
在AI專案的模型驗證階段,有許多工具可以協助團隊進行模型管理,主要目的都是在幫助團隊管理多專案與多實驗的狀況,可以輔助開發過程較為順利,所有的實驗數據都會被紀錄與備份,可以減少實驗數據遺失的風險。這些工具各有特色與強項,這篇將提供讀者幾個熱門工具建議:
從「AI專案開發一定要用MLOPs嗎?從專案流程看起」這篇文章中,我們知道在做模型建立、模型驗證的時候需要思考以下幾個問題:
- 多人協作如何紀錄分析每位協作者的實驗紀錄,如何從眾多的實驗紀錄中快速比較出預測效果最好的模型?
- 當實驗階段嘗試很多新特徵或是不同樣式,可能有時序或無時序的資料時,如何方便管理?
- 當發現有些實驗表現不錯,如何快速復刻該實驗?
因此,這篇文章將會和大家分享幾個有助於管理「紀錄實驗參數」、「模型訓練的 Loss 曲線」、「模型評估指標」、「儲存模型」等幾項實驗數據的好用工具,主要會介紹三個較多人使用與討論的工具: Tensorboard、Weight&Biases、MLflow。
(這邊以部分功能做示範,詳細更多功能可以參考每個工具的官方連結)

圖:ML流程圖
Tensorboard:
Tensorboard算是深度學習早期最著名的實驗管理工具,至今依然十分熱門,它主打幾個功能,如下圖所示:
- 視覺化的方式呈現模型訓練的Loss曲線和評估指標
- 視覺化的方式呈現模型結構圖(model graph)
- 能以直方圖檢視weight、bias或其他 tensor 等不同訓練次數的變化
- 除了能將更多參數、預測結果…等資訊視覺化,還能和各實驗進行比較。

圖片來源: https://www.tensorflow.org/tensorboard?hl=zh-tw,此圖片動畫分別說明Tensorboard的重要功能,1. 實驗數據紀錄(loss曲線、評估指標曲線…)、2. 測試資料集預測結果上傳、3. 模型圖(model graph)、4. 各權重數值分佈圖
- 請特別注意:Tensorboard 沒有儲存模型的功能,他是以紀錄實驗數據為主
如何在Python開發環境使用,以及程式碼需要如何撰寫:
-
工具安裝
pip install tensorboard -
本地端啟動:
tensorboard --logdir=<directory_name>directory_name默認是 logs 資料夾
- 在瀏覽器輸入 localhost:6006 可以開啟 Tensorboard UI 介面
-
程式碼撰寫:(以一個簡易的資料做示範)
- tf.summary.create_file_writer 建立一個儲存 log 的資料夾給Tensorboard使用
- tf.summary.scalar 將資料點寫入log檔
# Specify a directory for logging data logdir = "./logs" # Create a file writer to write data to our logdir file_writer = tf.summary.create_file_writer(logdir) for i in range(200): with file_writer.as_default(): tf.summary.scalar('accuracy', random() + 0.1, step=i)
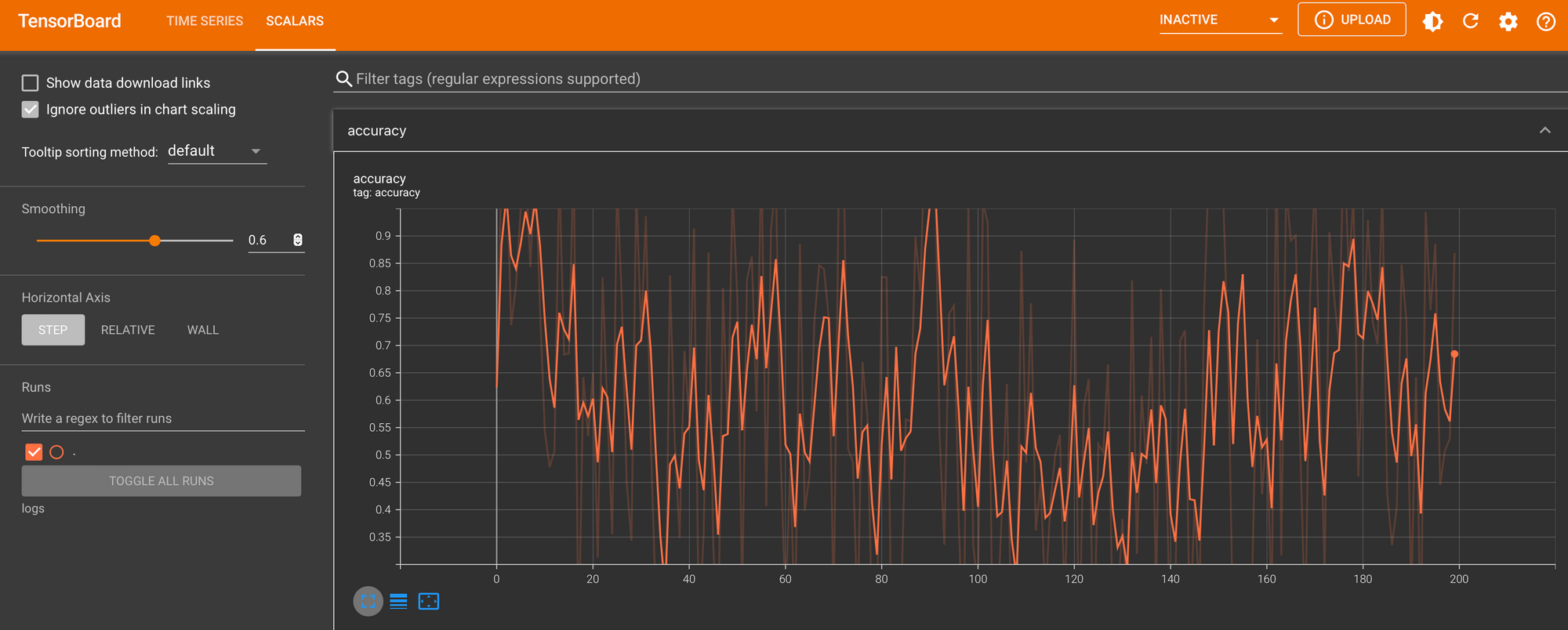
圖:tensorboard accuracy
- 上面範例示範了如何將數值寫入Tensorboard中,而後續在開發與模型版本紀錄也能以類似方式完成。
Weight&Biases:
- 大致功能與 Tensorboard 相同,但是整合了更多的深度學習(Llamaindex、Langchain、HuggingFace…)與機器學習(Scikit-Learn、XGBoost….)開發工具,目前觀察下來相較於Tensorboard有更精美的UI,及更好的視覺體驗。
- 支援上傳Artifact的檔案(訓練完成的模型,資料前處理的pickle檔….等等),以方便後續部署與版本控制
- 針對模型部署提供極為方便的功能,能將實驗最好的模型進行註冊,以利後續開發鎖定模型版本,已有許多文章分享使用方式。
- 注意:需要申請Weight&Biases 帳號,實驗紀錄會上傳至該帳號底下,需要確保網路順暢,因為需要將檔案上傳至Weight&Biases雲端儲存空間,每個人有免費的100G可以使用
如何在Python開發環境使用,以及程式碼需要如何撰寫:
1. 工具安裝:
pip install wandb -qU
2. 申請帳號 [https://wandb.ai/home](https://wandb.ai/home?_gl=1*17zy7d4*_ga*NjYxOTM1NjA5LjE2OTUwMDE0MTk.*_ga_JH1SJHJQXJ*MTY5NTExNTEyNS40LjEuMTY5NTExNTgxMy41NS4wLjA.)
登入後,點選[https://wandb.ai/authorize](https://wandb.ai/authorize) 取得 API key
3. 程式碼撰寫:(以一個簡易的資料做示範)
- 當程式執行到 wandb.login()時,會出現以下選擇,因為上一步已經先申請好帳號,所以這邊選 2

- 接下來會要求輸入API key,API key的取得方式可以參考以上第二步
```python
import wandb
wandb.login()
import random
# Launch 5 simulated experiments
total_runs = 5
for run in range(total_runs):
# Start a new run to track this script
wandb.init(
# Set the project where this run will be logged
project="basic-intro",
# We pass a run name (otherwise it’ll be randomly assigned, like sunshine-lollypop-10)
name=f"experiment_{run}",
# Track hyperparameters and run metadata
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
})
# This simple block simulates a training loop logging metrics
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# Log metrics from your script to W&B
wandb.log({"acc": acc, "loss": loss})
# Mark the run as finished
wandb.finish()
```

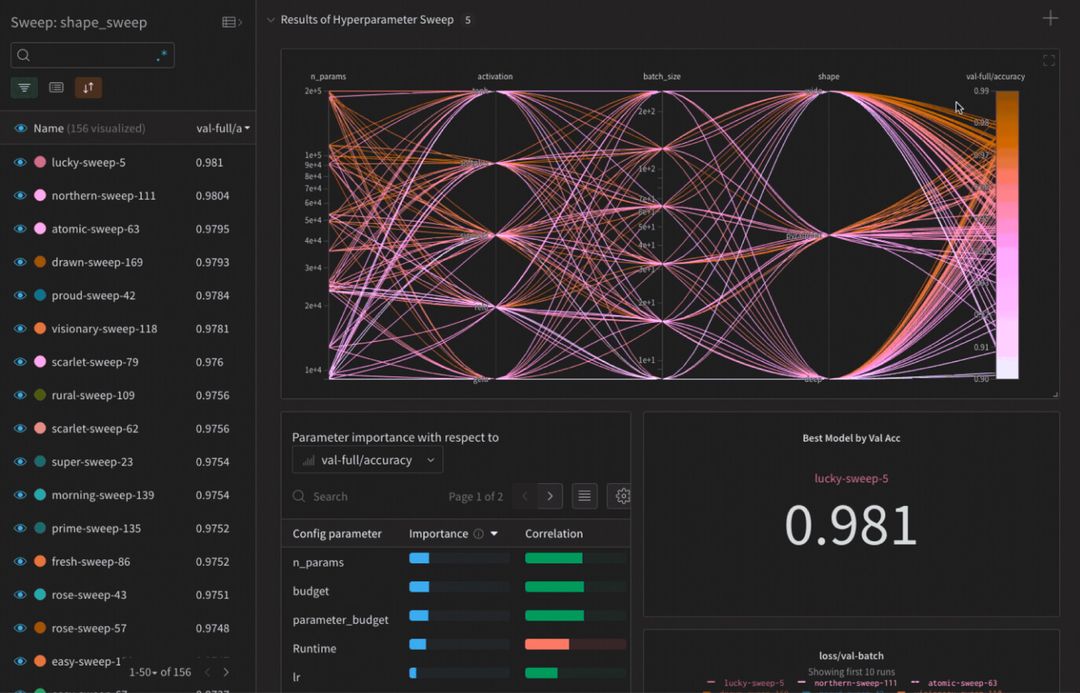
圖:Weight&Biases 結果
- 上面範例簡單說明如何將實驗數據上傳至Weight&Biases雲端空間中,提供大家在開發上的參考,並將這些整合至模型訓練流程中。
- 相較於Tensorboard他的功能有更加複雜,除了可以紀錄各項模型參數外,還有模型訓練loss(評估指標)曲線,還可以將模型上傳至雲端空間。
- Weight&Biases主要以雲端儲存這些訓練參數與模型,每個帳號有100GB的免費空間,並不是完全免費。
MLflow:
相較於Tensorboard與Weight&Biases,MLflow更著重於「公司內部的多人專案」的實驗管理上,主要讓工程師自己建立屬於公司內部的 MLflow 伺服器。MLflow著重在三個面向:專案、數據追蹤、模型,它可以使中小型團隊在免費的情況下輕鬆管理每個專案、實驗與模型,MLflow一樣有可視化的參數比較,也有搜索模型的功能,可以協助團隊在眾多的實驗底下,找出評估指標最優秀的模型。
如下圖所示:Experiments可以是團隊正在進行的專案,中間區域是該專案底下的各種實驗,可以紀錄實驗日期、實驗者、模型指標…等等,可以透過 “Sort” 找出評估指標最好的模型。
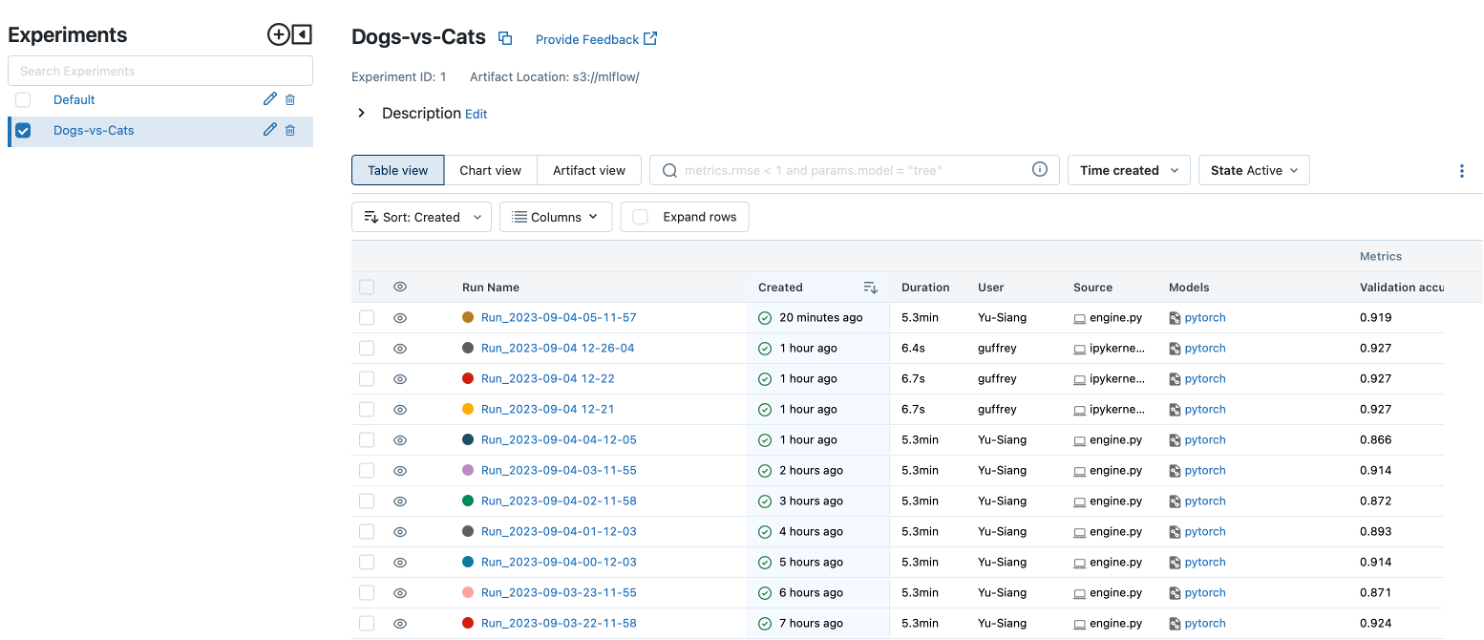
圖片:Mlflow ui介面
往下點擊每個實驗,可以觀察到紀錄的參數,從Metrics往下點擊可以可視化數值,在Artifacts可以儲存本次實驗的環境需求與模型,方便之後復刻(追蹤)結果與模型部署。
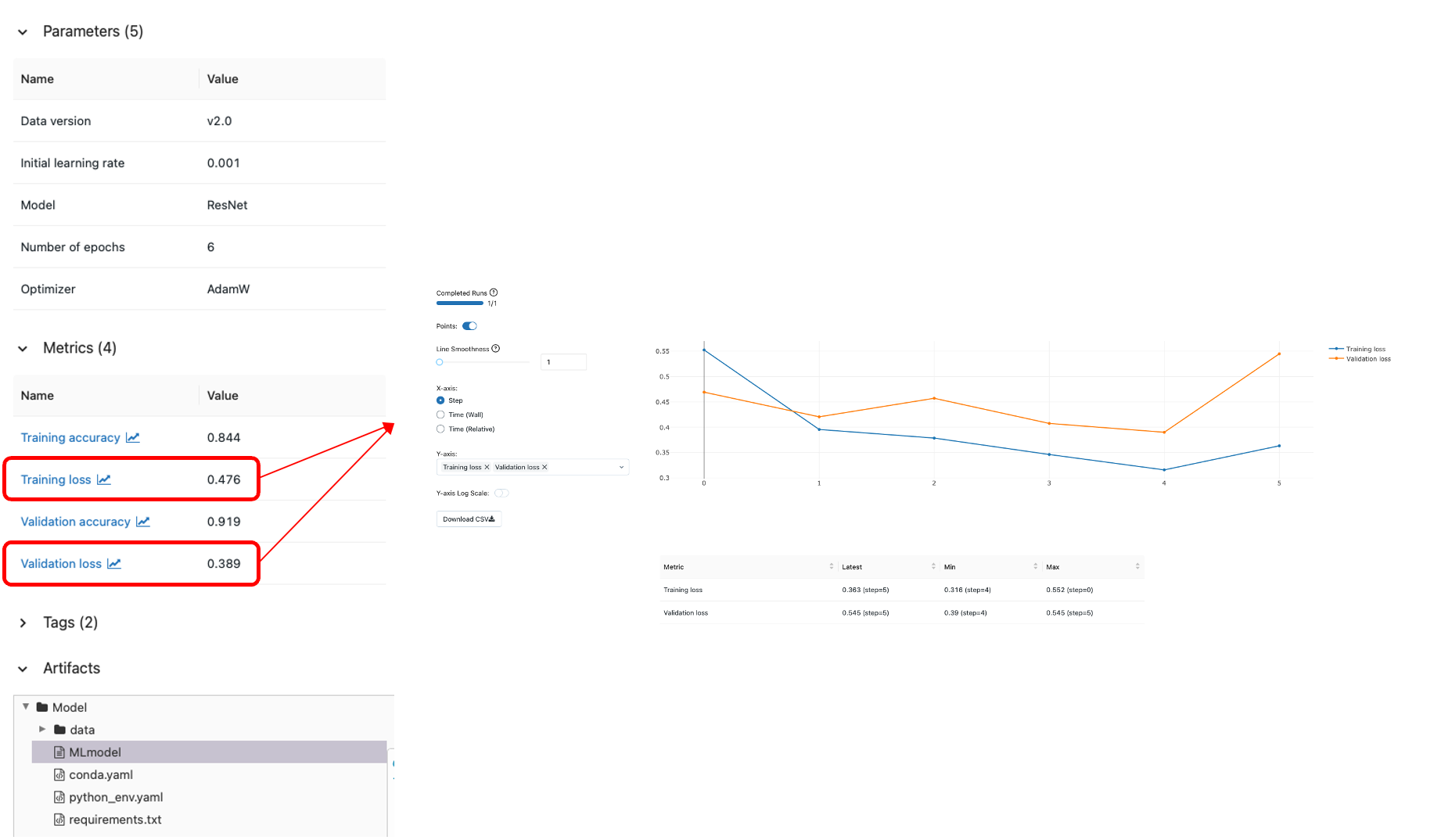
圖片:Mlflow實驗紀錄
** 注意如果要使用MLflow儲存模型(Artifacts)建議串接資料伺服器(s3, minIO….)
如何在Python開發環境使用,以及程式碼需要如何撰寫:
-
工具安裝:
pip install mlflow -
本地端啟動:
在終端機輸入:mlflow ui
-
程式碼撰寫:(以一個簡易的資料做示範)
- MLflow 追蹤位置 :mlflow.set_tracking_uri("http://127.0.0.1:5000")
- 依據不同資料的形式寫入MLflow
- 參數:log_param()
- 評估指標:log_metric()
- 檔案類型:log_artifacts()
import os from random import random, randint import mlflow from mlflow import log_metric, log_param, log_params, log_artifacts mlflow.set_tracking_uri("http://127.0.0.1:5000") if __name__ == "__main__": # Log a parameter (key-value pair) log_param("config_value", randint(0, 100)) # Log a dictionary of parameters log_params({"param1": randint(0, 100), "param2": randint(0, 100)}) # Log a metric; metrics can be updated throughout the run log_metric("accuracy", random() / 2.0) log_metric("accuracy", random() + 0.1) log_metric("accuracy", random() + 0.2) # Log an artifact (output file) if not os.path.exists("outputs"): os.makedirs("outputs") with open("outputs/test.txt", "w") as f: f.write("hello world!") log_artifacts("outputs")

圖:MLflow 範例
- 上面範例簡單完成將實驗數據寫入MLflow中,大家可以嘗試在目前的專案中加入MLflow輔助紀錄實驗數據。
- MLflow 的功能基本上與Weight&Biases相同,但MLflow如果要讓團隊統一開發使用的話,需要自建伺服器包含結構化資料庫與檔案資料庫;且長期使用上,需要團隊定期維護。
結論
這篇文章主要分享三個頗受好評的模型實驗管理工具,市面上還有很多類似的工具,這些工具各有特色與強項,團隊可視情況選擇好維護的工具。
這些工具的目的都是在幫助團隊管理多專案與多實驗的狀況,可以輔助開發過程較為順利,所有的實驗數據都會被紀錄與備份,可以減少實驗數據遺失的風險。
這邊提供讀者選擇工具上的建議:
- Tensorboard : 如果是個人使用,它可以簡易快速實現模型實驗紀錄的功能,它有優秀的各種參數紀錄功能與模型架構紀錄功能,但如果要多人協作就不建議使用Tensorboard。
- Weight&Bias : 這個工具主要是以多人協作為主的開發平台,會將實驗紀錄上傳至雲端中,這樣可以減少團隊開發上的系統維護,只是要注意免費使用空間是100GB。
- MLflow : 這個工具如果要使團隊一起開發協作,需要自己建立伺服器,需要團隊維護,但好處是可以將實驗紀錄儲存在公司內部,MLflow 工具是開源且免費。
下一篇文章將與大家分享 MLOps-資料管理工具,還有哪些工具可以協助我們在開發與部署時方便管理資料
參考文獻
1.初探mlflow-tracking-保持ml實驗的可追溯性與可重現性-
2.Weights & Biases — ML 實驗數據追蹤
(撰稿工程師:顧祥龍)




