
Machine Learning Operations(MLOps)是持續性機器學習模型管理與部署的實踐,可以幫助機器學習模型開發團隊有效地執行模型的實驗、管理、部署等任務。任務細節多半依據團隊的實際需求客製化各種功能,並利用網路上各種不同專攻功能的套件,整合成一個 MLOps 系統。本文將從開發團隊的需求出發,依序先介紹 MLOps 系統的基本功能需求,並據此挑選套件,最後利用這些套件搭建一個實用 MLOps 系統。幫助讀者快速暸解一個實用的 MLOps 系統的設計過程。
MLOps 系統的基本功能需求
在設計 MLOps 系統時,主要會以開發團隊目前的機器學習專案開發流程為基礎,並以此設計系統。(圖一)是一般常見的模型開發流程,可以看到在取得原始資料後,會先做不同版本的資料前處理,接著依據不同版本的前處理方式分別建立模型,再對各個模型進行驗證與比較,最後選擇最好、最穩定的模型部署上線。這一系列的流程多半會由開發團隊中的多位成員共同協作完成,因此,如何讓團隊成員間可以更好地協作、減輕成員負擔,就是考量 MLOps 基本功能需求的首要目標。
| 圖一:模型開發流程與 MLOps 需求。 |
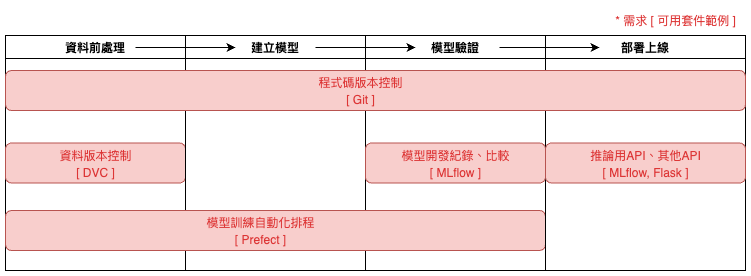
在整個開發流程中,最為繁瑣卻最重要的部分就是確保各個流程可以被所有成員管理、重現、紀錄、比較,要做到這點,版本控制及實驗紀錄的功能也就不可缺少。其中,版本控制包含所有流程的程式碼版本控制,以及資料前處理的資料版本控制,在不同的模型開發紀錄當中,用了哪個版本的程式碼、資料都應該一併被紀錄下來,以方便事後比較與重現。最後,在確定好要部署的模型後,便需要透過建立推論用 API 的功能將模型部署上線,或與其他 API 串接。除此之外,如果開發團隊希望模型可以定期自動化重新訓練,那就會另外再加上模型訓練自動化排程的功能,讓模型可以定期依據新蒐集到的資料重新訓練。讀者可以參考(圖一)了解這些不同的需求。
那麼,在了解機器學習專案的開發流程與基本功能需求後,我們該如何實現這些功能呢?目前市面上並沒有一個具備所有 MLOps 所需功能的套件,但是,隨著 MLOps 的發展,現在網路上已經可以找到許多針對不同需求而開發的套件,讓使用者可以依照所需挑選套件,最後整合成系統。以下將就(圖一)的基本功能需求挑選套件,並說明所對應的功能。
套件的選擇
其實,選擇套件並不是一件困難的事,無非就是根據需求、經費等因素考量後,按圖索驥選出適合團隊的工具而已。以下將簡單列舉挑選特定套件的原因,讀者可以根據團隊需求自由更換其他套件,若想知道更多套件的介紹與挑選原因,不妨關注 MLOps 系列文 ,後續將針對套件進行詳細介紹。
首先,我們選擇以工程師常用的 Git,做為版本控制方面(如圖一)的套件,並將程式碼上傳到 GitHub 或 GitLab 平台管理;而資料版本控制的套件則選擇使用 DVC ,主要原因是該套件與 Git 操作方式很像,可以快速與 Git 整合使用。
在模型實驗紀錄與比較方面的套件則使用 MLflow,選擇它的原因是該套件除了具實驗紀錄、比較的功能,還可以透過紀錄實驗執行環境,幫助開發團隊準確重現模型實驗,甚至將模型快速部署上線成推論用 API,當然模型部署上線也會與其他 API 串連,且這些 API 可以用 Flask、 FastAPI等套件建置。
模型訓練自動化排程部分的套件則選擇 Prefect ,它在排程使用的設計很簡潔,只需將資料處理、模型建立等不同任務的 Python 程式碼包裝成函式,並加入 Python Decorator 就可以設定好排程任務,讓開發團隊可以快速地將排程設定導入原有的模型實驗程式碼中。
根據團隊需求選擇完套件後,接下來就是最後的重頭戲 — 如何將這些套件整合成一個實用的 MLOps 系統。以下將根據使用時的情境,將套件與功能像拼圖一樣,一片一片的拼湊起來,最終設計出專屬且實用的 MLOps 系統。
組合一個實用的 MLOps 系統
在本篇文中的「MLOps 系統的基本功能需求」這個段落,描述了機器學習開發專案的流程,大致可分成三個部分 — 從資料處理到模型驗證的「開發」、將開發模型訓練做排程處理的「自動化」、將模型上線使用的「部署」,其中各部分的設計、設備配置需求並不相同,因此在組合出一個實用 MLOps 系統時,就需要考慮到不同功能如何串接以及選擇適當的部署設備。此外,為了快速部署的需求,多數的功能或服務是部署在 Docker 容器中,讀者可以根據需求做調整。接下來,本文將以功能串接為主、設備考量為輔,帶領讀者了解各流程中 MLOps 系統的設計思路。
開發時會用到的功能設計
試想一下,如果沒有 MLOps 系統,開發團隊如何做模型開發?我們或許會在各自的電腦中,建立一個開發環境,然後各自將原始資料導入後,製作不同的訓練資料、模型,並將這些程式碼、資料、模型、甚至比較表格以檔案命名的方式區分版本,最後儲存在團隊的共同資料夾裡。如果要將這個流程優化,那麼,就需要改善我們的開發環境,利用前面提到的套件,滿足最初提到的基本功能需求。
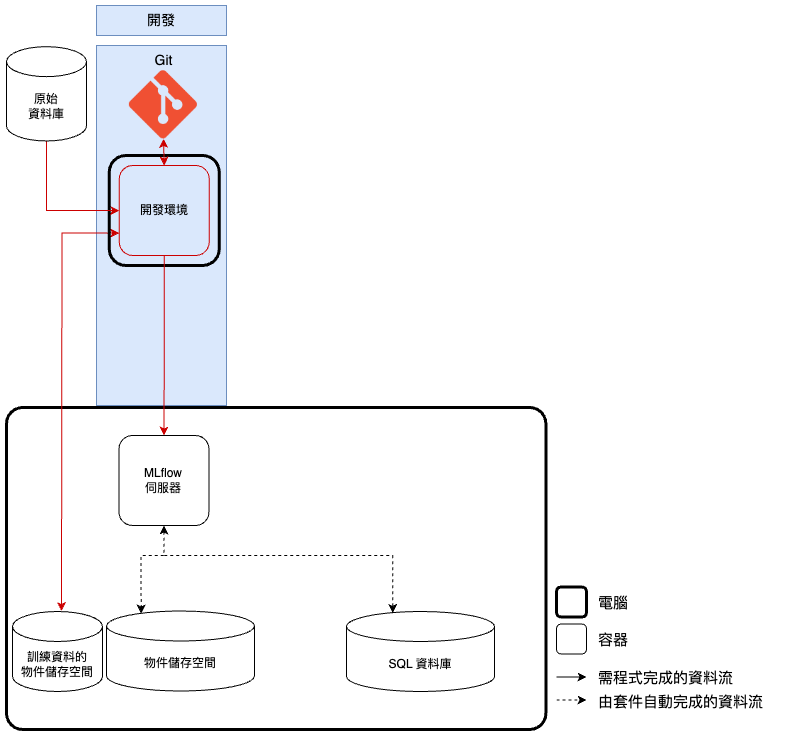
既然我們的目標是改善 開發環境,那麼開發時的功能設計(如圖二)便會圍繞著它做串接,而且通常可以延用原本的 GPU 開發環境 ,只需再串接 MLOps 系統的功能即可。依照模型開發的步驟,首先會希望原始資料可以透過 原始資料庫 統一管理,這個資料庫可以是一個外部服務,比如客戶的數據庫,然後將 開發環境 與其串接以取得原始資料。接著,會在 開發環境 做資料前處理,並將處理好的訓練資料透過 DVC 管理不同版本,DVC 會將各版本訓練資料儲存到 訓練資料的物件儲存空間 ,比如 MinIO 、 Amazon S3 、 Google Cloud Storage,以供團隊成員調用。 再下來我們會在 開發環境 執行模型開發,並將開發結果串接到 MLflow 伺服器 統一管理, MLflow 伺服器 會自動將模型檔、環境檔等「檔案」儲存到 物件儲存空間 ,將超參數、模型分數等「訊息」儲存在 SQL 資料庫 ,比如 Postgres 、 MySQL。最後,將模型開發的程式碼透過 Git 做版本控制,甚至上傳到 GitHub/GitLab 平台做共同管理。如此,便是依照專案流程完成了套件功能的串接。
| 開發時會用到的功能設計。 |
自動化時會用到的功能設計
在完成一個模型後,也可以選擇是否要加入自動化利用新資料定期更新的功能,如果當前的專案還不需要這項功能,想要直接將模型部署上線,那麼就可以直接跳過這一個段落,閱讀下一個段落「部署時會用到的功能設計」;但讀者如果希望加入這項功能,就我們接著看下去。
試想一下,如果希望模型可以利用新資料定期更新,在不導入 MLOps 的情況下,我們就需要定期將該建模流程人工執行一遍,非常麻煩。而導入 MLOps 後我們可以加入兩個功能,將建模流程利用新資料做排程執行,這兩個功能分別是:工作流程的排程功能 、 工作流程的執行服務 ,接下來筆者將分別就兩者的功能串接、設備考量來做說明。
工作流程的排程功能 主要負責將排程設定加入到開發完成的建模流程程式碼中,以供將來排程執行。要做到這點,如同圖三, 工作流程的排程功能 會需要從 GitHub/GitLab 取得開發完成的建模流程程式碼,接著人工加入排程設定後,將檔案上傳 Prefect 伺服器 做排程管控。 Prefect 伺服器 會如同 MLflow 伺服器 一樣,將程式碼、環境設定檔等「檔案」類型的資料存放在 物件儲存空間 以供排程時間到時使用,並將排程設定、紀錄等排程相關的「訊息」資料存放在 SQL 資料庫 。最終,我們也可以將加入排程設定的程式碼透過 Git 做程式碼版本控制,並交由 GitHub/GitLab 託管。
| 圖三:自動化時會用到的功能設計-工作流排程器。 |
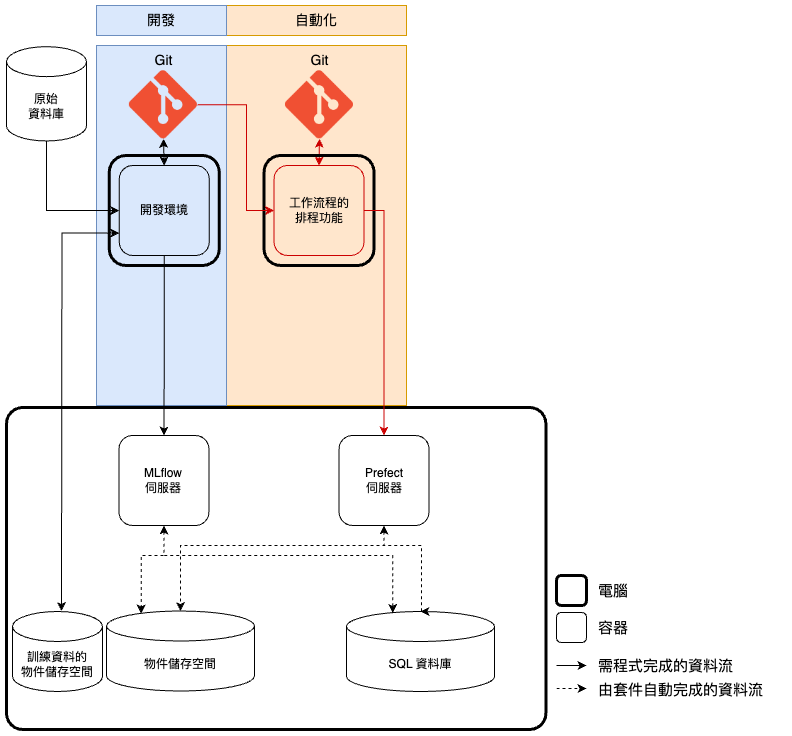
串接完 工作流程的排程功能 後,我們接著來討論其相關功能的部署設備考量。 工作流程的排程功能 主要任務是將設定好排程的檔案上傳到 Prefect 伺服器 ,所以不需要 GPU,可以在不影響開發的情況下,將其與 開發環境 部署在同一台電腦。不過值得一提的是, 工作流程的排程功能 在上傳排程檔案到 Prefect 伺服器 前會檢查環境中的套件是否包含程式碼所需之套件,所以筆者建議為 工作流程的排程功能 建立獨立環境,並利用環境設定檔下載套件,如此便能利用這個檢查的功能確認當前的環境設定檔有沒有缺失的套件,畢竟如果環境設定檔有缺失套件將造成後面很多流程無法正常運作。
接著是自動化會用到的第二個功能 工作流程的執行服務 ,其主要的任務是執行先前 工作流程的排程功能 上傳的建模流程程式碼。 如同圖四,工作流程的執行服務 會在排程時間到時,從 Prefect 伺服器 下載指定的建模流程程式碼,接著執行並將過程紀錄回傳到 Prefect 伺服器 。而因為 工作流程的執行服務 是執行建模流程,如同執行一次完整的開發,所以與 開發環境 相同,需要與 原始資料庫 、 訓練資料的物件儲存空間 、 MLflow 伺服器 串接。除此之外,因為 工作流程的執行服務 是執行特定的建模流程,所以可以設立多個 工作流程的執行服務 分別執行不同建模流程,甚至將一個建模流程拆成多個子流程,交由不同 工作流程的執行服務 執行。
| 圖四:自動化時會用到的功能設計-工作流執行代理人。 |

串接完 工作流程的執行服務 後,我們同樣來討論其部署設備的考量。一般來說,為了避免與開發用的設備搶資源,我們會獨立出幾台設備專門執行排程任務,而基本上因為我們可以讓不同 工作流程的執行服務 專門負責不同的建模流程,甚至其子流程,所以在考慮設備的時候會根據執行任務的需求做調整。大原則是,如果該 工作流程執行服務 需要訓練模型的任務,那就會部署在 GPU Server 上;而如果只是資料處理等任務,那就可以部署在相對低算力的電腦上。
部署時會用到的功能設計
部署時的功能主要就是要將模型推論的功能建立成 API 讓使用者或其他服務可以調用,這個部分與一般的 API 開發基本相同,開發團隊可以使用習慣的 API 架構來部署模型推論服務,比如 MLflow 的快速部署服務、 Flask 、 FastAPI 等。唯一要注意的是,模型推論往往需要較高的算力資源,所以需要部署在高算力電腦上,比如在(圖五)中,模型推論 的功能會從 MLflow 伺服器 取得指定模型、推論相關程式碼、環境設定檔,並部署在 GPU Server,最終 模型推論 再與 其他服務/API 做串接。
| 圖五:部署時會用到的功能設計。 |

總結
本文主要目的是帶著讀者從無到有設計出一個實用的 MLOps 系統,透過分享 MLOps 可以調整的細節、考慮的面向,希望讀者可以從中學習客製自己的 MLOps 系統。從現有團隊的基本功能需求出發,訂定團隊需要的功能,接著基於這些需求選取適合的套件,最終,根據使用情境、設備考量整合成一個完整而實用的 MLOps 系統。相信讀者在了解 MLOps 系統的設計概念後,可能會想要進一步了解如何實際部署一個 MLOps 系統,因此,在下一篇文章中,將以(圖五)為例,手把手教讀者部署一個實用的 MLOps 系統。
撰稿工程師:許睦辰




