
在本系列文的連載之一裡,我們說明了人類的語言系統具有其天生的內部結構,我們可以用這個內部結構來設計一個專門計算「語言結構」的程式,讓資訊系統仿照人類處理語言的過程來推算出語言的結構。
補充閱讀:
[連載之一] AI 時代的語言學:結構
[連載之二] AI 時代的語言學:語意
在系列文二裡,我們則進一步利用這個結構來說明「語意 (semantics)」也可以這麼計算,並且和 LLM 做了初步的比對。然而,在系列文二裡,我們沒有特別說明「語意」的計算程式,大概會長什麼模樣。
本篇就來說明,我們要利用系列文二裡的「形式語意學 (Formal Semantics)」的表示式來計算語意,程式大概會長什麼樣子…

任何科學領域的研究,第一個要回答的問題永遠是「你的最小單位是什麼?」只要最小單位搞錯,那麼這個研究的結果大概也是…不太科學的 (客氣地說)。就像電影《鍋蓋頭 Jarhead》裡的教官在射擊訓練場特別指出的「報距離的時候,選擇適當的最小單位!不要用你的屌當計算單位,因為它太小了!」
因此,當早期的 embedding 一路選擇「詞 (word)」、「字符 (character)」直到比字符更小的「token (符元)」這樣愈來愈小的方向時,我們從「詞 (word)」就開始延伸到形式語意學的計算符號上面。

同樣地,我們用「約翰在波士頓租了一間房子」為例,以「詞」做為 embedding 的最小單位,就會將以下的內容做為訓練材料,一共有 6 個元素:
[“約翰”, “在”, “波士頓”, “租了”, “一間”, “房子”]
而如果是以「字符」為 embedding 的最小單位,原本的「約翰在波士頓租了一間房子」,就會變成這樣的訓練內容,一共有 12 個元素:
[“約”, “翰”, “在”, “波”, “士”, “頓”, “租”, “了”, “一”, “間”, “房”, “子”]
而如果是以 token 做為 embedding 的最小單位,一個中文字符大概會是三個 token,整個句子就會變成像以下的 36 個元素:
[“\xe7”, “\xb4”, “\x84”, “\xe7”, “\xbf”, “\xb0”, “\xe5”, “\x9c”, “\xa8”, “\xe6”, “\xb3”, “\xa2”, “\xe5”, “\xa3”, “\xab”, “\xe9”, “\xa0”, “\x93”, “\xe7”, “\xa7”, “\x9f”, “\xe4”, “\xba”, “\x86”, “\xe4”, “\xb8”, “\x80”, “\xe9”, “\x96”, “\x93”, “\xe6”, “\x88”, “\xbf”, “\xe5”, “\xad”, “\x90”]
但我們使用邏輯表達式,例如:
FUNC_在(LOC_波士頓, ASP_了(VERB_租(PSN_約翰, CLA_一間(ENTY_房子))))
整個句子將會變成以下的模樣進行 embedding 的訓練:
[“FUNC_在”, “(”, “LOC_波士頓”, “ASP_了”, “(”, “VERB_租”, “(”, “PSN_約翰”, “CLA_一間”, “(”, “ENTY_房子”, “)”, “)”, “)”, “)”]
共有 15 個元素。這是我們在計算向量時,第一個和主流「字符/詞彙/token/byte」做為嵌入基本單位的最大不同之處。
有趣的是,我們利用形式語意表示式,可以得到最大的好處就是「主動語態和被動語態將有一樣的語意表示式」。
也就是說,「有一間在波士頓的房子被約翰租了」這個句子的語意表示式和「約翰在波士頓租了一間房子」是完全一致的。
以這些元素來計算詞向量還不夠,因為詞向量對語言結構不敏感,頂多只能呈現「這個句子在高維空間中大概分佈在哪裡」的特徵。因此我們要再加上能對語言結構敏感,並在計算過程中保持序列結構的 pairwise alignment 將每個句子彼此之間的相似程度計算。
大概會像這樣子:
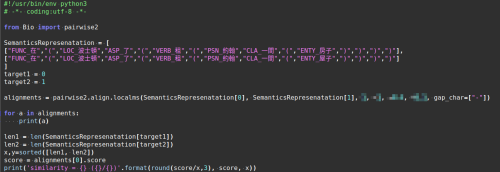
- [註] 涉及機密處的參數予以遮蓋,請見諒。
- [註] 不同詞性的加權,可加在 alignments 這一行之後處理。
- [註] 不同層次的 negation_function 的處理,也可以在這一區塊處理。
這麼一來,這兩個只差了「房子」和「屋子」一個詞的句子,相似度可以計算出為 92%。對齊的過程視覺化後如下所示:

最小單位是形式語意學提供的,而對齊的算法是 naive pairwise algorithm (常用於基因比對)。該演算法的物理意義在於「找出兩個 DNA 序列」中相同排列的段落。
若兩個物種的 DNA 序列「相同的段落愈多,且兩兩相同段落之間的位移愈少」,則這兩個物種在分子生物的層面上愈相近。
綜合地說,在 NLP/AI 的技術發展史裡,早期使用「字符」,中期使用「詞彙」,前者會遇到「雜訊過多 (多一個「的」,少一個「啊」,都會被演算法視為是不同的句子),後者則會遇到「主動句 (我看到他匯錢) vs. 被動句 (他匯錢被我看到)」明明意義一樣,但卻被演算法視為不同句子的問題。近期使用 token/byte 的 LLM 則會遇上無法呈現語言中的邏輯因果關係的問題。
而我們可以利用語言學,先把所有的句子都先收斂成「語意表示式」,藉由:
FUNC_在(LOC_波士頓, ASP_了(VERB_租(PSN_約翰, CLA_一間(ENTY_房子))))
這樣的結構,不論其原文是「約翰在波士頓租了一間房子」或是「約翰租了一間波士頓的房子」甚至是「波士頓的一間房子被約翰租了」都是一樣的結構,再交給 embedding 和 pairwise algorithm 計算以後,就能得到「上面三個句子都是一樣的語意」的結論了。
本文取得《卓騰語言科技 - 科普分享空間》授權轉載,原文詳見AI 時代的語言學 - 連載之三:實作


