
對 AI 工程師來說,Apple 處理器上特別的 16 核心神經網路引擎(Neural Engine)帶來了顯著的速度提升,且在手機端的執行速度也有不錯成效。本次,我們將針對「模糊化背景」的情境進行實地測試任務。
一、前言與任務說明
前陣子我們曾經分享過Apple公司的16核心神經網路引擎(Neural Engine)在神經網路計算上的精彩表現(可參考:利用PyTorch Lightning與CoreML實現在Apple神經網路引擎進行加速運算),那麼,利用這個神經網路引擎進行電腦視覺任務的效果是否同樣亮眼呢?
這次的挑戰是「模糊化背景」下的影像切割任務,也就是當我們參加線上會議,在開啟視訊鏡頭時會選用的模糊化背景,本篇文章就是要與大家分享如何實現這個任務,且只要準備對應的資料就可以針對特定人物客製化。
本文跟上一篇文章一樣,以Python調用Neural Engine的方法為主。
這次所挑戰的影像切割(Image segmentation)任務,也是很常見的電腦視覺任務之一,大多會應用於以下場景:
- 醫學影像:在醫學領域,影像分割可用於標記和定位組織、器官或腫瘤。它能幫助醫生更準確地診斷疾病、規劃手術,並監測病情變化。
- 自動駕駛:在自動駕駛車輛中,影像分割可以幫助車輛識別和理解路面環境,識別行人、車輛、交通標誌和道路邊界等,以做出更明智的行駛決策。
- 地圖製作:影像分割可以應用於地圖製作中,識別並標記建築物、道路、河流等地理要素,以幫助建立高精度的地圖資料。
- 工業應用:在工業領域,影像分割可用於檢測製造缺陷、分類產品和監控生產過程,以提高生產效率和品質控制。
前期準備:
資料集準備大約2000張,本次實驗使用Nvidia GPU完成模型訓,並以M1 Mac Air 進行 inference,文末附有GitHub連結,爾後範例皆以GitHub內容為主。
GitHub : https://github.com/GuffreyKu/image-segmentation.git
本次使用設備:
- Mac Air M1 : CPU 8 核心、GPU 8 核心、Neural Engine 16 核心、16G RAM
- Desktop : CPU 16核心、 GPU Nvidia 2080 Ti 11G、16G RAM
二、環境配置
開發環境大致與這篇文章相同,需要安裝Homebrew、Miniforge、Conda、Pytorch、coremltools、pandas、imgaug、torch-optimizer。(註:此任務新增加 imgaug 與 torch-optimizer 套件)
- imgaug : 用於資料集增強。
- torch-optimizer : 有收入比較近期新的 optimizer 演算法。
三、資料集準備與說明
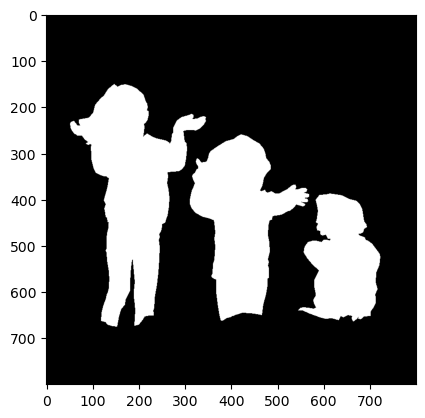
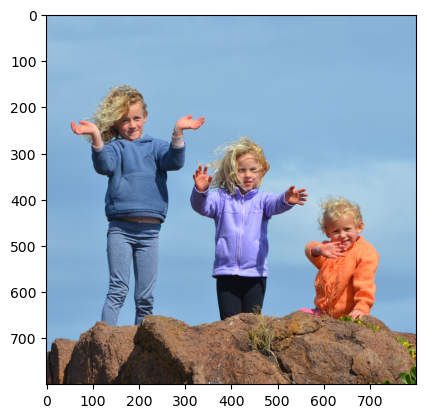
本次使用的資料集一共有2667張圖片,圖片標籤分為「主體」+「背景」,如下圖一所示,白色部分是「主體」,黑色部分為「背景」,模型會利用這個資料集辨別出主體與背景各自是哪些區塊,並針對背景進行模糊化以完成此任務。(註:資料集來源請參考:https://www.kaggle.com/datasets/tapakah68/supervisely-filtered-segmentation-person-dataset)
四、訓練流程
1.Data preprocessing
因為本次使用網路上的公開資料集,所以必須做一些下述的檢查和資料閱讀,包括圖片數量、長寬比分佈,以大致了解資料的樣貌。
- 需確認每張圖片皆可以開啟。
- 需確認輸入圖片與label數量一致。
- 對所有輸入圖片長寬取均值,用於後續訓練圖片縮放尺寸。
- 切分訓練集與驗證集,並將圖片路徑儲存為CSV。
詳細操作可以參考 “ train_python/datasets/data_prep.ipynb ”
2. PyTorch Dataset
透過Pytorch Dataset收集與讀取圖片資料,且定義每次訓練時,所輸入的資料與標籤樣貌,包含輸入資料的尺寸與資料增強方法。
首先,讀取在Data preprocessing階段產生的CSV檔。
接著,圖片使用OpenCV 讀取,圖片通道是BGR轉換至RGB,進行Resize。
在 ImgAugTransform() 中完成資料增強,一共有5種增強方式(亮暗度、模糊、左右反轉、旋轉、位移),特別要注意這次任務是 Image segmentation,它的輸出與輸入大小相同的,label當中某些位置是屬於主體,所以當資料增強使用到像素點位移,如上下反轉、左右反轉、旋轉、位移,label時,皆需同步位移,而這次使用的套件是imgaug,並支援同步移動。
註:這裡使用 Random 的方式每次隨機取一種資料增強方法
3. PyTorch Training Flow
透過PyTorch data loader讀取上一步驟所產生的PyTorch dataset,以進行模型訓練,因此,這一步需要明確定義使用了哪些模型,以及一些訓練技巧。(註:Transfer learning model請參考:classical_seg.py)
這次的實作我們選用兩個PyTorch官方有提供的模型架構,如下:
- deeplabv3_mobilenet_v3_larg
- lraspp_mobilenet_v3_large
(註:PyTorch官方模型介紹 : https://pytorch.org/vision/stable/models.html)
以下說明不同模型架構的訓練方式:
(1)deeplabv3_mobilenet_v3_larg
Google 提出的 Deeplab v3 是在影像切割任務當中表現非常好的模型結構,其中模型backbone使用Mobilenet是因為想要在mac上能有比較快的運算速度,如果不在意運算速度可以選用效果最好的 Resnet101。
因為官方模型使用的COCO_WITH_VOC_LABELS_V1資料集做訓練,輸出層類別數與此次任務不同,所以需要在這個模型最後一層進行修改,同時 deeplabv3 有auxiliary classifier 的功能在這裡的輸出層也需要修改。
(2)lraspp_mobilenet_v3_large
Google 提出Lite Reduced Atrous Spatial Pyramid Pooling (LRASPP) 針對Mobilenet v3的激勵函數與解碼器結構進行改良且加入Network architecture search 優化整體模型結構,使得運算速度與準確度皆有所提升。
同理Deeplabv3,官方模型使用的COCO_WITH_VOC_LABELS_V1資料集做訓練,輸出層類別數與此次任務不同,所以需要在這個模型最後一層進行修改,lraspp在計算分類的類別時有分粗類別與細類別,可以輔助模型訓練,但這次任務沒有這樣的標注方式,所以在模型設計統一修改成兩類。
Automatic mixed precision(自動混合精度計算)(編按:Nvidia 顯示卡才有支援此功能,位置請參考:trainer.py)。
- 模型運算時可以混合FP16、FP32 兩種精度,主要減少訓練時記憶體的使用量,且加速計算。
- 使用pytorch 內建函式,在訓練過程,模型計算、Loss 數值與梯度更新需要特別修改。
4.Trace Torch Model(trainer.py)
- 將模型做靜態轉換,方便後續應用於其他工具與其他平台中。
- 需要注意在做轉換的時候需要輸入與之後應用相同大小的Torch Tensor,此 Torch Tensor也需要符合模型輸入尺寸。
五、模型轉換(pt2ct.py)
為了使用CoreML 必須須將Torch model 轉換至CoreML model。
- 給定模型輸入尺寸,定義輸入名稱與輸出名稱。
- 因為訓練過程使用CUDA訓練,如果在沒有CUDA環境下需要載入模型,像是Mac環境,載入模型需要先以CPU載入(map_location='cpu')。
- 設定模型計算精度為FP16(compute_precision)。
- 設定計算單元,必須為ct.ComputeUnit.ALL才能調用神經網路引擎(Neural Engine)。
六、inference on Mac with python CoreML(inference_ane.py)
使用CoreML就可以調用神經網路引擎(Neural Engine)來做加速運算。以下說明步驟:
1.使用CoreML載入模型
2.Decode Segmentation to RGB函式
a.本次任務共有兩類,0 : 背景, 1 : 人,這邊預設將RGB三通道給全「0」與 全「1」,方便後續做影像乘積直接過濾人出來。
b.可以自定義輸入RGB數值,用於過濾背景與過濾人,方便等等計算可以模糊化背景。
3.OpenCV 開啟攝影機
a.使用OpenCV videoCapture開啟鏡頭,且輸入編號來選取鏡頭裝置,以我的設備為例:編號0 : 筆電鏡頭;編號 1 : 手機鏡頭。(編按:我的環境編號與下面C++的相反,需要注意)。
建議搭配檢查:1. 編號設備是否能成功讀取,2. 是否成功讀取影像。
b.使用兩個變數分別儲存兩個影像,原影像與模糊化後的影像,以方便後面應用。
cv2.GaussianBlur 為模糊化方法,其中 第二個參數 (55, 55) 必須為奇數,數字大小決定模糊化程度,第三個參數為0,主要是給GaussianBlur數學計算公式的參數,在常規操作下,設定0 即可。
4.串流影像進行預測
- 將videoCapture影像進行Resize成模型輸入尺寸。
- OpenCV Resize function是先 (w, h)
- OpenCV彩色影像通道排列是BGR,要轉換至RGB
- 將OpenCV matrix轉換至NumPy matrix,並使用 np.transpose() 將 channel 往前移動。
- Torch 為 channel first
- 模型計算,輸入參數是以字典形式,key : 第五節模型轉換時定義的輸入名稱,value: numpy matrix。
- 需要新增一個維度在NumPy matrix的第一維度,告訴模型有幾筆資料需要做計算。
- 模型輸出為字典形式,key : 第五節模型轉換時定義的輸出名稱,value: numpy matrix。
- 需要argmax()取出類別,squeeze()縮減不必要的維度。
- 將預測結果輸入至Decode Segmentation to RGB函式
Decode Segmentation to RGB函式會使用兩次,分別過濾 「人」與 「背景」
人的輸出乘以上述步驟中的「原影像」,背景的輸出乘以上面步驟的「模糊化後的影像」,最後結果從RGB轉換為BGR,並將結果輸出。
七、inference on Mac with C++ (inference_cpp/)
1.環境建置
- Libtorch
brew install libtorch - Opencv
brew install opencv
2.CMakeLists
- c++ 編譯環境設定
- 函式庫路徑設定
- 程式碼路徑設定(將所有有使用到的函式進行link)
建議還是使用PyTorch作為C++ Torch的編譯工具,經實測 Libtorch 執行速度較慢,若想看到更多網友們的討論請至:https://github.com/pytorch/pytorch/issues/19106 ,網友提供的解決方法。
同時,在CMake需增加一個參數,路徑指定到Python環境的PyTorch資料夾:
1.main.cpp
- Color Map
本次任務共有兩類,0 : 背景, 1 : 人,這邊將 RGB 三通道給 全 0 與 全 1,方便後續做影像乘積直接過濾人出來。
2.Decode Segmentation to RGB函式
a.產生一個與 Segmentation output 相同大小的且RGB皆為0的 OpenCV matrix
b.以迴圈依序將Segmentation output的類別值取出,且從color map中取出value填回上一步建立的OpenCV matrix
3.OpenCV開啟攝影機
a.使用OpenCV videoCapture開啟鏡頭,且輸入編號來選取鏡頭裝置,以我的設備為例:編號 0 : 筆電鏡頭,編號 1 :手機鏡頭。
b.讀取videoCapture的影像(以參照的方式取得影像)
c.建議搭配檢查,1. 編號設備是否能成功讀取,2. 是否成功讀取影像。
d.載入模型,以下將依序(i、ii、iii)說明步驟:
i.使用Libtorch中的jit load來載入模型,需注意模型會在訓練階段以ScriptModule儲存。
- 因為訓練階段是以CUDA 做訓練,在Mac中需要先以CPU讀取(torch::kCPU)。
ii.將模型移至GPU (torch::kMPS)。
iii.建議搭配檢查,模型是否有成功載入。
e.串流影像轉Torch Tensor並進行預測,以下將依序(i、ii、iii)說明步驟:
i.將videoCapture影像進行Resize成模型輸入尺寸。
ii.將OpenCV matrix轉換至Torch Tensor,最後使用permute將channel往前移動。
- 因為轉換目標是OpenCV matrix這邊維度為 { h, w, 3 }
iii.進行模型預測。
- 再新增一個維度
- Torch tensor 轉 FP32,移至 GPU,Normalization( 除 255)
- 進行預測
iv.可以在預測時加入時間,計算模型運算耗時。
f.將預測結果輸出
- 將Segmentation output進行argmax()
- 將output tensor轉換至OpenCV matrix
- 轉換後輸入至 Decode Segmentation to RGB 函式,並輸出結果
(編按:這邊將原始影像與decode Segmentation output 相乘並保留人像)
八、結論
這次文章分享如何使用 Core ML 加速運算以及C++ inference程式撰寫,這裡分享Python、Core ML 與C++ 三者模型計算的速度的差異:
模型計算的速度涵蓋以下流程,cpu input tensor → gpu input tensor → gpu compute → gpu output tensor → cpu output tensor。
Python GPU : 0.290 s
Core ML Neural Engine : 0.147 s
C++ GPU : 0.198 s
從結果發現,使用Core ML且使用神經網路引擎(Neural Engine),約能加速2倍。但是,這次會特別分享C++的主要原因是,在實際場域中,為了追求程式的穩定性,大多會採用C++為主要開發,但從這次結果來看, C++ GPU所帶來的提升幅度並不如預期得好,如果要實現最好的計算速度,勢必得使用C++ Neural Engine 來達到,相關資料可以提供參考,How to Integrate Core ML Models Into C/C++ Codebase。

(撰稿工程師:顧祥龍)




