
前陣子收到一封演講邀請信,來信的是一位「計算機語言學」的專家,但在信中卻寫了一句「…傳統形式語言學[註1]…」這讓我覺得特別有趣。
若要比年代的話,其實計算機語言學起自1946年的機器翻譯,而喬姆斯基 (Chomsky) 的以數學形式描述的形式語言學研究方法,還要 10 年後,在 1957 年才發表「轉換生成語法 (Transformational Grammar)」[註2]。
這就像是 2016 年最流行的 LSTM (長短期記憶模型) 指著 12 年後的 2022年底才出現的 LLM (大型語言模型) 說「那個是傳統 AI」一樣令人感到時空錯亂。
但凡現象必有原因,為什麼一個「計算機語言學家」會認為「形式語言學」是傳統的?我想了幾天,終於想到一個原因『在 AI 時代裡,計算機語言學家認為形式語言學已經是 Old School 的老東西了!所以才會稱之為傳統!』
但既然我已說明了相較於計算機語言學,形式語言學並不傳統,接著,我就借用 “Linguistics for the Age of AI”這本書的書名,做為本篇的題目,說明一下我們用「形式語言學」怎麼在現代做 AI/NLP[註3] 吧。
基本單位:詞彙 vs. token
在語言學裡,掌管語意計算的最小單位是「構詞 (morphology)」;但在 AI 的眼裡,它無法理解什麼是「詞彙」。AI 的領域裡,模型計算的最小單位是一個 token。
token 不一定是「字」,甚至不一定是一個「詞」。Token 可以是任何電腦可以儲存解析的單位。比如說一個中文字,在 Python2 裡就是以三個 bytes 來儲存。
除非額外說明,否則以下「語言學」的指稱對象都是「形式語言學」。

但從語言學的角度,一個「構詞的單位」是可以和整個句子的語意有所關係的。例如「打破」的「破」表示「這個動作最後造成的結果狀態」。而呈現一個句子意義的方式,是透過其句法結構逐層計算而來。
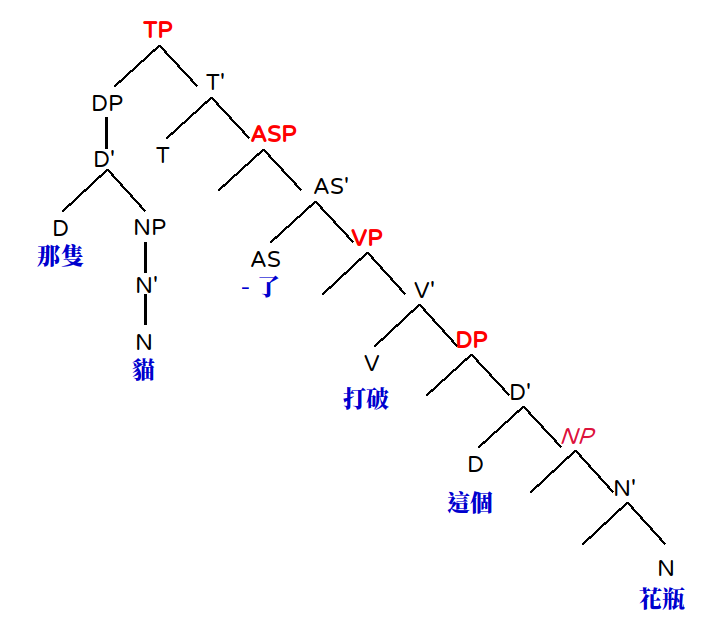
而且在這個架構下,我用紅色字體標出的每個 XP (TP, ASP, VP, DP, NP…) 都可被視為是某一種程式裡的函式 (Function,請特別注意這個字!),只需要給予它需要的論元 (arguments) 就行了。一段用以表示概念的 psudo-code 可以是像這樣:

由於這個語言的 VP 是 head-initial (中心語在前) 的,所以當 VP 繼承 XP (class VP(XP) 這行) 的時候,不需要另做調整。而這個語言的 NP 是 head-final (中心語在後) 的,所以當 NP 繼承 XP (class NP(XP) 這行) 的時候,需要在 __init__() 裡設定它不是 HeadFirst 的參數[註4]。
於是,我們就能完全基於形式語言學的句法規則,來撰寫程式該怎麼處理句子。取出句子裡在句法樹上的每個元素,然後就能轉為形式語意 (Formal Semantics) 的 labmbda abstraction 的邏輯式,再進行語意計算了。
這時,下一個合理的問題就會浮現:正如大型語言模型都有「訓練」和「推論」兩個階段。上面的 psudo-code 既然類比的是「推論」的使用階段,那麼一開始究竟是怎麼得到 inputSTR 裡的這些標記結果的呢?
這又要回到「傳統 NLP」(這裡真的可以用『傳統』一詞) 處理高頻詞的想法和形式語言學的差異了。
傳統 NLP 是從訊號處理的角度出發的。因此很在意熵值的變化。他們覺得「只要某個東西的出現次數太多了,它就應該像背景雜訊一樣,數量多,而且變化多端。只要把它們濾掉,排除,剩下的就是我們要的訊號了。」
但從語言學的來看:「這個元素一直出現,必然有什麼特殊的原因!」
以下我們可以從某個詞彙出現次數繪製的長條圖裡,看出這兩種不同對待語言的態度:
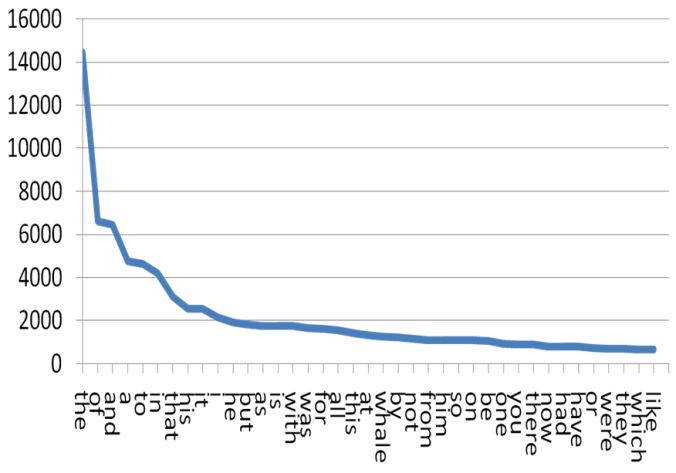
這張圖呈現的是某語料經統計後的結果,出現次數最多的詞彙往左排,次多的排第二,第三多的排第三,依序往右排。所以這張圖表裡呈現的就是「本語料中,"the" 出現的次數最多,"of" 出現的次數次之,"and" 第三…依序呈現」這種分佈被稱為齊夫分佈 (Zipf’s distribution) 或是也有人稱語言中詞頻的分佈會遵守齊夫律 (Zipf’s law)。
如果你是受傳統 NLP 出身的訓練,那麼你下一步會處理它的方式就是所謂的「去除停用詞 (stop word removal)」
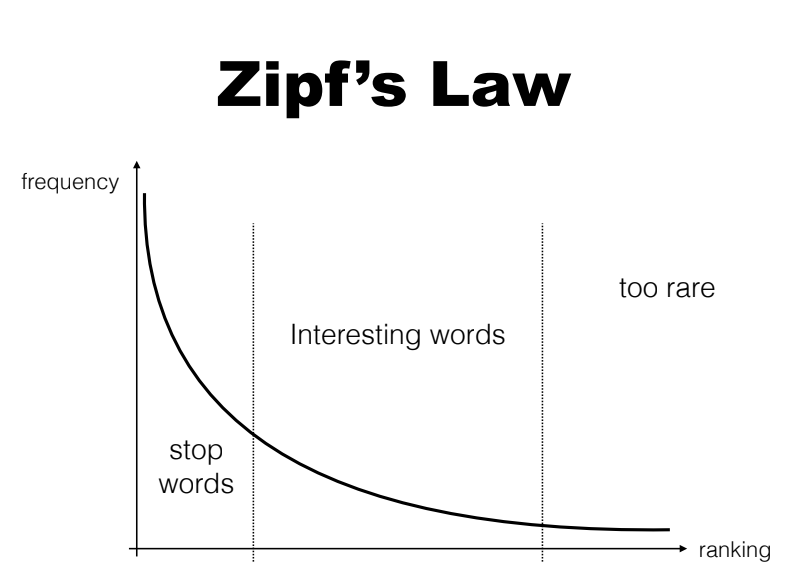
也就是把出現次數最多的那幾個詞,當做是「高頻詞」,然後把它當成是「就像出現次數又多,種類又變化多端的雜訊」一樣去除。然後只取後面的 “interesting word” 來當做實義詞 (content word) 使用。
但語言學並不是從這個角度理解這個現象!
語言學從「人類幼兒如何從極少的資料裡,就能掌握自己身處的母語環境中,究竟要把 HeadFirstBOOL 設為 True 還是 False」這個角度出發。從這個角度來思考,我們馬上就能注意到「這麼多高頻詞,怎麼剛好都是 Function word 呢?」
因為 Function word 可以快速地幫助人類幼童決定他正在「習得 (acquire)」的這個語言,要怎麼設定參數,以便快速地用最少的能量 (他每次的能量補給只有幾 c.c. 的母乳,而不像大型語言模型一樣有三個州的電網系統可以提供能源),在最少的例子裡聽出來「什麼東西一直反覆出現,那就先把它當做是句法樹上那些紅色的節點。優先釐清它的參數設定 HeadFirst (中心語在前) 還是 HeadFinal (中心語在後)」。
就依這樣的步驟,我們實際觀察一次這個比較少台灣人熟悉的語言:

如果把它依前例畫成每個詞出現的次數的話,就會發現第一多出現的字就是 “di"!讀者應該可以想像,人類幼兒聽到很多次的 "di” 以後,接著會發現它是前面的東西變化比較少,還是後面的東西變化比較少。如果是前面的東西變化比較少,那就表示它和前面那個東西的關係比較緊密,所以它是 “HeadFirst=False” 的參數設定;相反地,如果它後面的東西比較不會變化,那麼它就是和後面的東西關係比較緊密,這麼一來它就是 “HeadFirst=True” 的參數設定。
除了這個 HeadFirst 的參數設定以外,我們還會注意到「所有能扮演 Function 的元素,都是有限的數量」。比如說英文介系詞就少少的那幾個,中文的更少 (e.g., 在、於、之、的…等)。換言之,人類幼童根本不需要有那麼多的訓練語料,他只需要掌握住「那些常常出現的高頻詞,各自是屬於要往前併成一個 XP 的類型,還是往後併成一個 XP 的類型」就可以了。
於是「那隻貓打破了這個花瓶」,就可以很快地被以下的步驟逐層解析並加上標記:(我用 -> 和 <- 來表示它是往哪個方向併成一個 XP 結構,並用 [ ] 標出已經併起來的單位)
- 那(->) 隻貓打破了這(->) 個花瓶
- [那隻] 貓 打破(<-) 了(<-) [這個] 花瓶
- 那隻 貓 [[打破]了] 這個 花瓶
- 再加上我們知道具有 Syntax Function 的功能詞只有那幾類。就能標上:
- [DetP[Det 那隻] [N貓]] [VP[V打破]了] [DetP[Det 這個]花瓶]
走到步驟 5 的時候,一個可以被 Formal Semantics 的 Lambda Abstraction 接手進行語意計算的句法樹標記就做好了。這 5 步,就相當是對應現在大型語言模型的「訓練」階段。只是我們用語言學的方法是用演算法來做,而不是用資料模型來逼近。
簡言之,我們不需要大量語料,不需要像 1950年代的 Pre-Chomsky 的『真.傳統語言學家』去編寫每個詞彙的文法,列舉每個例子,就能模仿人類幼童學會語言的句法結構和參數知識的方式,用語言學來做 NLP 了。
我們的 Articut 就是這麼做的。在中文上做了一次,在英文上做了一次,還正在排灣語上再做一次。我們一次又一次地做,就是為了證明「這種方法是可行的,而且即便是語言類型學上非常不一樣的語言,形式語言學的方法,在 AI 時代裡也是可行的,而且我們還非常省能源,又不需要大量語料呢!」
而且,由於我們的演算法是貼著 X-bar 做的,所以我們的各種應用也等於是提供了形式語言學家 (或是生成語言學家) 一個「可以透過資訊工具大量測試和觀察語言現象」甚至「將理論實作成應用」的研究平台了。
本文取得《卓騰語言科技 - 科普分享空間》授權轉載,原文詳見AI 時代的語言學 - 連載之一
註 1:形式語言學的英文是 Formal Linguistics. 其中的「形式」一詞,指的是指使用定理或公式解,來說明並建構知識的邏輯系統。這種研究方法又被稱為 Formalism,中文被譯平「形式主義」。
但大概是近 30 年來的兩岸開放交流,台灣吸收了許多中國詞彙和語意的解釋。而中國使用「形式主義」這四個字的時候,更像是官僚主義的那種只看事物的現象而不分析其本質的思想方法和工作作風。
於是乎…莫名奇妙地開始有些剛接觸語言學的學生就帶著「中國風味的形式主義」來理解 Formalism 的 Formal Linguistics 的中文譯名「形式主義語言學」了。
不過還好,Formal Linguistics 裡研究句法的分支,通常又被稱為 Generative Syntax,而中文常被譯做「生成語法/生成句法」。這個字眼就持續維持中性,直到 2022 年底的大型語言模型,又把這個字拿去放在「生成式 AI」的 Generative AI 裡。
於是乎,又有許多「先看到生成式 AI,才看到生成式語法」的人,以為『你們這些語言學家就是在蹭 AI 的熱度哦!』
註 2:簡單的年表如下:
- 1956 年 達特矛斯會議:第一次冒出 “Artificial Intelligence (AI)” 這個字眼,當時的語言學是傳統的 Rule-based 語言學。
- 1950 年代,意識到 Rule-based 語言學無效,因為規則寫不完,因此開始了 Computational Linguistics (計算機語言學) 和 Corpus Linguistics (語料庫語言學) 的發展。前者企圖用某種知識圖譜、人為標記做出統計機率模型,後者企圖採集『具代表性』的語料,以避免資料量太大的時候,描述規則會寫不完的問題。兩者都是為了「解決 Rule-based 的不佳」而開始的領域。
- 1957 年 Chomsky 出版他的第一本關於語言的專書,他是在荷蘭出版的,因此對美國的影響並不那麼立即或明顯。
- 1965 年 Chomsky 出版他的第二本關於語言學理論的專書,這本是在 MIT 出版社出版的。
因此…誰更「傳統」?這個問題的答案,似乎不言而喻。
註 3:較明確的說法應該就是 NLP 而非 AI。但在 LLM 出現以後,大家似乎漸漸把 “AI” 一詞能指涉的範圍變得更廣了,只要是能通電的,都能冠上 “AI"。因此,為了讓文字閱讀時遇到陌生詞彙的費力感降低,本文裡的 AI 其實就只專指 "NLP (自然語言處理)” 的相關技術與應用。
註 4:psudo-code 的意思是「它並不是被期待成可被直接執行的程式碼,而是用以表達概念或是演算法核心的偽碼」。甚至連這段程式碼裡的 regex 都不該使用才對,而「這裡的 NP 還需要做一些調整,才能正確地使用」我知道,但這就是用以表達概念的 psudo-code 而已,它本來就不是要被執行的,而是被用來理解的概念的。
有些不熟悉 Formalism 或 Programming 的人,會對這段 psudo-code 提出諸如「回傳的結果是錯的,我用另一個句子就會得到錯誤的結果」或是「這個程式根本不能動」的質疑。這個註解就是寫給這些人看的。


