本文旨在尋找一種方法,能有效地結合局部與全域特徵,提供模型更全面的資訊。為此,我們將介紹一種專門設計來整合這兩種特徵的新型 CNN 模型,稱為 Global Local Mixture Network(GLMNet)。
「局部特徵」與「全域特徵」誰較重要?
CNN 發展至今逾十年,從最基礎的 AlexNet 到目前複雜度極高的 Transformer based 的模型,對於「局部特徵」與「全域特徵」的重視程度也出現改變。
過往認為局部特徵對圖片具有極好的正向關係,這也是 ConvNet 能在圖片任務中佔有一席之地的原因;不過,Transformer 在 2020 年後侵襲 CNN,使得整個圖片任務的世界觀也隨之被打開。研究者發現,圖片的局部特徵並不是唯一;全域特徵也極為重要。甚至有學者說到,全域特徵才是執行好圖片分類任務的本質。
本文想探討的是,如果兩種特徵方式都很重要的話,有沒有一個方法能同時有效地傳遞局部及全域特徵給模型,使其同時查看局部及全域特徵。這篇文章將介紹,如何搭建一個整合局部與全域特徵的 CNN 模型,我們稱它為 Global Local Mixture Network(GLMNet)。
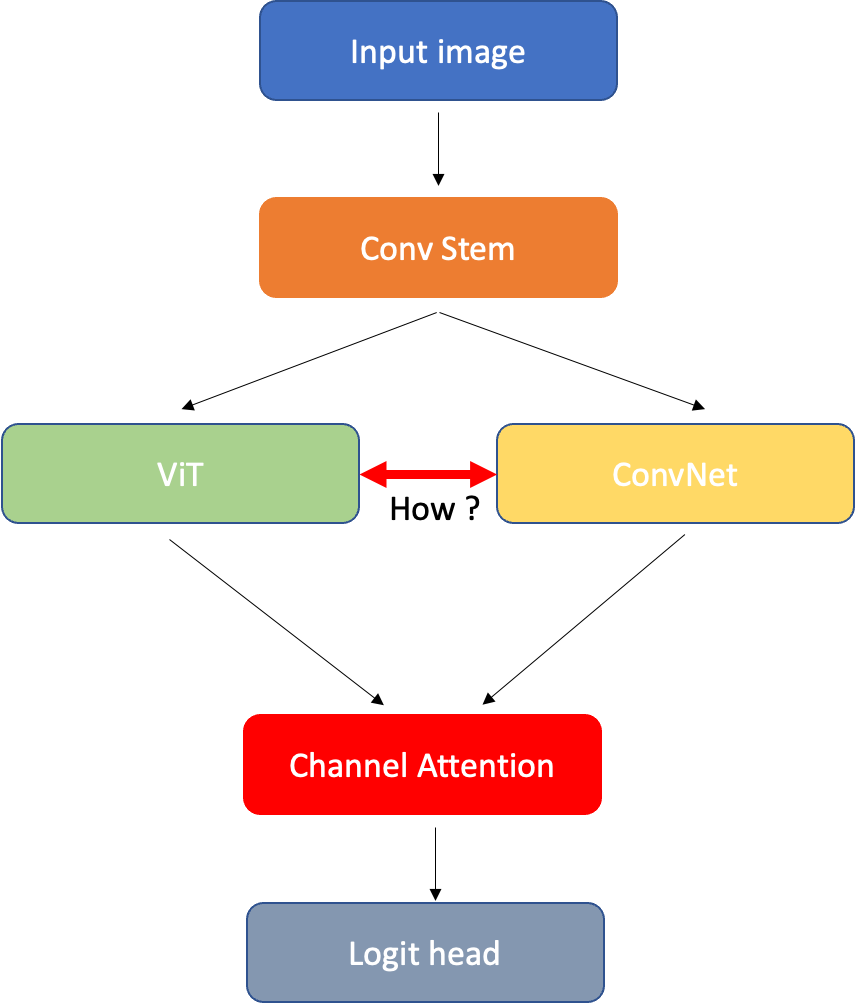
首先,可以看到圖一的模型架構,從最上面的圖片輸入開始,Conv Stem 會先將原圖降維度,然後找出最初始的淺層資訊,以往常見的做法是利用一個較大的卷積核,如:(7,7)以及稍大一點的 stride(4)來做。
中間的兩個方塊所呈現的就是重頭戲,左邊的 ViT 就是 Vision Transformer based 的模型;右邊的 ConvNet 就是 CNN based 的模型,我們的目標就是整合兩邊的資訊,使其互相傳遞,並在後續輸出分類前,能更了解圖片的特徵。
Channel attention (紅色部分)能將兩種特徵中最重要的部分取出,找出並省略相對不重要的特徵,避免因為每張特徵圖的資訊重要度都一樣,而對最後的分類產生不好的影響。以下我們會依序介紹 Conv Stem、局部與全域網路的整合、channel attention 三個部分的做法。
第一步:Conv Stem
在 Conv stem 中,最重要的就是將最開始的細節特徵,有效地傳遞到深層網路層中,所以這部分細節的好壞會決定後續深層的提取結果。在 Transformer 的模型中,通常 Conv stem 都會將此層的圖片特徵切成 patches ,如圖 2 所示,也就是將圖片切成 N 等分的意思。這樣做主要是為了讓 Transformer 的模型能對應出 patch 與 patch 之間的關係,也能知道對整張圖片而言,哪個 patch 相對重要。為了讓後續的 Trasformer 及 ConvNet 都能有效地拿到特徵,所以我們這邊也使用 patchify 的做法。ConvNeXT 的論文中提及,在 Conv Stem 中做 patchify 確實是能有效提升準確率的一個手段,如圖 3 就是一個簡易將卷積做成 patchify 的做法,這裡是使用 pytorch code 為例。


第二步:Vision Transformer 及 ConvNet 的整合
這邊先簡單的介紹 Vision Transformer 以及 ConvNet 。 Vision Transformer 是西元 2020 年所發表的圖像分類模型,在這篇論文發表前,與圖像處理相關的深度學習模型都是以卷積神經網路為主。
卷積神經網路最厲害的地方就是局部特徵提取的能力,這也是 Convolution layer 的貢獻;但在西元 2017 年後,語言模型有了極大的突破,從當時 BERT 到目前最熱門的 ChatGPT,都是因為 Transformer Model 的幫助;學者們也發現到能把 Transformer 的技術放入圖像的世界。
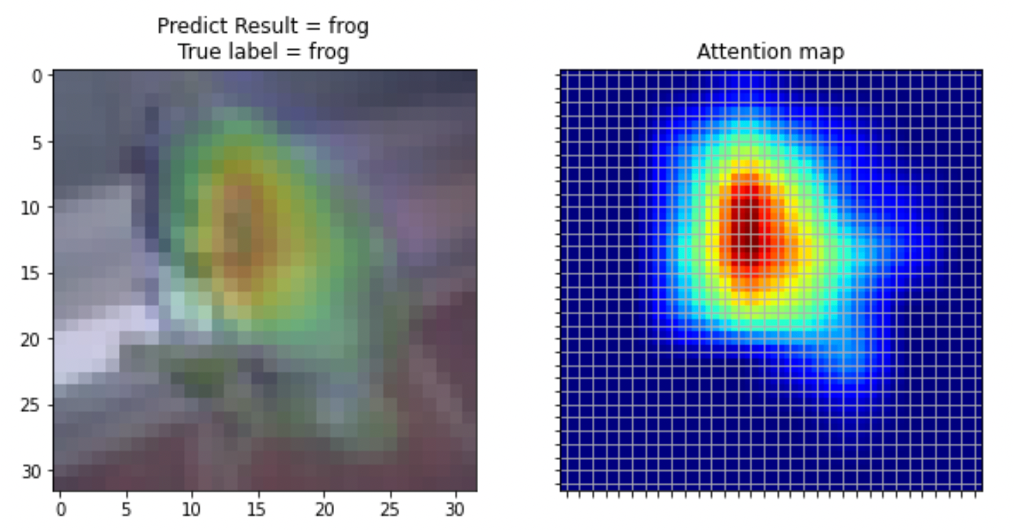
Transformer 究竟有什麼迷人的地方呢?就是能在整張圖中,看到哪些地方較重要,哪些地方相對不重要,也就是說,我們可以得到整張圖之間的全局關係。若認為聽起來很複雜的話,可以直接看一下圖 4 以及圖 5 的差別。
圖 4 與圖 5 分別是以普通的卷積神經網路,與 Transformer based 的網路訓練後所出來的模型解釋圖。可以看到圖 4 的 CNN 雖然能找出青蛙的基本位置,但沒辦法完整描繪出青蛙輪廓,這可能導致分類上的誤判。但在圖 5 的解釋圖中,可以看到青蛙的輪廓被完整地描繪出來,使其在分類上有機會將青蛙與其他類別區隔得更開。而 Transformer 就是擁有這種全局性的特質,才能將圖片有效的找出輪廓特徵。

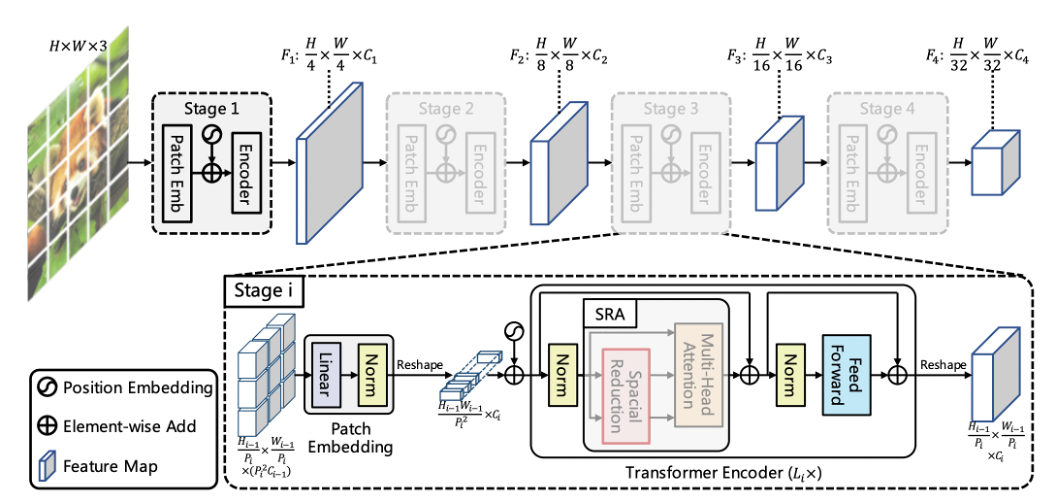
簡單描述完 Transformer 的特性後,接著說明這次使用的 Transformer 模型,這次使用 Pyramid Vision Transformer V2 做為我們的 ViT 模型。選用此模型架構的原因是,在原始版本的 ViT 中,圖片從模型入口到模型出口的過程中,在找特徵的過程都不會有 down sampling 的做法,使得圖片大小都一樣。但在 ConvNet 中,隨著模型的深度變深,找的特徵越全面時,圖片將會慢慢縮小,這樣的做法除了降低硬體資源,也使特徵萃取的更精確。
模型架構如圖 6 所示,總共會有 4 個 stage,每個 stage 會做 N 次的 Transformer encoder ,值得注意的是,每經過一個 stage,圖片的維度都會發生改變,特徵圖會越找越多,然後圖片會越縮越小。此處的 stage 也會跟後面的 ConvNet 進行整併,因為 ConvNet 也會有 4 個 stage,目的是讓每個 stage 間都能有 feature map 的溝通。
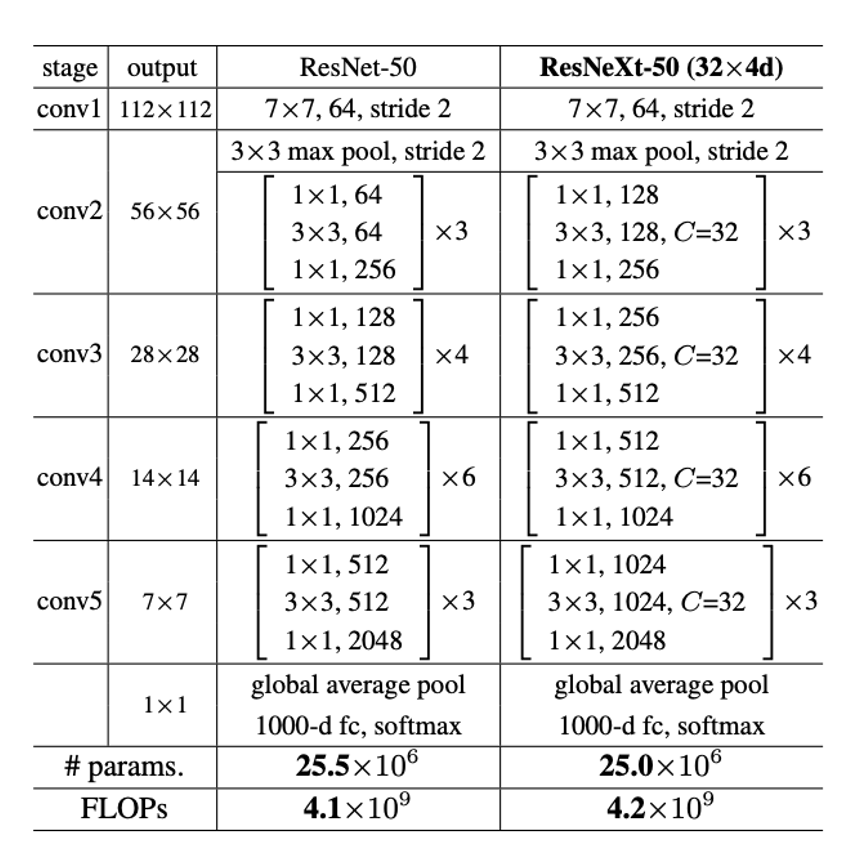
ConvNet 模型中,我們使用 ResNeXT 50 作為基底模型,此模型是 ResNet 的加強版本,主要多了一個 group convolution 降低參數量,在降低參數量的同時,也能增加每一層 feature maps 的數量。相較於原始 ResNeXT 50,這邊只微調一個內容,那就是將原本使用 ReLU 激活函數改成 FReLU 。
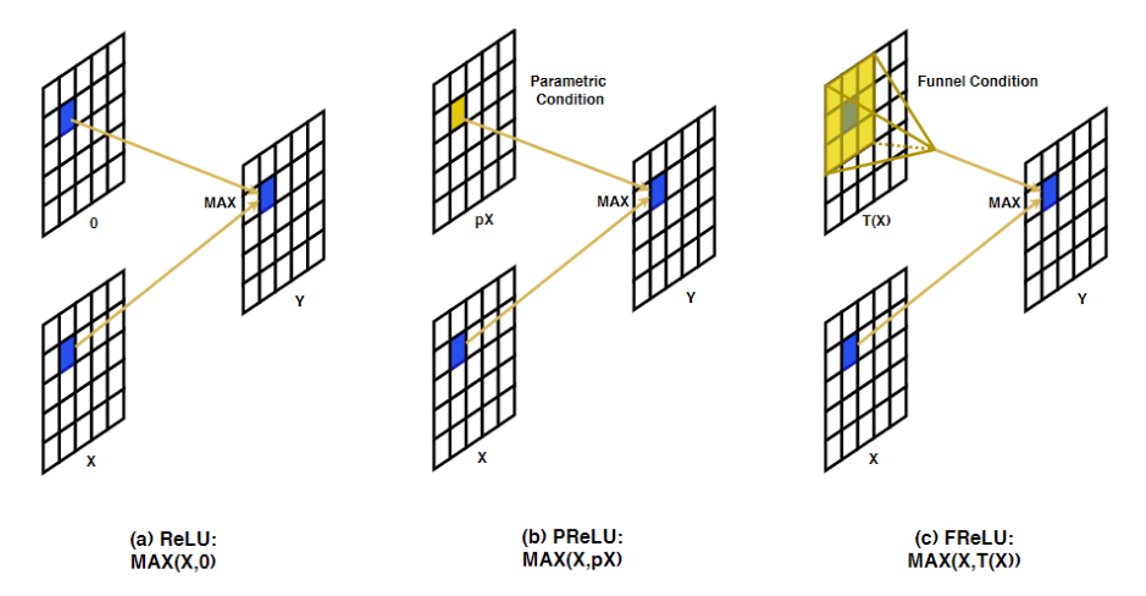
圖 7 為 FReLU 激活函數的示意圖,主要是在進入 max(x, t(x)) 中,原本是指取得正數以上的值,現在是會額外對 x 做卷積,目標是要用卷積找到空間上下文的特徵關係,這也是專門用在電腦視覺的激活函數。
ResNeXT 模型架構如圖 8,模型中的 conv1 指的是 Conv stem 的結果,而 conv2 - conv5 分別是 4 個 stage。每個 output 則是當層 stage 做完的圖片大小。我們要提取的是 conv2、conv3、conv4,及 conv5 做完的特徵圖結果,並將這些資訊與 T ransformer 的每個 stage 進行對應。
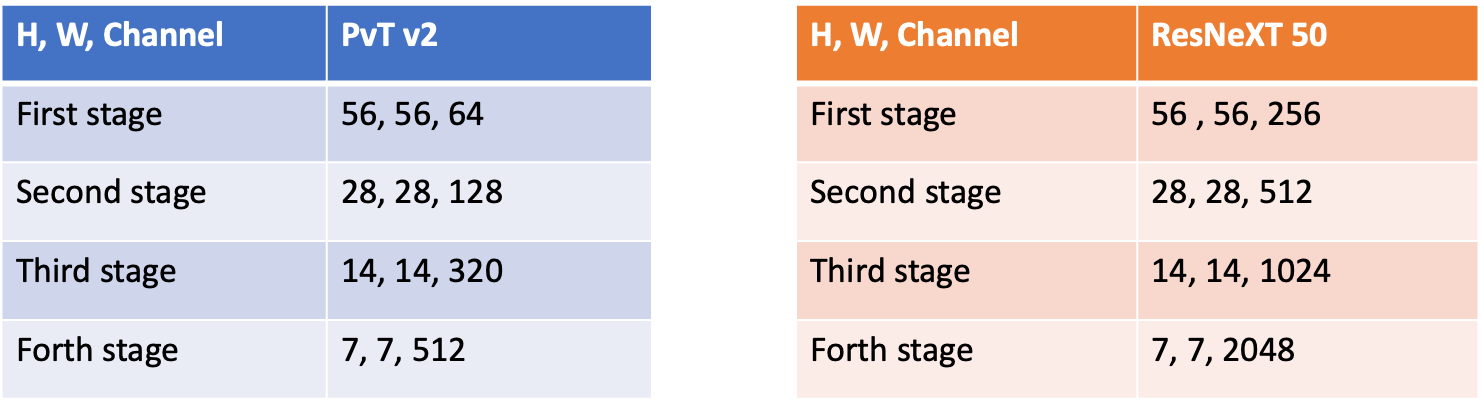
有了全局及局部模型後,接著就要進行整合了。首先,可以看到圖 9 分別是兩個模型在每一個 stage 輸出的維度,此維度的意義分別是(圖片的寬,圖片的長,有幾張特徵圖)。可以看到圖中每個 stage 的長與寬恰好都是相等的,大大增加了我們利用此維度的機會。
最需要討論的是,該如何合併這兩者的特徵圖,這裡有兩種做法,一是直接將特徵圖的每個 pixel 相加(如同 Residual Net 的 Skip connection 做法),但前提是特徵圖的資訊數量也要一樣,如果強行用一個(1,1)卷積來提升 PvT 的特徵維度或降低 ResNeXT 50 的特徵維度都很危險,因為無法得知哪些特徵可以在這裡被省略。因此,最終所使用的方法就是直接將特徵圖都 concat 起來,拿 First stage 為例,我們將 64 張特徵圖的全局網路加上 256 張圖的局部網路,使其變成 320 張特徵圖,如圖 10。
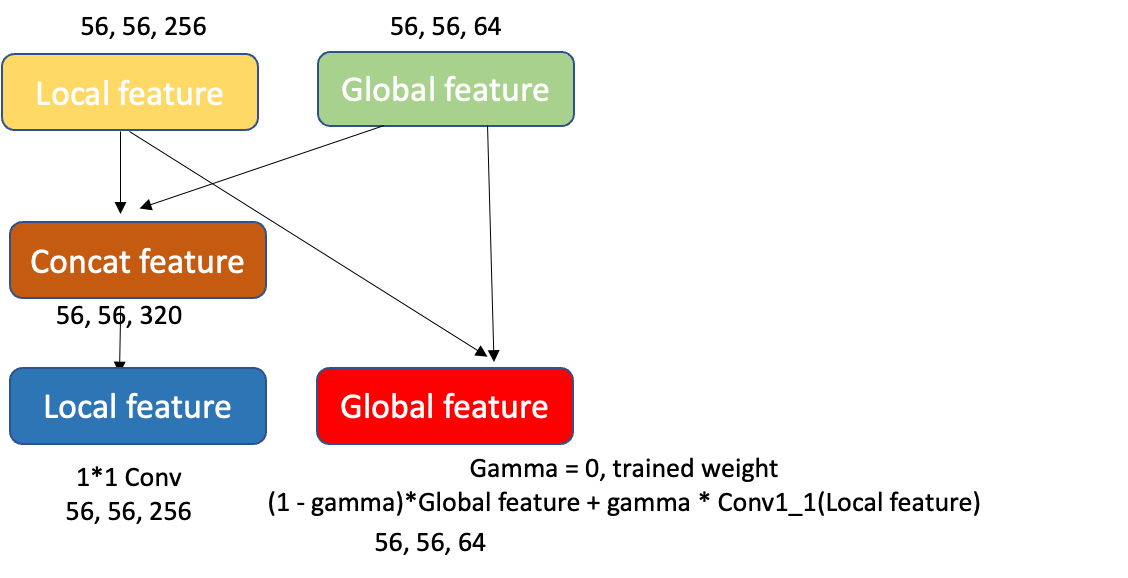
在 Concat feature 後,接下來就是如何分別將整合好的特徵還原至局部特徵網路及全局特徵網路。在局部特徵中,我們直接把 concat feature做(1,1)卷積,把特徵還原回(56,56,256),然後再放到局部網路的 stage2 下去做訓練,此時的局部網路其實已經參雜了一些全局網路的資訊。由於局部特徵網路只有利用到 convolution layer,所以其實學習成本相對比較低,模型在訓練的複雜度會小很多。但是如果要丟回給全局網路的話,難度就會很高,因為裡面參雜著局部特徵網路的結果,但是這些局部網路特徵都只有局部性的資訊,如果直接都給全局網路做訓練,會導致網路在更深層的地方找不到好的全局點,使得梯度無法下降。
所以在 Global feature 的部分,我們定義出一個公式:
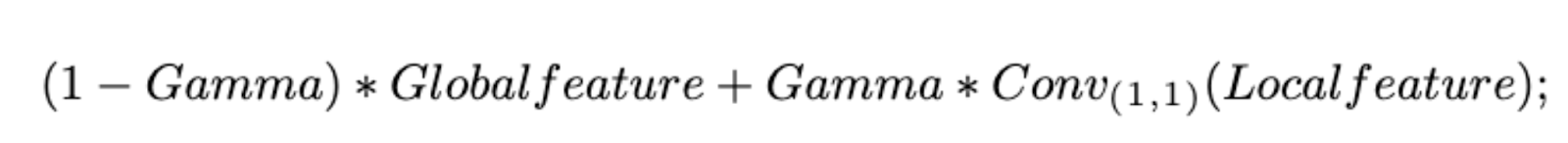
此處的 gamma 是一個可訓練的參數,預設為 0 ,另外 Conv1_1 則是(1,1) 卷積的意思。一開始,在梯度還極度不穩定時,如果 gamma 為 0 的情況,就是不讓 local feature 加入到全局網路中,但隨著 epoch 數量變多,梯度變緩的時候,gamma 值就會開始提升,這時候可以想像 local feature 其實已經有一個不錯的特徵結果了,這個時候就能傳遞給全局網路,使其也有一點局部網路的特徵,到了這個時候,就能順利的讓全局以及局部網路都擁有互相的特徵關係了。如圖 11 ,就是我們簡單的 pseudo code。

第三步:在分類層前的特徵圖注意力
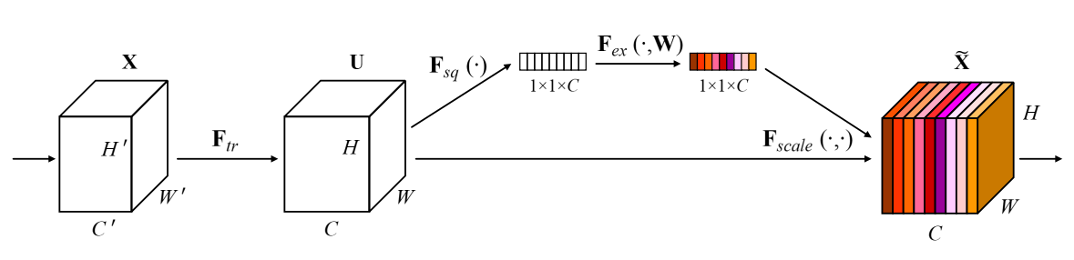
前一步已經完成兩者網路間的整合,最後一步就是去找出哪張特徵圖比較重要,哪張特徵圖較不重要。要能有效找出特徵圖的重要性就可以使用 SE Net,圖 12 是 SE net 的模型架構圖。這裡想要說明的就是原本特徵圖跟特徵圖是沒有關係的,但經過了一個 F(x),可以看到右邊的特徵圖會有顏色關係,越深代表此張特徵圖越重要。可以知道 SE Net 做的事情就是分別給每張特徵圖一個權重,越重要的權重越高,越不重要的權重越低,這樣就能知道特徵圖的關係了。
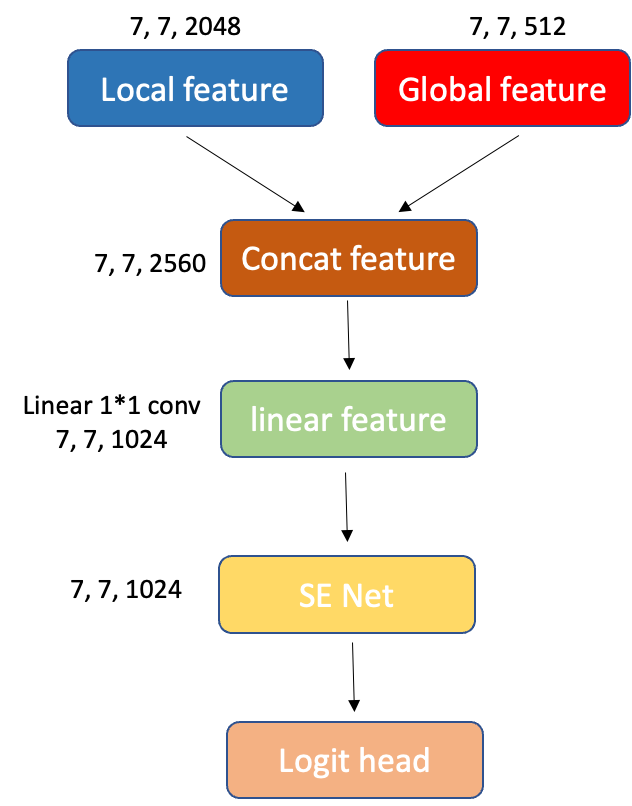
最後將 Local feature 及 Global feature 的 stage 4 結果算出來後,就會先將兩者的特徵都 concat 起來,然後經過一個(1,1) 卷積後就進入 SE Net 給特徵圖關係,最後就要進行分類任務了。
實驗
我們利用 kaggle 上的公開圖片資料集進行測試,該資料集總共有 6 個標籤,分別是 mountain、 Glacier、Street、Sea、Forest 以及 Buildings。訓練集有 14,034 張圖片,測試集則有 3,000 張圖片。實驗會採用此資料集是因為綜觀這些分類項目,都需要看到相對較為全局的資訊才能理解此物件的類別,而不像車子或狗等屬於較為局部的物件分類。

訓練的機制則放在圖 15 中,在測試的每個模型中,皆使用此訓練機制作為訓練方式。基本上這些訓練機制都是近幾年常見的訓練機制,如:learning rate 的 warm up 與 scheduler,資料擴增使用 cutmix 等。

下表呈現實驗結果,Init weight 代表沒有使用任何資料集做過 pre trained,直接訓練的準確率結果,Pre weight 則是先利用 ImageNet 事先做 pre train 再對此資料集finetune 得出來的準確率結果。從結果圖可以看到基本上先前的 ConvNet based 模型準確度都是在 90% 以下,需要經過 ImageNet pretrained 才能有比較好的結果,而 Transformer based 可以在 Init weight 有稍好的表現,但依舊不夠強悍。最後可以看到我們的 GLMNet 在單純 Init weight 的情況下準確率已經來到 93.4%,比起其他模型有著蠻明顯的差距,從這個資料集也能得出,在兩者的特徵資訊互通的情況下,確實能顯著提升準確率。

結論
局部與全局的特徵共享在一些圖像相對複雜的場合上,能有效提升結果,但也需要較龐大的計算量,所以如果今天的場域相對較為簡單或特徵明顯為局部時,可以先試試看計算量較低的模型,如果效果較不好可以再試試這種方法。至於有沒有同時擁有局部與全局共享,又能有效的降低計算量的方式呢?後續我們將針對此問題改進的 GLMNet V2 的版本進行討論。
(撰稿工程師:廖柏瑜)
參考資料
- https://arxiv.org/pdf/2010.11929.pdf
- https://arxiv.org/pdf/2102.12122.pdf
- https://arxiv.org/pdf/1611.05431.pdf
- https://arxiv.org/pdf/2201.03545.pdf
- https://arxiv.org/pdf/1706.08098.pdf




