
近年來,google開始利用自身的服務與背後累積的大量資料釋出Google landmarks dataset,並舉辦Landmark Recognition與Landmark Retrieval兩個挑戰賽,希望透過競賽聚集頂尖的挑戰者做出更有效且準確的應用。
Google Landmark Recognition主要目標是在給定一張照片後,正確辨認出照片內的景點、或是判斷此張照片是否屬於特定的景點,相較於傳統的影像分類任務,場景辨識的類別數量更多、類別內的變異更大,且類別間高度不平衡。
針對此題目的特殊性,我們結合了當前較有效的神經網路架構與損失函數,並針對非景點設定了篩選機制,使演算法在比對及尋找相同景點時,能過濾掉非景點的照片,同時取得良好表現。
現實生活中的類別不平衡資料
Google landmarks dataset V2(GLD V2)是全世界最大的地標辨識資料集 [1]。該資料集囊括了超過20萬個標籤及500萬張的圖片。今年採用的訓練集是經過2019年的參賽者濾過後的圖片,類別為8萬1313個,張數約150萬張。但該資料集最大的問題在於,有許多知名的地標,但其他地標的圖片非常少,資料不平衡的問題十分嚴重。


圖1.1為整個地標的圖片比例分佈圖,其中有2萬個類別僅有2張圖片,57%的類別裡的圖片最多只有10張左右,38%的類別最多只有5張圖片。圖1.2則是地標張數的比例圖,可以看到數量最多的類別為教堂、公園、博物館等,整個訓練集中約 28% 為自然景觀,72%是人為景觀。
Competition Methodology
GLR 2021 評分標準

範例的submission格式如下表 2.1 ,可以看到有兩個欄位,一個欄位是圖片的 id ,然後一個欄位是 landmark ,也就是我們需要預測出來的,這邊會輸出此圖片 id 的 landmark 標籤,再輸出此信心分數。
Table 2.1 範例格式輸出
由於此評分方式是根據信心分數作為排序並且依序做計算,因此可以了解到我們需要注意的是讓確定為某特定景點的圖片排序在前,若不確定此圖片之景點為何,則需盡量將其排序後往移動,以獲得較好的成績。
針對此任務進行的模型架構調整
由於這個比賽是在一個大型分類且訓練集極其不平衡的情況下,使用傳統的 softmax 作為輸出層的激活函數無法得到令人滿意的結果,因為 softmax 配上 categorical Crossentropy 的 loss function 時,有很高機率會訓練出一個只能分類出訓練集中許多圖片類別的模型,而忽略掉少類別的圖片。為了避免此問題的發生,我們在 CNN Backbone 的輸出儲存成一個512的 Embedding,並使用這個 Embedding 去對所有的訓練集進行 Cosine Similarity,以找出最相似的圖片,而損失函數則會把softmax 取代成 ArcLoss [3]。

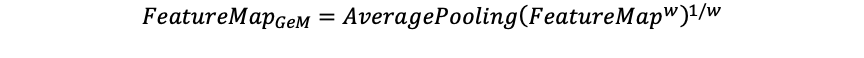
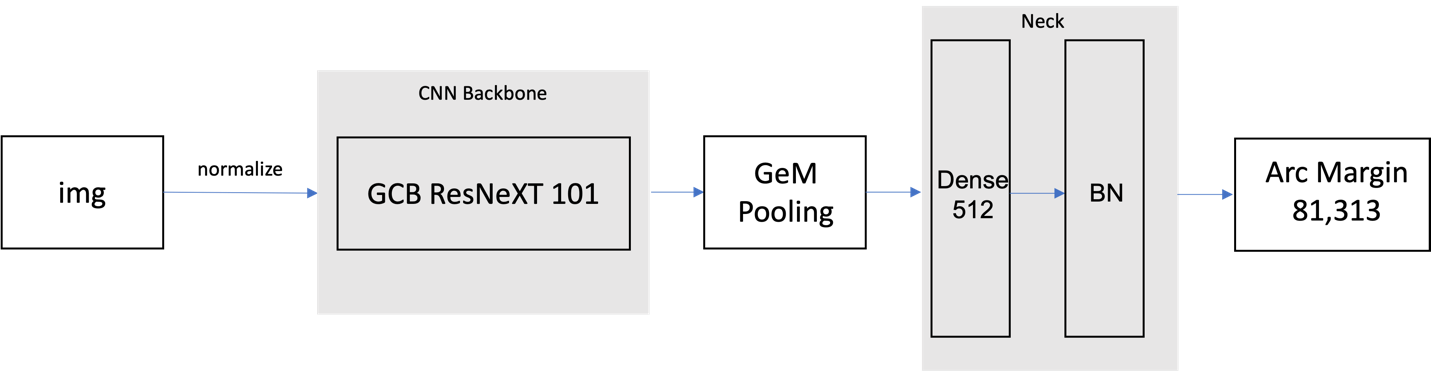
在Backbone部分,我們依照景點辨識的資料性質對模型架構做出調整,使其能有更佳的效果。首先,由於地標的訓練集常有不同角度的圖片,所以我們試著對每個 pixel 做 attention,以取得較全面的特徵。Global Context Block [4]是一種減少參數後的 self-attention based structure,藉由輕量化的 Non local block [5] 再加上 Squeeze and Excitation block [6] 以達到pixel wise 與 feature map wise 的 attention。我們將這個 Global Context Block 加進ResNeXT [7]的 Residual Convolution Block 中,設計出GCB ResNeXT的架構,以下再針對架構中的兩大部分分別做較詳細的說明。
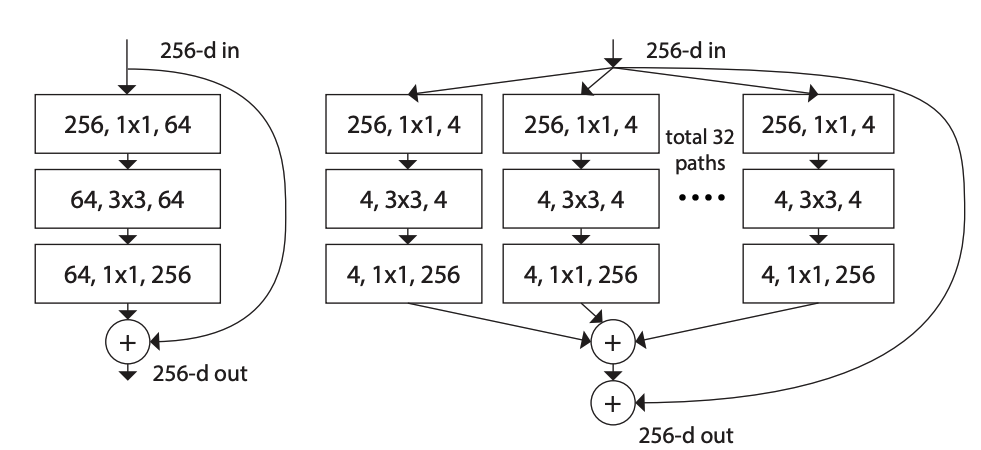
在backbone的基底模型部分,我們選擇ResNeXT。ResNeXT 是一個由 ResNet [9] 結合 Inception [10] 的多重架構。但是, Inception Block 最大的問題在於平行的卷積造成運算量的負擔,所以作者提出了相似於 AlexNet [11] 的概念,Group Convolution。如圖 2.2 所示,此時會把 filters 切得更細微,使得每個 group 的卷積操作彼此獨立 ,這樣比起一次平行運算可以有更少的參數。
在地標的大型分類上,可以看到很多相同的地標都有極度差距的差異性,可能是近拍、遠拍,甚至是拍攝角度不一致,如圖 2.3 所示。為了克服這種情況,模型需要知道每張圖中最重要的特徵點,且要有更細緻的特徵,在普通的 CNN 架構下,只有在經過多次卷積的狀況時,模型能看到全局的資訊,但此時這些特徵圖已經失去主要的細節特徵,因此在後續的分類中,很有可能找不著相依性。因此在 ResNeXT 的淺層網路中我們也加入了 self attention [12]的機制,此機制可以讓我們在前期淺層的 local 資訊中,找出關鍵的點,使整張圖也有 global 的資訊。可以想像成每個 pixel 都會有一個權重,這個權重代表對這張圖的重要性。

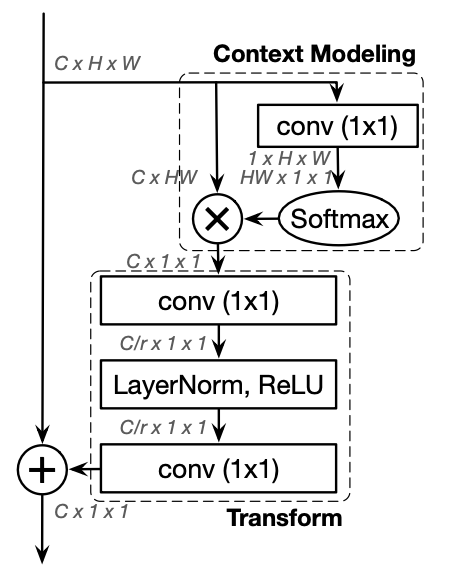
但原始 self attention 的計算量有著過於龐大的缺點,因此我們以 Global Context Block 的架構替代原始的self attention。作者提出這篇論文時曾提醒,在原始的self attention操作中,其實許多feature map 中的 attention score 幾乎是相同的,如圖2.4所示,因此其實可以對此架構做輕量化,在輕量化的過程再加入Squeeze Excitation Block [13],讓其達成同時有spatial以及 channel 上的 attention。架構圖可以參考圖 2.5 。

訓練策略
在訓練機制中,表 2.2 是我們模型所運用的伺服器環境。我們一開始探討了幾個可行性較高的模型去進行訓練,表2.3是我們整個訓練所使用的模型以及他的 驗證集以及公開測試集的 GAP score。每個模型的 input size 都固定在 (512, 512, 3)的大小,希望藉由較大的解析度找出更細緻的特徵。
首先,我們先用在 ImageNet 訓練過的幾個有名的預訓練權重,如:EfficientNet B3 [14], EfficientNet B7 和 DenseNet [15],測試此任務是否能藉由遷移學習得到不錯的結果。我們在實驗中固定訓練 10 個 epoch,且 batch size 設定為 64 ,實驗結果如表2.3。可以看到,因為預訓練權重上的特徵跟比賽的地標差異性太大,所以分數非常低。
為了有效提升分數且在訓練集張數極大的情況下,我們自己建立了 ResNeXT 101進行訓練,之後再加入 Global Context Block 及 GeM Pooling等模型結構,在超參數設定相同的情況下,相較於單純使用遷移學習, 單以ResNeXT 101 with Global Context Block and GeM Pooling即可以在公開測試集的 GAP 中獲得0.230的分數。
Table 2.2 The Hardware Environment
Table 2.2 訓練模型結果
Reranking 機制
之前我們提到利用 ResNeXT 101 with GCB and GeM pooling 可以讓整體模型的Public GAP 提升到0.230,這個方法其實只是將每一張測試集的圖片比對所有訓練資料集,然後用模型輸出的 Embedding 去比較 Testing set 與 Training set 中最相近的圖片,並將圖片當成 Top 1 輸出。但是,這個方法沒有考慮到非目標地標的圖片資料,在 kaggle 上面的公開與非公開測試集中,有接近 98% 的資料是屬於不在訓練集的地標中,因此除了在真的有地標的測試集中要能準確比對出來,最重要的是,要過濾掉非地標的圖片,並大幅降低非地標的圖片信心分數,使其不會影響整體 GAP 的分數。非地標的圖片如圖2.6,可以看到有完全與地標無關的圖片,也有感覺很像地標,但不在訓練集地標標籤中的圖片。

「如何將測試集中非地標的資料找出來?」是一個較為困難的問題,不過在 google landmark dataset 中,提供了一個2019年非地標的資料集,這個資料集中全部的圖片都是不在訓練集標籤中的圖片,可能是人臉、動物,或是建築物,這個資料集的數量約11萬張。所以我們可依據這個非地標的資料集,先對訓練集的每張圖片做 cosine similarity,再判斷訓練集中重複被挑到次數的訓練集圖片有哪幾張,並進行扣分機制。
在扣分機制中,首先我們會拿每一張的非地標資料集 NonLandMark[i] 對所有的訓練資料集 Training_Set 做 cosine similarity,並取出 Top 20 相似的訓練集圖片集出來,接著統計出每一張Training_Set被取出來的次數,圖 2.7 為儲存出來的表單格式。表單中的 img_path 就是訓練集的圖片檔名, sims 則是計算出來與 NonLandMark圖片的 cosine similarity,最後的 n_picked則是此張訓練集圖片被 NonLandMark 資料集中篩選出來的次數,最多只會到 12 次。
圖 2.8 為我們扣分機制演算法的 pseudo code ,我們的上限是統計到一張訓練集圖片被挑出來 max_n ,也就是 12 次,如果挑出來到這個最高次數則會直接扣掉這個平均的 cosine similarity,如果挑出次數小於最小次數 min_n,那這張圖片就不會有任何扣分動作,因爲可能是模型的誤差不小心挑出來的。最後如果介於 min_n 以及 max_n 次數的圖片,我們的扣分機制則是會需要被扣分的最大比例 max_pro 以及需要被扣分的最小比例 min_pro,此兩個數字為超參數,我們分別設定為 1.0 以及 0.3,然後以公式3作為計算最後扣分分數的方式。
- min_pro - min_n +1*(- min_n +1)*score
公式3

這個扣分機制預期可以讓我們有效地對測試集中非地標的圖片扣分,讓測試集中真的是地標的圖片排序在前面,因為 GAP 的算分下,排序前面的圖片一定要能正確的分類,才能得到分數。加入此扣分機制使得我們公開測試集的整體 GAP 從 0.230 提升至 0.244,這個分數最後也讓我們在比賽中的非公開測試集中取得不錯的成績。
後續應用
這次比賽我們以 ResNeXT的架構當作基底,並在裡面的 block 中加入 high quality 的 image self attention 機制,然後也用大型分類中較有競爭力的 Arcloss,最後再使用我們設計的扣分演算法達到前25%的成績。我們也從實驗判斷出 image attention 的機制下,讓淺層的網路中找到 global feature,讓模型更能關注在這些全域特徵中,且還能有效的傳遞到後層網路中。排名較前的參賽者,大多取得更大的公開訓練集 – GLDV2x,此資料集包含約320萬張圖片,這個數量是我們訓練集的兩倍大,該現象同樣顯示深度學習對資料量的需求,隨著資料量增加可以持續進展的特性。在後續或相關的題目上,除了ResNeXT,也可以再嘗試其他的模型作為backbone,如:Focal Transformer, Swin Transformer, NFNet,並利用集成學習的方法,對不清楚的一些圖片中做 weight voting 以找出最佳的結果。
隨著深度學習技術的進展,各研究團隊也不斷提出難度更高的任務待解決,本次針對類別數極大、資料不平衡狀況明顯、且同時需要全局與細部資訊之地標分類問題進行實作。未來,假使遇到具有相似任務性質的問題時,或許可參考本文所使用的架構與處理方式。
Reference
- T.Weyand, Andre Araujo, B. Cao and J. Sim, “Google Landmarks Dataset v2 – A Large-Scale Benchmark for Instance-Level Recognition and Retrieval,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020.
- “GAP,” https://github.com/google-research-datasets/gap-coreference
- J. Deng, J. Guo, N. Xue and S. Zafeiriou, “ArcFace: Additive Angular Margin Loss for Deep Face Recognition, ” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019.
- Y. Cao, J. Xu, S. Lin, F. Wei and H. Hu, “GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond, ” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019.
- X. Wang, R. Girshick, A. Gupta and K. He, “Non-Local Neural Networks, ” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018.
- J. Hu, L. Shen and G. Sun, “Squeeze-and-Excitation Networks, ” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018.
- S. Xie, R. Girshick, P. Dollar, Z. Tu and K. He, “Aggregated Residual Transformations for Deep Neural Networks, ” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
- F. Radenovic, G. Tolias and O. Chum, “Fine-tuning CNN Image Retrieval with No Human Annotation, ” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
- K. He, X. Zhang, S. Ren and J. Sun, “Deep residual learning for image recognition, ” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
- C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke and A. Rabinvich, “Going Deeper with Convolutions, ” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
- A. Krizhevsky, I. Sutskever and G. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks, ” Advances in neural information processing systems, 2012.
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, L. Kaiser and I. Polosukhin, “Attention is All You Need, ” Advances in neural information processing systems, 2017.
- T. Mingxing and Q. Le, “Efficientnet: Rethinking model scaling for convolutional neural networks, ” in Proceedings of the International Conference on Machine Learning, 2019.
- G. Huang, Z. Liu, L. Maaten and K. Weinberger, “Densely Connected Convolutional Networks, ” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
