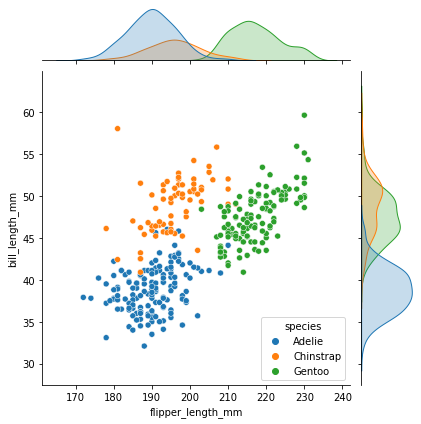
圖說:這張圖是三個企鵝品種的鳥喙長度與翅膀長度的散佈圖(上方及右方為散佈圖繪製而成曲線圖。)。我們利用大量的數據繪製後,可以清楚觀察到三個品種在散佈圖中的位置。但是若數據不夠多,就較難達到此效果。
折線圖:反映的是我們在意的某個變項(通常是連續的變項),隨著時間變化的趨勢。但折線圖同樣會有線條數量不能太多的問題,也就是類別不能太多,線條太多就較難觀察線條間的關係及差異性。
日常生活中常見的統計指標
我們利用圖型了解資料狀態,也可以利用統計量值了解集中趨勢的指標。利用眾數、平均數、中位數,可以很快知道資料大概集中在哪,相對的,也會有離散趨勢指標,可以利用全距、四分位差、變異數或標準差,幫助我們了解目前資料的分散狀況。
現實生活中,更常使用的是「標準差」這個指標,以前面的訂單為例,當公司的決策者認為應該把訂單著重在美洲的訂單上,因為它的平均金額較高。但是,根據標準差得知,這個訂單金額的分布變化較歐洲來得大,如果今天想要多吸收美洲訂單的話,可能也要承擔一些訂單金額會忽高忽低的變化而影響現金流量,這都是做決策時要討論的風險。
偏態跟峰度主要是讓我們了解整個資料的形狀,例如台灣薪資分布的狀況,可能有一些人的薪水收入很高,如果想了解全台灣人的平均收入,那這群人可能就沒辦法代表全台灣人大部分所在的位置,這樣的資料就叫極端值。
利用偏態這個指標,可以反映出這筆資料是不是有極端值的存在。如果有,就可以進一步處理。利用偏態指標,可以很快掌握資料是否有不對稱性的狀況發生;峰度則是能反映資料的集中程度或離散程度,跟變異數及標準差有同樣效果。
最後一個常看的統計量值叫做相關係數,主要是用來描述兩個變項之間的線性關係。如果資料分布不是線性關係,而是拋物線關係,用相關係數就沒辦法幫助回答這個問題,可能就要回到散佈圖本身,把散佈圖畫出來才能幫助了解狀況。實際應用中,也很常使用相關係數快速了解。

在進行AI專案時也可以利用前面介紹的方法。如果希望分類任務模型訓練表現好的話,通常會希望每個類別之間比例差不多;資料裡面如果有極端值,會額外處理。再來,哪些資料有助於我們訓練AI模型?這些都可以用前面介紹的工具來幫助回答剛才提到的幾個問題。
資料太雜亂,分佈在不同地方怎麼辦?
比資料太多還棘手的問題是「資料雜亂」,可能是資料還分散在各個地方,可能是不同部門或資料檔裡,裡面可能蒐集了相似的資料或是重複、不一致的資料等,要怎麼處理?
資料雜亂的其中一個情況是,資料可能分散在多個檔案裡,或不同部門身上。每個部門會根據自己的需求,針對客戶蒐集資料,可能都會蒐集性別、身分證字號、產業……等等。如果各部門是各自蒐集、各自分析,影響並不大,但是,如果是要把資料整併做統整性分析,就可能會發生資料重複蒐集,不同部門資料不一致的狀況,例如變項名稱不一致,或標籤不一致等麻煩的情況,例如有些用男/女做標籤、有些用male/female ,這時就要特別花心力處理。最害怕的狀況是,部門間如果沒有ID欄位對應的話,資料就串連不起來,能做的分析也就有限。這方面的問題,通常要動手解決:將這些編碼訂出來彙整,例如有些公司會建立一個資料的主數據,將各個部門間都會用到的資料彙整起來,做共同的處理,如性別欄。
資料雜亂還有一種情況是,資料欄位記錄不當時會發生的問題。第一個是:「列了不正確的資料」。什麼是不正確的資料?例如,問卷填答錯誤,或是填答者不願意提供真實資料。這種狀況通常很難只看資料表格就發現,所以拿到資料後,要先用圖形或統計值計算,觀察是不是有不合預期的資料發生。這種錯誤資料就可以移除,或當遺漏值處理。當然也能進一步,針對遺漏值做適當的補值方法。
第一種方法也是滿多人會選擇的作法,當資料量很大時,只有一成或是少數幾筆的資料沒有值的話,就會選擇不處理它,留空就好。這種情況在小樣本時較麻煩,因為做分析時就會較偏頗,所以有些人會選擇用眾數,或平均數的方式把資料補上,就可以運用這整筆資料。但這些方法還是遭到一些人詬病,認為填眾數或平均數對分析來講沒什麼幫助,因為還是無法代表真實情況。所以,有些人會再去思考更進一步補值的方法。例如A聽眾沒有填答性別資訊,我就可以試著從剩下那些聽眾的身上,觀察資料填答的狀況,找到其中一個人資料填答的狀況是跟A聽眾一樣的時候,把那個人的性別補到A聽眾身上。這種補值方法,考慮的是樣本跟樣本間的相似性,我們稱作比較有意義的補值,也是現在較多人會採用的方法。
最後一種狀況,就是極端值。如果想要計算全台薪資的平均值,到底要不要把收入明顯高於其他人的樣本排除?有些人會選擇把它移除,計算出的數值較貼近大部分人的狀況。這樣的方法遭到一些人詬病,因為這些薪水收入高的人,也是代表台灣的社會現象,所以不適合拿掉。更適合的作法是把它留在資料檔裡,然後算平均值。在呈現資料的時候,會告訴大家平均值是這樣,但大家可以觀察到資料分布,有一部分的人是收入特別高的,所以在判讀訊息時要特別注意。有時候可能還會把這些有極端值的資料拿去做模型訓練,這時我們會採用對數轉換的方法,特別處理極端值在資料檔裡造成的影響。
如果想從根本解決資料雜亂的問題,讓分析更順利,有什麼方法?整體來說,想解決資料雜亂的問題,就要從資料蒐集前開始做起。可能要考慮資料蒐集的程序,或是重點資料蒐集的方法,例如性別資料如果是在意的主數據,在填問卷的時候,就設定必填等。
其實,現實生活中常發生的狀況是,手上已經有一些資料,但是可能會到想拿來做分析或應用時,才發現裡面有哪些數據少收,或是有不一致的狀況等。既然很難做到在最開始蒐集資料時,就做好通盤考量,那可以做的就是資料治理。針對遇到狀況可以怎麼處理?如何讓後面的人,使用資料更順利?資料治理會牽涉到怎樣確保資料品質及共享性,也就是串聯不同資料,有串聯的必要嗎?還有,是不是要額外區分哪一些人才可以接觸這些資料?可以存取嗎?藉此提高資料安全性。
資料治理的框架還有很多可以考量,除了剛才講的東西,企業如果要治理資料,還可以額外考量一些觀點,像是資料的架構。整個公司需要再特別安排一批人處理資料嗎?無論結果如何,都要有相對應的做法。資料要儲存在哪裡呢?一開始可能放在各自的電腦裡,用Excel儲存。未來可不可以建一個資料庫,將這些資料彙整在一起?不同的人,在存取資料時,是不是要訂定規範?還有利用這些資料做AI模型訓練,最後得到的成果,這些商業機密要如何彙整?這些都是企業在管理資料時,可以考慮的依據。
最後,這些方法不只AI專案,或是資料分析時才能用,而是任何需要利用資料時,都能運用的技巧。因為資料科學是很大的範疇,我們可以利用一些嚴謹的資料科學方法、程序,幫助我們從資料裡面提取出有意義的訊息,將資料濃縮再濃縮,經過處理加工、分析,來回答現實生活中遇到的問題,或是幫助決策。
