

隨著ChatGPT、Midjourney等話題引發熱潮,也引發大眾對於生成式AI的好奇,從圖像生成、語音生成、文字生成等單一任務,逐漸發展出越來越多元的生成任務。這次要探討的是如何結合人臉影像與語音的生成任務,組成一個說話語音生成任務:Talking Face Generation。
生成式AI是什麼?
生成式AI是利用AI技術來生成資料,常見的生成任務如圖片生成、語音生成與文字生成等單一任務,目前知名度最高的兩個生成模型就是ChatGPT 與 Midjourney 。ChatGPT 是一個自然語言生成模型,可以執行聊天、翻譯、問答等任務,甚至能幫忙寫程式;而 Midjourney則是輸入一段指令,如「there is a robot, he is drawing.」 就能生成字面上意義的圖片,如下圖。目前常見的生成模型還包括Generative Adversarial Networks、 Auto-Encoder與Diffusion model等。

用聽的,就能畫出符合聲音的人臉?
由MIT學者於2019年發表的Speech2Face : Learning the Face Behind a Voice,從題目就能知道,這是一個結合人臉圖像資訊與語音資訊,利用說話者聲音重建人臉圖像為目標的模型。透過從網路上所蒐集到的百萬部包含人臉的影片,作為訓練資料,接著還要訓練模型理解聲音與人臉間的關係,找出兩者的關係後再重建出臉部細節,這需要集合臉部特徵提取網路、語音特徵網路以及臉部重建網路等三個部分才能完成。以下將分別說明:

首先是臉部特徵提取網路,這個網路的目標是找出人臉的重要特徵,這部分使用的模型是2015年提出的 VGGFace 人臉模型。由於該模型已經有大量的人臉資訊,因此就能將輸入的人臉再輸出出重要特徵,並提取出重要特徵。
第二個語音特徵網路的目標是將語音變成有用的特徵資訊,人類之所以聽得懂別人所講的話,就是因為人腦能將這些語音變成我們能理解的資訊,因此,為了讓電腦也能執行任務,需要訓練一個網路將語音資訊轉換成有用的資訊。必須完成以下兩個步驟,首先將語音資訊轉換成頻譜圖,頻譜圖能將語音資訊有效的轉換成二維資訊,以方便圖片運算處理;接著,建立一個簡單的CNN 模型,將前一個步驟的頻譜圖放入該模型訓練,使之成為一個有用的音訊特徵。
第三個臉部重建網路則是將訓練好的語音特徵進行臉部資訊重建,前面已經說明了如何找出人臉特徵與語音特徵了,也知道人臉與語音間的關係,接著就是要將該語音資訊轉換成人臉。這裡需要再搭建一個CNN模型,以作為臉部重建網路。因此,我們需要輸入能提取出有用語音的資訊,並將此段資訊輸入臉部重建網路,並還原該人臉圖片。
這是第一個提出結合語音與人臉網路的做法,由於還有許多小細節尚未探討,因此可能會出現語音為男童聲音,卻生成出女生人臉;或雖然是老年人講話卻生成年輕人的臉部影像的狀況。
生成出自然人臉結合講話影片的兩大關鍵
《FACIAL : Synthesizing Dynamic Talking Face with Implicit Attribute Learning》 是一篇在2021年被提出論文,主要說明人臉與聲音生成的影片任務。主要目標是希望生成出一段人臉說話的影片,且所說的話為事先提供的文字內容。這篇論文提出幾個過往作法的問題,例如所生成影片的臉部表情或臉部動作都不會改變,或是沒有很好地做出一些臉部晃動細節,包括眨眼動作,而這篇論文就是要提高人臉講話生成的細節還原度。
其中,有兩個重要的關鍵,分別是顯性屬性,例如嘴唇動作等和語音有絕對正關係的屬性,另一個則是隱性屬性,如:頭部運動、說話方法、眨眼睛等細節動作。必須將兩個步驟都考慮到,才能得到更進一步的生成效果。模型的做法則分成兩個分支,一是藉由輸入的語音資訊進行生成,用 Facial-GAN 生成出眨眼睛、臉部動作等細節動作,接著,透過公式轉換找出何時需要眨眼睛。另一個分支是將輸入的人臉影片當做 3D人臉重建,從重建中找出人臉最重要的 Identity、Texture 與 lighting 特徵,再整合上述 Facial-GAN生成出來的特徵,就能生成出一段自然的人臉講話影片。
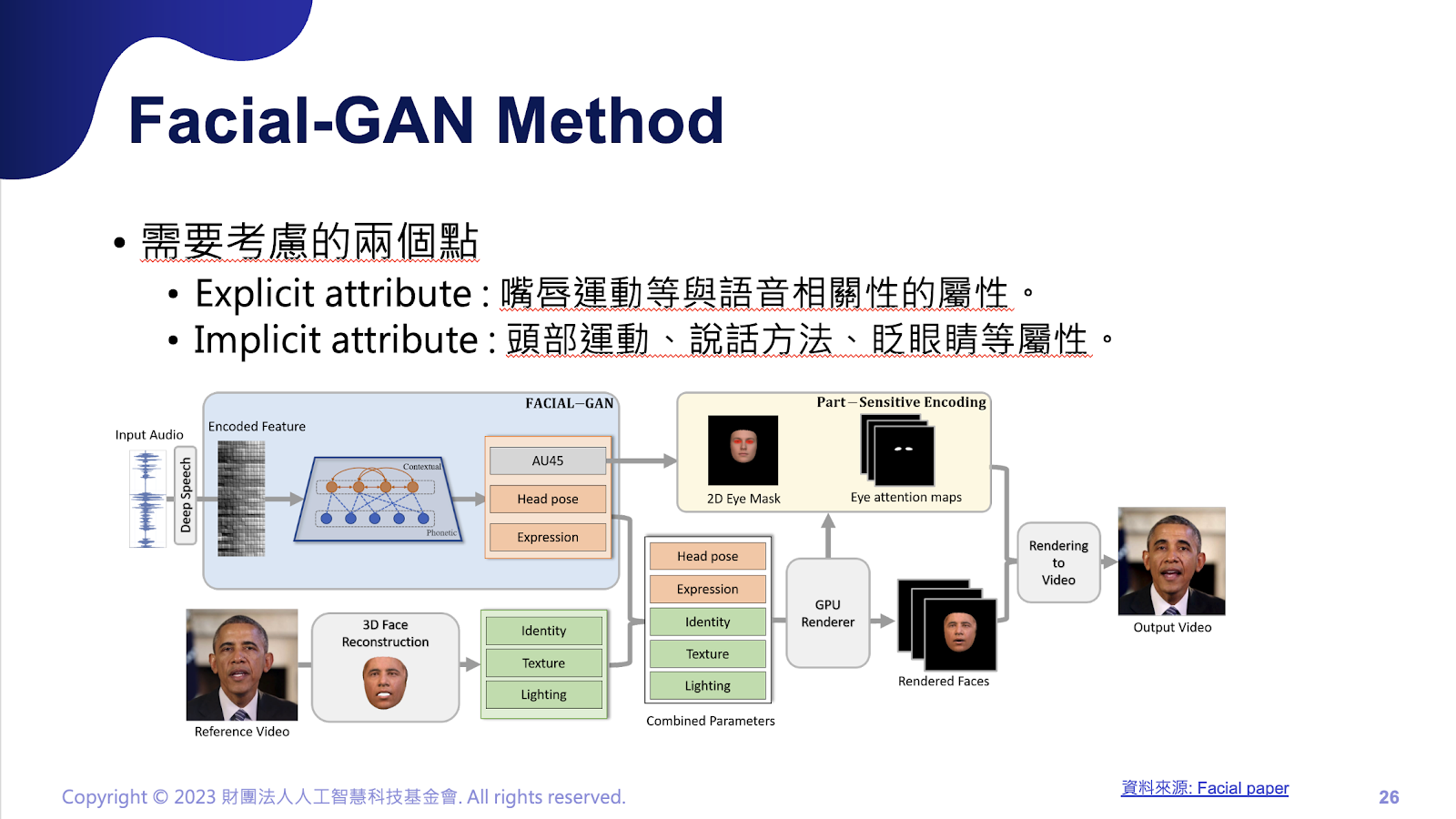
相較之下,3D人臉重建任務較為簡單,主要例用 3D Morphable Model進行,模型在訓練時需要各個角度的平面人臉圖像,才能還原出3D 人臉相關參數。另一個則是該論文的重點項目:Facial-GAN,必須考慮表情、姿態及眨眼三個特徵。輸入的特徵為完整的語音資訊及區間性的語音資訊兩大類,區間性的語音資訊就是將一部聲音切成N等分,使之學習聲音區間的關係,兩者會結合成一個生成器,生成出表情、姿態及眨眼等特徵,並透過鑑別器評估生成的資訊,以對抗式訓練訓練成生成器。從最後訓練出的結果可以看到,該做法的所生成的人臉,比起其他作法的自然度更高。

可以看到生成AI的任務是可以有多種變化的,也可以將不同類型的任務去做結合。目前Talking Face Generation的生成上已經幾乎跟真實的狀況一模一樣了,但是還是避免不了一些小瑕疵,像是一些單獨一些人會有的特點可能無法還原。目前在圖像生成任務上,Diffusion model 已經是越來越熱門的話題,像是 Midjourney也是採用此種方法,未來生成任務上,有可能會以此做法作為一個趨勢。最後就是生成式AI這種東西畢竟是生成出非真實的資訊,所以請大家務必要小心使用,避免踩到法律界線,未來也會看到更多法律會去約束此種生成式AI的任務。




