

無疑地,超級無敵大語言模型ChatGPT是2022年最大的驚喜與驚嚇,兩個月收割兩億用戶,破了有史以來最快爆款記錄,幾乎所有人都忍不住打開OpenAI網站試一試這個號稱地面最強AI的玩具。
*本文關鍵哏適合四十歲以上成年人閱讀
學界被嚇到了,宣佈不許用chatGPT寫報告;商業界開心了,開始努力探索到底可以如何透過這玩意兒賺錢;AI業界跳起來了,Google對內發出紅色警報,然後反手丟出更大的模型。我們工業界當然也很興奮,不少公司躍躍欲試,希望可以在內部也創造出相關的應用。
微軟手比較快,不僅早已投資10億美元,接下來還傳出要聯合其他資本大咖,繼續投資100億美元,微軟人工智慧平台(AI Platform)企業副總裁 Eric Boyd 還宣布,旗下雲端 Azure 將推出OpenAI 服務。客戶將能夠透過 Azure OpenAI 服務使用ChatGPT,同時利用 Azure AI 基礎設施進行訓練,並執行推理的 GPT-3.5 優化版本,而在收回投資之前,微軟也將獲得 OpenAI 75% 的利潤,這意味着OpenAI將採取商業運營,有趣地是,chatGPT也已經申請商標,除了衆所周知的自然語言模型服務外,還包括文件、鞋類、服裝與遊戲等[1]。此時,OpenAI的估值已經到了290億美元。對了,差點忘了說,微軟也同步宣佈將裁員1萬人。
華爾街的名言之一是「如果連掃地阿姨都在談股票,那就是賣股票的時候了」,在chatGPT 如此火熱的狀況下,別說掃地阿姨,說不定沒多久連掃地機器人都要宣稱自己是chatGPT inside (內置chatGPT)了。
中國向來輸人不輸陣,最近一段時間的討論也是,爲什麼中國沒開發出自己的chatGPT。多數人的觀點是,大型語言模型的投入需要更大的資金與技術,不是做不到,還沒做而已。畢竟近十年來,全球AI相關專利超過52萬件,其中中國申請量接近39萬件,佔全球總量的 74.7%[2]。截至2021年9月爲止,光是騰訊一家公司的AI專利,就幾乎相當於微軟與Google 的總和[3]:

chatGPT自己倒是給出了頗爲凡爾賽的看法:

(作者註:為避免使用簡體被退稿,改寫為繁體,絕不是因爲要騙稿費)
人問:「爲什麼chatgpt率先出現在美國,而不是中國?請分析及解釋。」
機答:「ChatGPT是由OpenAI公司研發的,OpenAI是一家美國公司,所以它最先在美國出現。此外,美國的科技行業和人工智慧研究領域非常發達,擁有世界上最先進的研究機構、大學和私人公司,這些機構和公司擁有豐富的研究經驗和技術能力。因此,美國具有很好的研發環境和資源條件,使得美國成為人工智慧領域的領導者之一。另外就是中國相對於美國而言,在人工智慧的研究上似乎更多的關注在實際應用上,而非研究基礎,這也可能是造成中國沒有像美國那樣率先研發出ChatGPT的原因。」
砰!一槍倒地。這是誰家教的AI?你是要上天了嗎?准你說故事,誰准你打臉的?專注應用有錯嗎?怪我咯?真是好笑,哈哈哈哈嗚嗚嗚,好痛。
從數據上來看,ChatGPT是站在GPT-3的基礎上發展的階段性成果,想要訓練ChatGPT不能忘記還得先有GPT-3,但訓練一個GPT-3要花費多少力氣?
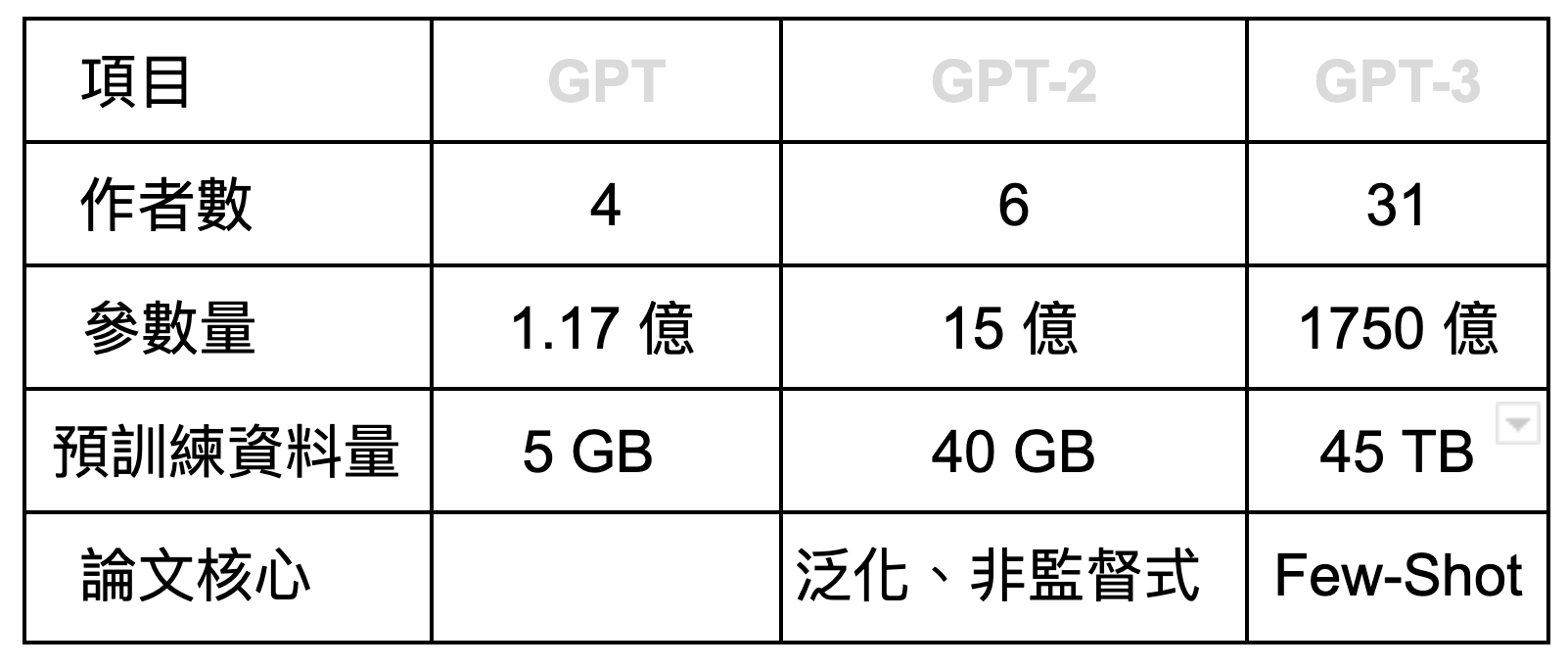
從原始論文來看,2020件發表的GPT-3的參數達到1750 億個之多,原始訓練資料量有45TB,單次訓練費用高達1200 萬美金,OpenAI自己承認成本高到就算發現有錯誤,都無力重新訓練。

(可惜地是,就算發現了訓練過程中的錯誤,基於訓練成本考慮,我們也放棄了重新訓練模型的想法gpt。)
1750億個參數!這不僅是大型語言模型(Large Language Model, LLM)了,而且還是VLLM(夭壽大語言模型, Vary Large Language Model, LLM)。更別提45TB的訓練資料量,美國國會圖書館號稱全球最大圖書館,分類藏書超過2500萬本,非分類資料超過1.3億份,按照chatGPT的統計大約落在5TB之間。換句話說,訓練一個GPT-3需要取得將近10個美國國會圖書館的資料量。表面上來看,chatGPT需要的量沒有這麼多,只需要40G,但這是在GPT-3的預訓練結果上再進行遷移學習所需要的資料量,不會比較簡單。在前次專欄中也已經跟各位分享過,按照當前發展,人類現有可用文本已經無力支持更大的語言模型,接下來只能在算力與模型上繼續推進軍備競賽了(有人建議可以納入鳥叫蛙鳴貓喵狗汪,不失為一個浪費時間的好主意。)
OpenAI並不是因爲先預知後面會有一堆大咖排隊投資才決定要做大型語言模型,實際上,這是基礎研究推進到一個程度,水到渠成、錢放口袋會燙到要害、不得不然的發展過程,而OpenAI也早在2018年就已經對外發表chatGPT最初版本。OpenAI在2015年剛創立時,啓動金額不少於10億美元,原始投資人包括馬斯克跟貝佐斯(對,你沒看錯,在太空事業上幾乎是死對頭的兩個人都是OpenAI的創始投資人),走着走着,微軟在2019年還追加了10 億美元,最近繼續加碼,還要在Azure上全面導入,這就不是科學家的把戲而已了。
從公開資料上得知,OpenAI目前年營收約在5000萬到1億美元之間。想想Google力挺的DeepMind,從2016年到2019年總虧損超過40億美元,2020當年實現年營收大於支出,終於獲利5960萬美元。同理,以OpenAI目前投入的七大研究方向來說,合理推算不但虧,還虧得理直氣壯、很不手軟,但以臺灣企業的習慣來說,完全不符合投資效益,哪裏有傻瓜哪邊去,沒有一年回本的都不要來找我。
爲什麼要說這麼多?因爲跟臺灣如何看待自己在AI產業的定位有關。
我們必須承認,不管是在資料量、人才、資源、算力與基礎研究上,臺灣還不具備可以跟大國正面硬拼的實力,別說企業比企業,就連數位發展的國家政策都還在放煙火、賣麵線的階段,在這個基礎上要在短時間獨步全球,打造全新AI島,也許就像老歌唱的「卻只是想想而已,我已經不能肯定,你是不是還會關心?」總不會因爲「愛與不愛都需要勇氣,於是我們都選擇了逃避?」
好吧,說是逃避,也許太沉重,君不見國科會馬上說要投資打造臺灣本土的chatGPT,「今年年底就會上路哦,啾咪,」理由是「為避免讓有思想偏差的AI引導業界」。呃,打造「有臺灣本土意識的AI」來導正業界也許是一種方式,不過,把同樣規模的預算投入扶持臺灣AI產業,從根本上以「可信賴AI」、「AI標準化」來解決「思想偏差」問題,更進一步鋪平臺灣AI產業前進全球專業服務分工市場,以臺灣擅長的專業代工模式,同時服務馬上就要迸發的AI需求狂潮,不是更靠譜些?臺灣中小企業佔98.92%,以艱苦人賺的辛苦錢訓練一個昂貴的時尚玩具,然後來導正AI的思想偏差?怎麼想都很怪異。
不管多少人嘲弄他,AI超級大咖Yann LeCun還是一直堅持chatGPT沒什麼了不起,「寫文案 應該不錯啦,」他推推眼鏡說。臺大教授李宏毅說得比較中立,「我們還離語言模型的終點還有很長一段距離,原因很簡單,人類遠遠不需要這麼多資料量,就可以做的比 ChatGPT更好。突破的方式就是我們對今天的模型,還能怎麼樣更進一步的了解,AI還是一 個黑盒子,未來會有很多研究人員像是腦科學家一樣去解剖AI。[5]」
想要一較高下,從來不會是以己之弱迎彼之強,而是評估自己如何憑藉既有基礎切入即將成型的全球價值鏈之中。就以臺灣最自豪的製造業來說,有一百種突破現況的選擇,例如協助工業界建立共同的數據交換體系、定義與平臺,在維護資安的前提下將散落破碎的工業數據逐步拼湊起來,或許才有機會。知名AI科學家吳恩達(Andrew Ng)在近年也一直推廣以數據品質爲中心的AI(Data-Centric AI),而不是傳統以模型為中心(Model-Centric AI)的做法,他認爲高品質的數據比需要投入大量數據才能獲得的模型來得重要許多。
如果還不下定決心從最基礎的功夫做起,說再多e化,或費心模仿chatGPT,也只是將兩者 完美結合,把e放中間,搞成一個外觀看似靚麗的CheatGPT而已。俗話說,「滿天全金條,要抓沒半條」,這樣的代價,我們付出得還不夠多嗎?還不說,如果只是借用chatGPT的API搞花式跳水,其實就等於將自己所有機密送到一家已經虧損上千億的外國公司手上呢。
很想給你寫封信,卻只是想想而已。
我已經不能肯定,你是不是,還會關心。
——巫啓賢《你是我的唯一》,飛鷹唱片,1988年
1.美國政府商標電子檢索系統 (uspto.gov),申請序號 97719809
2. 中國國家工業資訊安全發展研究中心 中國工信部電子智慧財產權中心. (2022). 《 AI創新鏈產業鏈融 合發展賦能數字經濟新時代 — 中國人工智慧專利技術分析報告( 2022 )》. 中國國家工業資訊安 全發展研究中心.
3. Business digest editorial. (2023, January 27). _【人工智能】中國公司爭相申請人工智能專利 騰訊百 度申請數全球最多.__ Business Digest Editorial. https://businessdigest.io//行業數據/人工智能-中國 公司爭相申請人工智能專利-騰訊百度申請數全球最多
4. Henrry chen. (2022, October 6). Day 21. 深度學習模型 - NLP 預訓練模型.,2022 IThome 鐵人賽. https://ithelp.ithome.com.tw/articles/10304910?sc=iThelpR
5. 陳君毅. (2023, February 7). Google對話式AI服務「Bard」,劍指ChatGPT!圖解ChatGPT關鍵技術. 數位時代. https://www.bnext.com.tw/article/73508/all-about-chatgpt-2023




