
MLOps是近來極為熱門的單字,在許多討論專案的文章或是論壇中都可以聽到,不過,實際上對於專案的幫助是什麼呢?這篇文章希望透過宏觀的角度來介紹MLOps,以及不管是完全沒接觸過AI、或是正開始學習AI的學生,甚至是熟稔AI技術但正在觀望是否要導入MLOps的工程師或主管們,都希望能透過這篇文章來讓你能更了解它。
首先,先快速介紹 AI 專案開發流程,對於開發流程已經熟稔的讀者,可以從第二段落
一、機器學習(ML)開發流程快速介紹
| 圖一 |

如圖一所示,在選定一個適合以 AI 解決的題目後,我們會進行資料的前處理與模型開發。當模型完成開發後,則會進行驗證,如果模型通過驗收可上線的標準,就會進行佈署上線。
那麼,各個步驟的主要功能又是什麼呢?以下我們試著用簡潔的文字說明:
- 定義題目:將題目轉化成能用 ML 解的題型,並決定驗證標準。
- 資料前處理:針對資料的處理都會在這一塊,目的在於透過資料前處理,讓模型學習到更好的成績。
- 建立模型:包含選擇模型、調整超參數。
- 模型驗證:評估模型表現是否達到要求。
- 佈署上線:將 ML 模型整合到產品之中,此階段可能會需要軟硬整合或多項專業結合,才能使模型產品化。
如果在模型驗證階段發現模型效果不如預期,則可能會回到資料前處理或建立模型的步驟重新調整,重複這樣的步驟,直到得到一個可行的模型;最差的情況是回到定義題目,重新把題目訂得更簡單、更容易完成。所以可以得到以下這張圖:
| 圖二 |

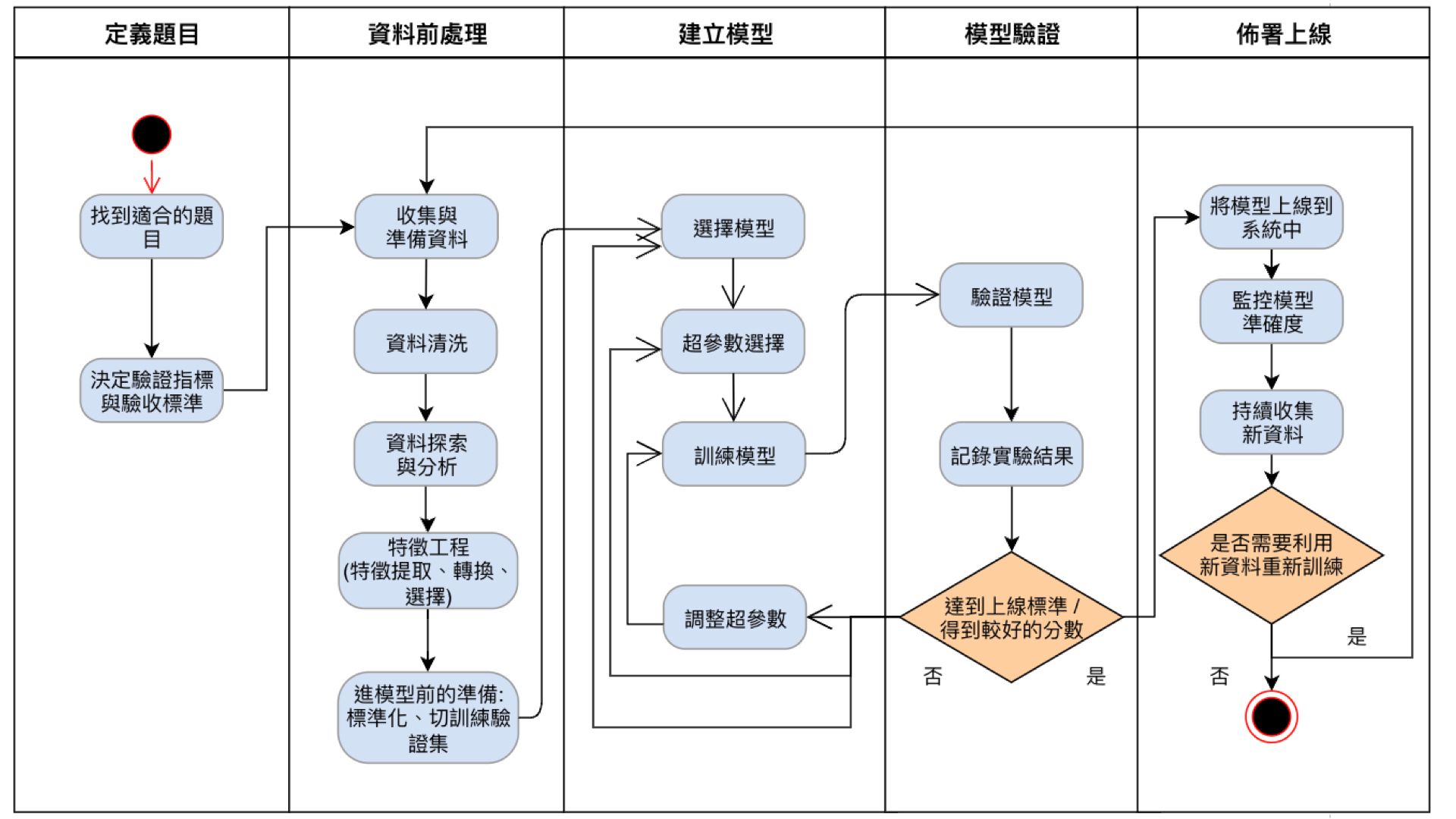
接著,我們將每一個區塊拆成較細的步驟(如圖三),這裡要特別注意,模型驗證如果沒有得到較好的分數,可能會回到資料前處理的階段,再次重新進行。但是,這裡為了讓構圖看起來清晰,並未在圖中標明此細節。我們將在第三部分繼續針對此圖進行講解。讀者若想對每一項目的細節深入探討,可以自行搜尋相關內容細節,而這篇文章主要針對 MLOps 部分仔細說明。
| 圖三 |
二、MLOps 定義
MLOps 是 ML (Machine Learning,機器學習) 加上 DevOps 的概念;DevOps 又是由 Development (開發) 加上 Operations (維運) 所組成的,也就是說「MLOps 希望將 DevOps 的精神結合到 ML 的開發上」,從 ML 的開發、驗證到佈署上線,都能自動化完成並快速維運產品。
再看一下由CDF基金會(Continuous Delivery Foundation), 在[MLOps 2022的白皮書]MLOps 2022的白皮書所提到的,MLOps 可視為 DevOps 的擴展,MLOps 應被視為一種持續管理產品中機器學習模組的實踐,其整合了 ML 商業化時所需應用的技術與非技術元素,並在市場上保有競爭力且生存下去。
簡言之,「只要你的產品與 ML 相關,且持續維運,就會和 MLOps 有關係!」以上的敘述可能還很抽象,請試想以下兩個例子:
- 公司有一個持續不間斷運作的瑕疵檢測模型,因為每週都有新的資料產生,必須周周更新模型。
- 現在有一個能用來辨識人臉的 app,當收集到夠多用戶所上傳的人臉照時,就會利用這些資料繼續訓練,只要模型準確度比前一次高,就重新佈署新的模型到產品上。
從上術例子可以發現,如果以目前傳統的機器學習流程開發的作法,需要讓這個流程能自動週期性的更新,並確保新的模型較為出色。此外,必須能在需要回頭檢查過去實驗數據時,輕易且方便地達到目的,如果上述其中一項符合你的狀況,那就需要使用到 MLOps。
三、如何著手將MLOps導入到現有專案呢?
以<圖三>為例,我們可以讓每個流程都變成自動化。以下分成兩種場景來說明有哪些部分可以利用MLOps的工具讓流程更快速便捷,場景為實驗階段及佈署階段:
a. 實驗階段
此階段是屬於模型正在開發研究的階段,所以在資料處理、模型建立上都還沒有選定較穩定的特徵、模型、超參數等等。同時因為有很多的超參數組合需要嘗試,或是有好幾個開發團隊成員需要同時使用到運算資源,因此需要排程管理,讓我們的實驗能夠按照時間分配逐步執行。
| 圖四 |
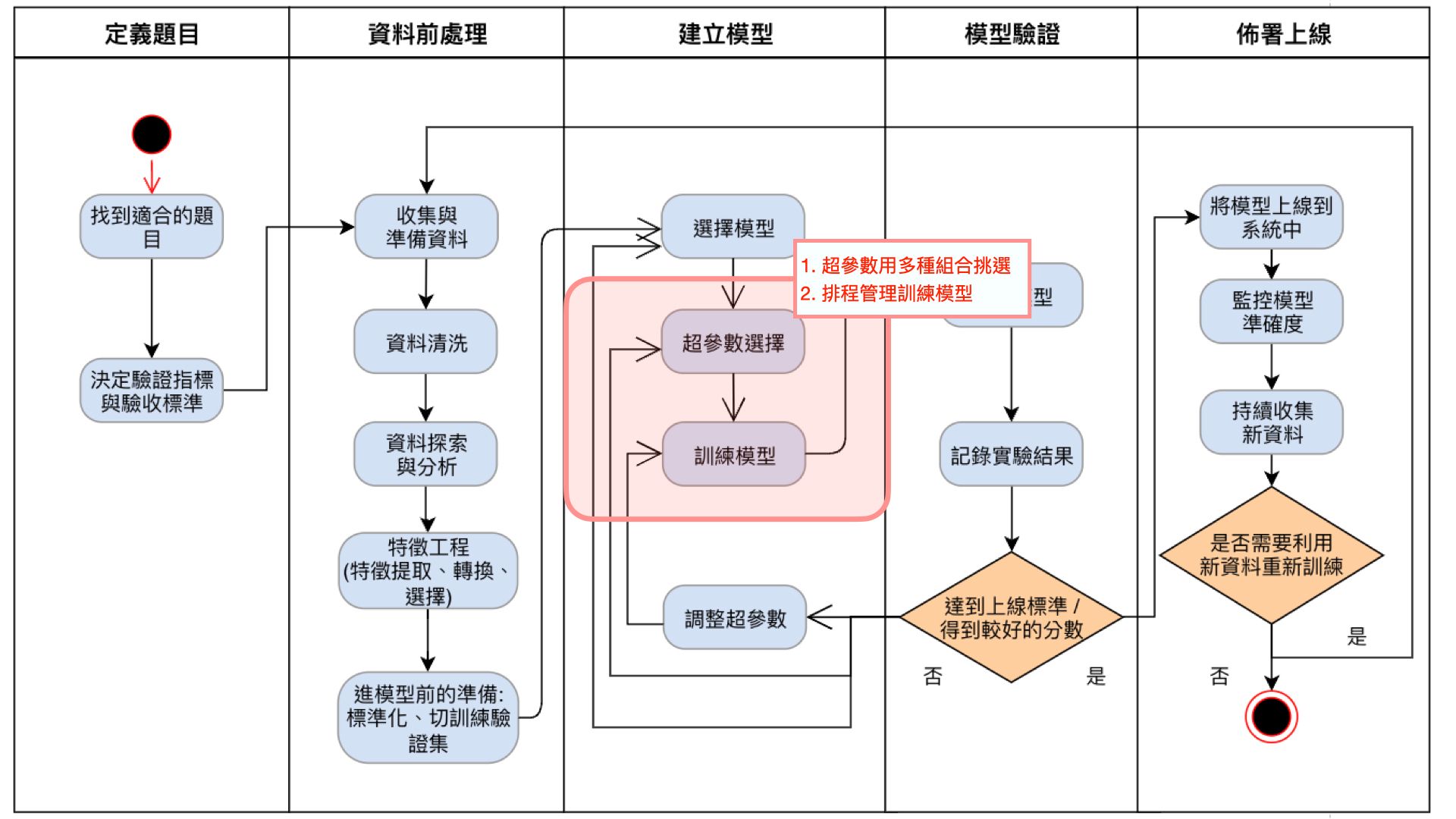
當實驗完成後,我們會需要將實驗結果記錄下來,一旦未來有新的模型實驗,然後回頭比較哪個實驗結果較好,並挑選出最優的選擇。這時候就需要有版本記錄的功能。
| 圖五 |
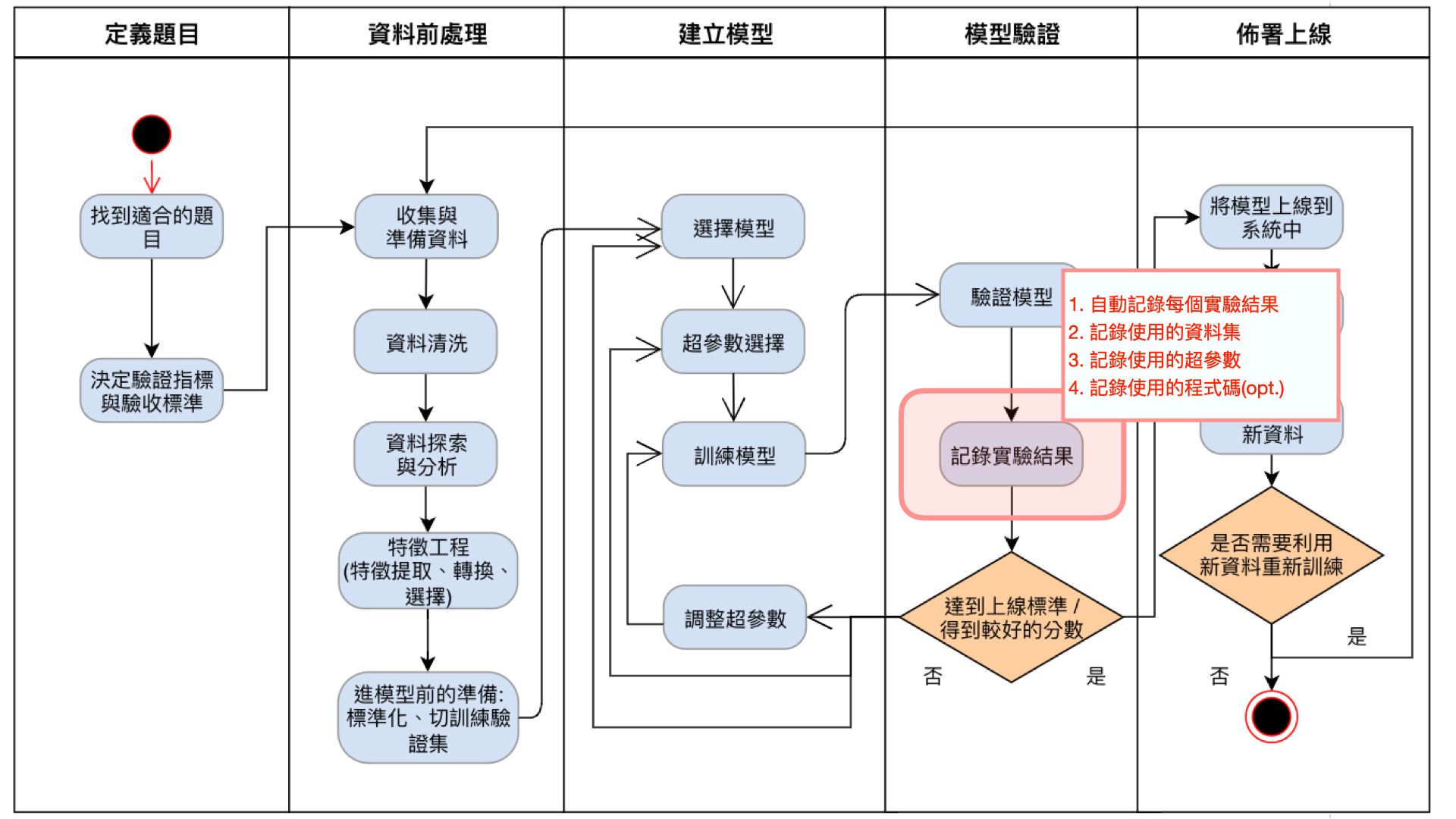
b. 佈署階段
當專案經過一番實驗後,會得到較穩定的特徵、模型與超參數,這時就需要佈署上線,並期許能在固定時間內針對新資料進行模型重新訓練,而在這階段利用新資料進行重新訓練是非常重要的功能。
| 圖六 |
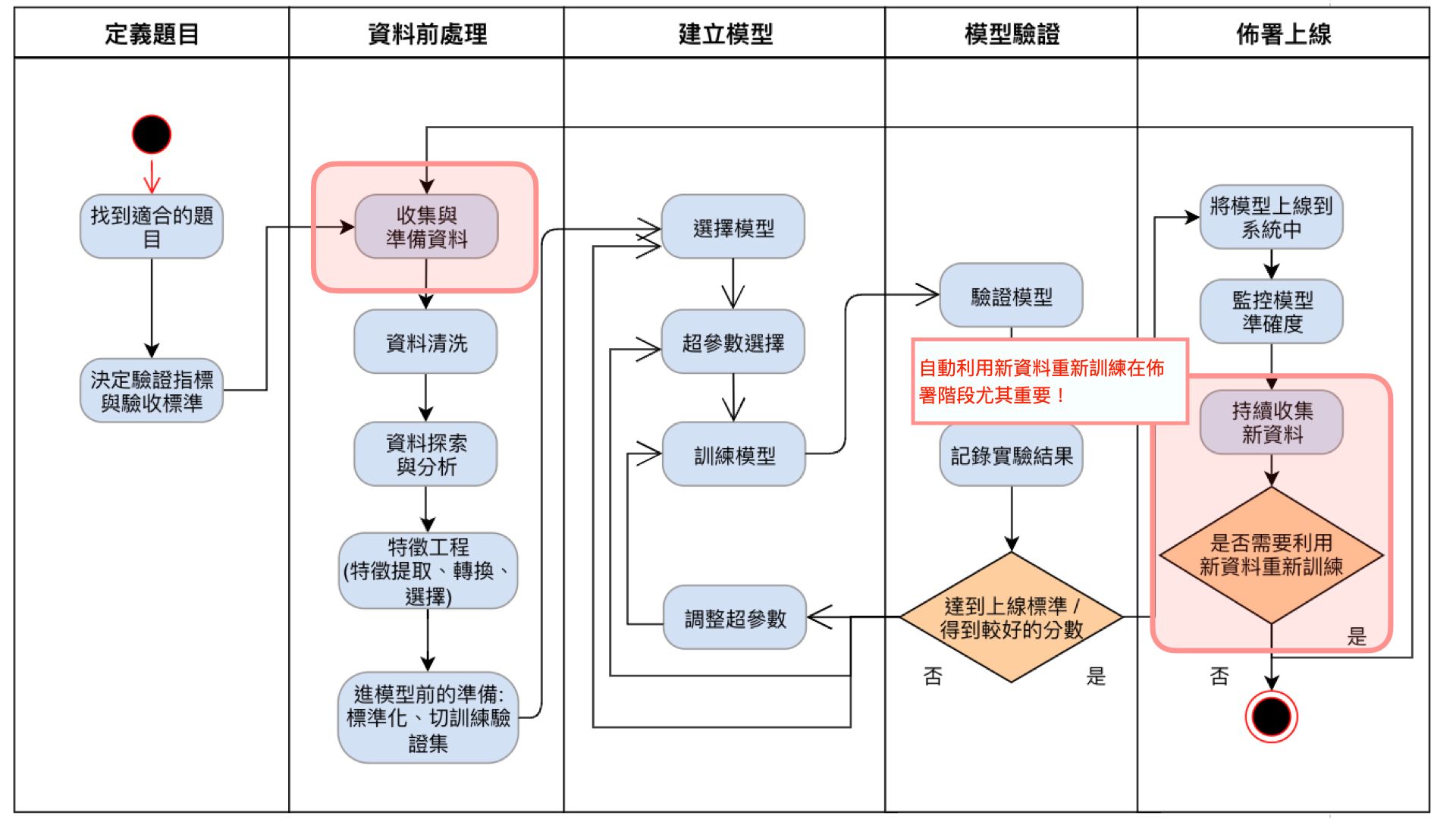
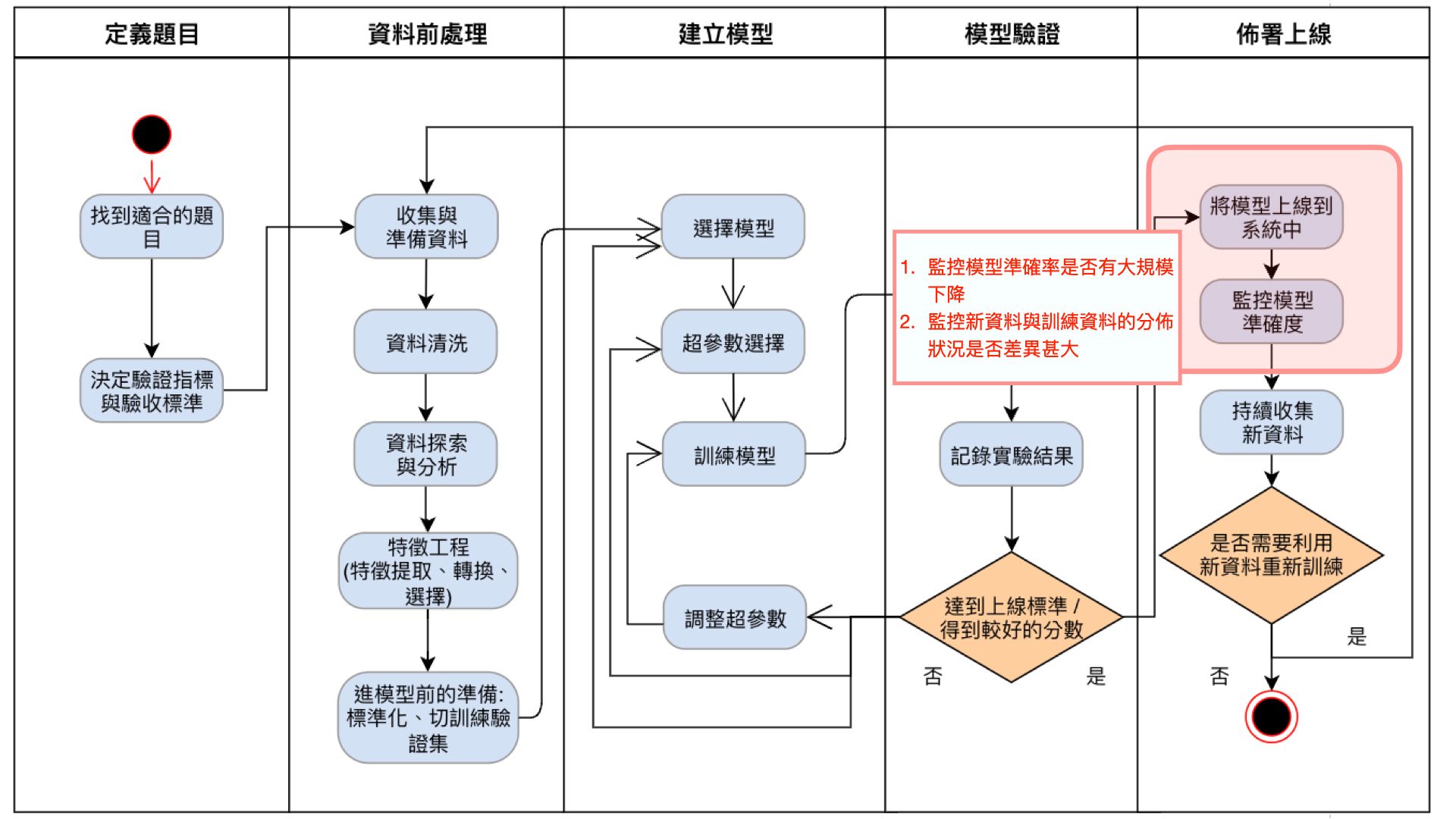
在上線後我們也能利用 MLOps 的工具來監控模型的準確率是否有下降,或是收集的資料分佈狀況與過去的訓練資料差異甚大,這都能讓 MLOps 來監控,並且提供預警!
| 圖七 |
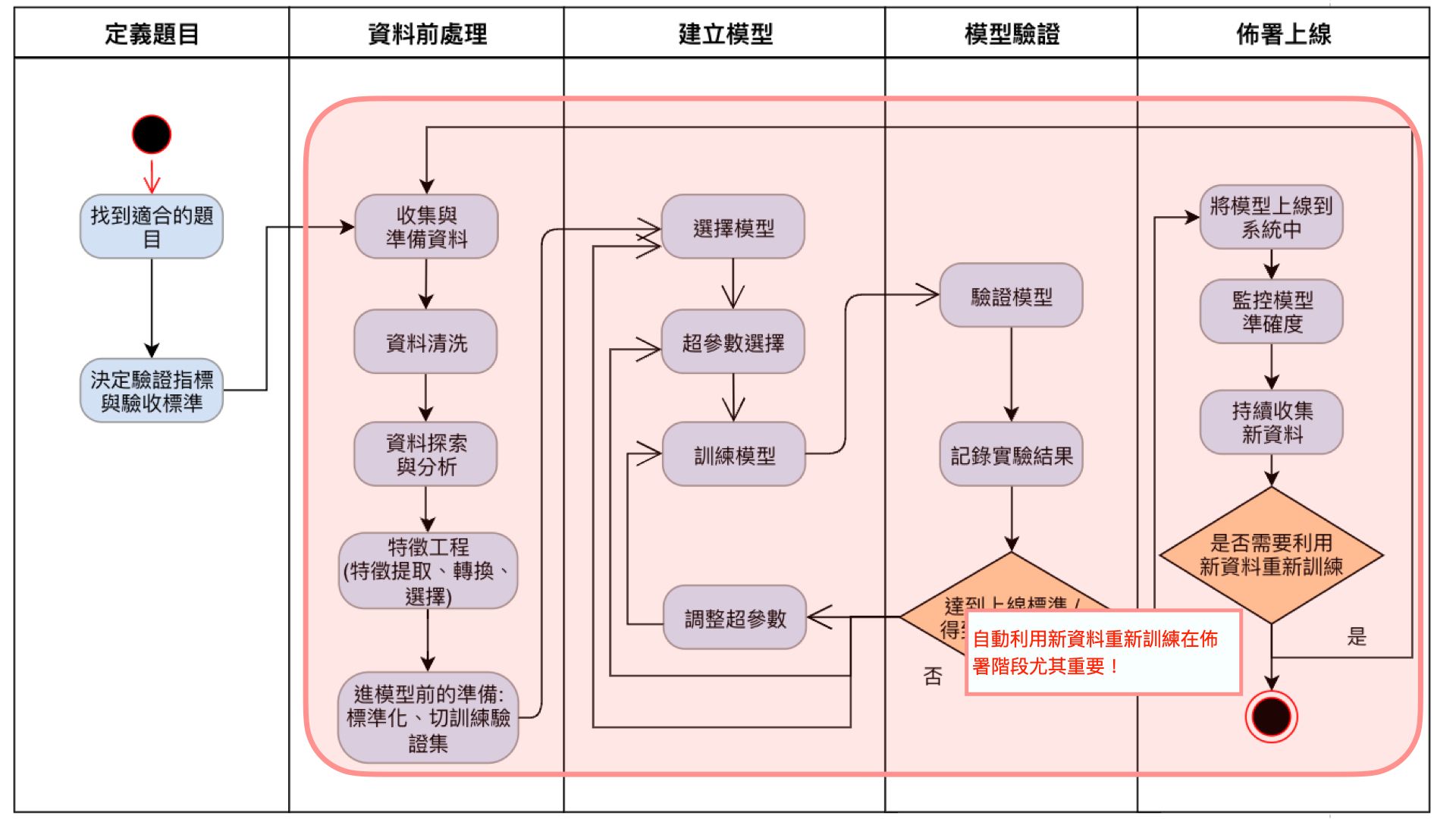
在完整的 MLOps 流程導入後,大多數的流程都將由 MLOp 工具自動化完成(如紅框所示),而且最後都還會讓工具自動排程幫忙重新訓練新資料,當問題發生後還能提供預警。
| 圖八 |
其他注意事項
CDF 基金會 MLOps 小組的白皮書中不斷提到,*MLOps is not "putting Jupyter Notebooks into production environments".* 因為 Jupyter Notebooks 在開發時非常地好用,但這類快速開發工具為了實現「快速」這件事,而犧牲掉一些需求,如可維護性、可測試性、可擴展性等。原文可在此連結中找到。所以在佈署階段時,讀者可以嘗試將現行 Jupyter Notebooks 開發環境的程式碼換成單純的 py 檔,再交由 MLOps 工具執行。
在資料庫的使用與管理上,由於訓練資料會不斷更新,因此需要一個資料庫來管理與記錄每個版本的變異。在版本控制上,如果需要對程式碼進行版本控制,多數開發者會使用 git 來管理,上傳的位置除了 github、gitlab 外,也可以考慮使用自行架設的資料庫做為存放位置,同樣也有 MLOps 的工具可以達成這些任務。
四、結論
看完以上導入前後的差異後,簡單做個結論:
若能成功導入 MLOps,其優點為:
- 讓 ML 流程從資料到模型到上線的流程全自動化。
- 妥善達到資源管理與流程分配目的。
- 有效率的紀錄每次訓練版本的超參數、實驗結果、資料使用版本。
- 團隊使用統一工具、平台開發,減少整合困難與時間成本。
不過,導入 MLOps 也有缺點為
- 有學習新工具的陣痛期。
- MLOps 工具眾多,在挑選適合自己團隊的工具時,需要耗費不少時間成本進行搜集資料。
最後,這篇文章只說明 MLOps 如何改變既有的 ML 開發流程,至於有哪些 MLOps 工具可以使用,後續將有更詳細的 MLOps 工具介紹文章。
在未來,ML 將會改變現在的生活型態,諸多的產品應用也會因應 ML 而生,相信 MLOPs 的精神也會越來越被重視,甚或成為未來顯學,現在開始理解一定不遲!
(撰稿工程師:王維綱)
想了解更多 MLOps 的詳細內容,請參考【AI CAFÉ 線上聽】AI 專案一定要用 MLOps 嗎?那些我們閃過的坑




