實作應用, 技術 AI 如何應用在瑕疵檢測上 瑕疵檢測是許多製造業中關鍵的品質控制環節,傳統的瑕疵檢測方法主要依賴人工檢測或基於規則的方法,這些方法儘管具有一定程度的效果,但仍有不夠精準、效率低下和容易受到環境變化影響等問題。隨著人工智慧技術的發展,特別是機器學習和電腦視覺的進步,瑕疵檢測領域的技術不斷推陳出新,不僅可結合傳統手法提升準確率,還能透過生成式 AI 輔助生成訓練用的瑕疵資料,讓瑕疵檢測更精準、更符合快速更迭的產線週期。
技術, 實作應用 AI 也懂人話?機器學習在 NLP 的基礎概念 「自然語言處理」又稱為 NLP(Natural Language Processing),是近年來十分熱門且挑戰性十足的研究領域,這篇文章將介紹 NLP 的基礎知識,並說明 NLP 在深度學習的理論及解法,帶大家了解在使用自然語言處理時會遇到的困難。
技術, 實作應用 如何建立多人AI開發環境?JupyterHub安裝分享 辦公室有一台GPU server供幾位工程師共用,有不便放上雲端的資料就可以直接放進去跑。深度學習演算法的開發常常需要使用不同環境,因此我們以docker方式提供Tensorflow 2.x, 1.x, Pytorch等幾種不同環境,然後每種環境以不同的port為進入點,都以Jupyterlab為介面。
實作應用, 技術 當資料不平衡時,如何提高影像辨識準確度?(Google Landmark Recognition 2021 Solution) 近年來,google開始利用自身的服務與背後累積的大量資料釋出Google landmarks dataset,並舉辦Landmark Recognition與Landmark Retrieval兩個挑戰賽,希望透過競賽聚集頂尖的挑戰者做出更有效且準確的應用。
技術, 實作應用 有了模型然後呢?從資料模型到數據產品 當你想打造一個「數據產品」時,僅有資料模型的解讀靜態報告是不夠的,一個更貼近使用者應用場景的解決方案是必須的。從資料科學模型到產品之間,還有哪些事情必須要顧慮?
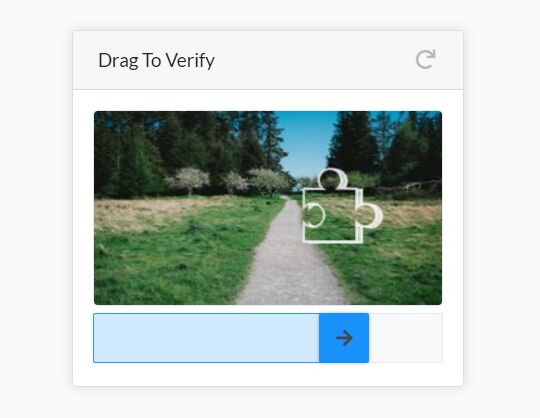
技術, 實作應用, python 爬蟲開發者必學:讓 Python 讀懂「滑動驗證碼」 動態網頁與靜態網頁最大的不同是資料是在什麼時間點取得的,動態網頁是在瀏覽器已經取得 HTML 後,才透過 JavaScript 在需要時動態地取得資料。因此,爬蟲程式也必須要考慮動態取得資料這件事情,才有辦法正確地找到想要的資料。「滑動驗證碼(Slider Captcha)」是驗證碼機制當中常見的典型,也是防範爬蟲程式中一種難纏的對手。這一篇文章將會利用 Python 、opencv 與 Selenium 三個工具,示範如何拆解和模擬滑動驗證碼。
技術, 實作應用, python 從Python到爬蟲,給新手學習地圖與策略 資料爬蟲是資料分析的起手式,必須有好的、可用的資料才得以進行高品質的資料科學專案。而過去的資料來源多半來自於公司內部的資料庫或資料倉儲系統,仰賴於工程師跟 IT 部門的支援。但隨著 Big Data 的技術到位,實務上對於資料的要求更加大量也更加多元。因此,利用程式與資料爬蟲收集資料是目前資料來源的一個重要的管道。