你知道這個世界上有超過 40% 的語言沒有完整的文字系統嗎? 那這些沒有文字的語言要如何進行翻譯? 有沒有什麼方法能越過文字,直接對語音做翻譯呢?
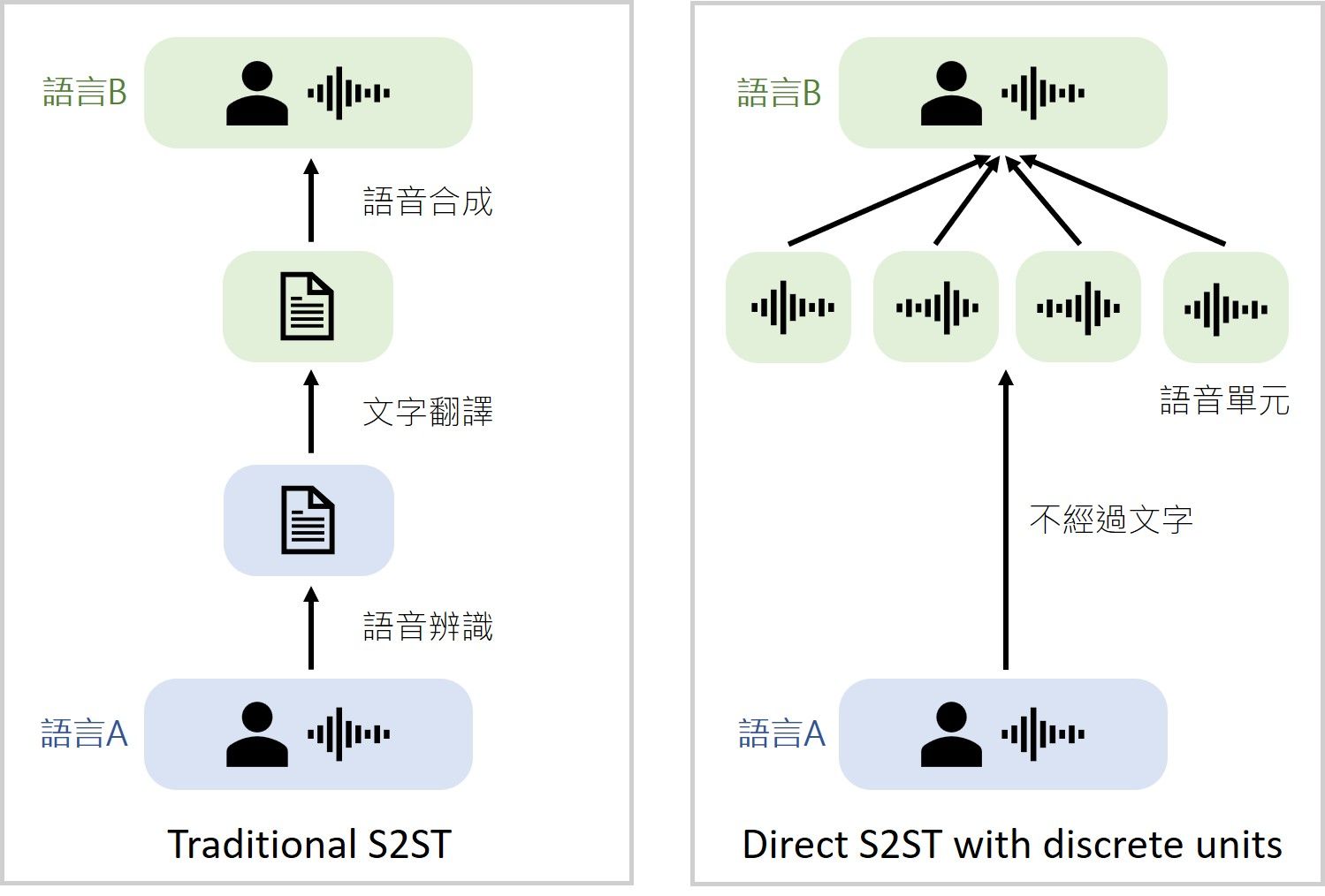
在傳統的語音到語音翻譯系統 (speech-to-speech translation; S2ST) 中,需要經過層層複雜的轉換才能完成任務:首先透過語音辨識將語音轉換為文字,接著對文字進行翻譯,最後再把翻譯完的文字透過語音合成轉換成語音訊號,在這個過程中各階段的運算成本和預測時間延遲都會不斷累積,且無法對沒有文字的語言進行翻譯。為了解決這個問題,Meta AI致力研究不經過文字轉換的 S2ST 方法,讓翻譯系統僅透過語音本身、不依賴中間的文字生成就能完成翻譯。
假設今天我們想要將中文翻成英文,那麼大部分S2ST 模型的作法會將中文音訊轉換成英文的聲音頻譜圖 (spectrogram) 再轉換成英文音訊,然而模型在輸出頻譜圖的時候很難學習到兩個語言之間的某些特性 (例如: 對齊問題 (alignment)、聲學及語言特徵等)。針對這個問題,Meta AI 提出了「離散語音單元 (discretized speech units)」的做法,將語音訊號大致分成許多固定的小單元,直接讓模型去學習輸出這些語音單元,最後再轉換成完整的語音內容。那麼這些語音單元是怎麼來的呢?我們可以先透過自監督式學習的方式,對一個沒有任何標記的語音資料庫進行訓練,讓模型熟悉這個語言的結構以及聲學上的特徵。接著我們對這些學習過後的語音表徵 (speech representation) 做分群,讓類似的表徵可以用一個群集來代表,這樣就完成了「離散 (discretize)」的動作,最後這個模型會用來產生目標語言的語音單元,作為S2ST系統預測的答案。這樣的做法可以直接將中文音訊轉換成英文音訊的小單元,接著再合成為一個完整的英文音訊句子。
有了不需透過文字、直接對語音做翻譯的模型,未來,也許我們能期待不同語言間的溝通門檻降低,讓不同文化間能更自由地對話。
Paper:https://arxiv.org/pdf/2107.05604.pdf
Official GitHub:https://github.com/facebookresearch/fairseq/tree/main/examples/speech_to_speech
(撰稿工程師:林芊)