

最近轟動武林驚動萬教的熱門話題莫過於出口成章文采粲然的chatGPT了。甚至有人開始擔心強AI世紀已然降臨,人類恐怕越來越難混了。不是嗎?
已經有教授擔心「對於教育專業來說,以短文(essays)作業來教導學生的方式可能已經到了末日[註1]。」連原先自覺難以被取代的谷歌都發出紅色警戒,提醒內部提高警覺, 我們這些平凡人怎麼辦?
夠嚇人吧?但本專欄的特色就是「如果一刀不夠,那就再補一刀。」
才說谷歌發出紅色警戒,接着馬上聽到谷歌宣佈,參數量高達 5400 億的 Med-PaLM 參加美國醫生執照考試,經過盲測,人類專家認定 Med-PaLM 在理解、檢索與推理能力 幾乎達到人類醫生的水準,實現史上 AI 最高分。[註2]


「又是完全取代作家,又能勝過人類醫生,那真完蛋了!」聽人們說得這般言之鑿鑿,就問你怕不怕!
寶寶當然怕,怕得不得了,還是哄不好的那一種。
我們先回到 chatGPT,這個神器的原型來自於 OpenAI 在 2020 年發表的 GPT-3,生成預訓練語言模型 (Generative Pre-Trained model),目前來到第三代,參數量是 1750 億個。這樣是多還是少?實際上非常多,不過,才不到一年,谷歌又在 2021 年發表了新的模型 Google Switch,規模達到 1.7 兆參數量。[註4]
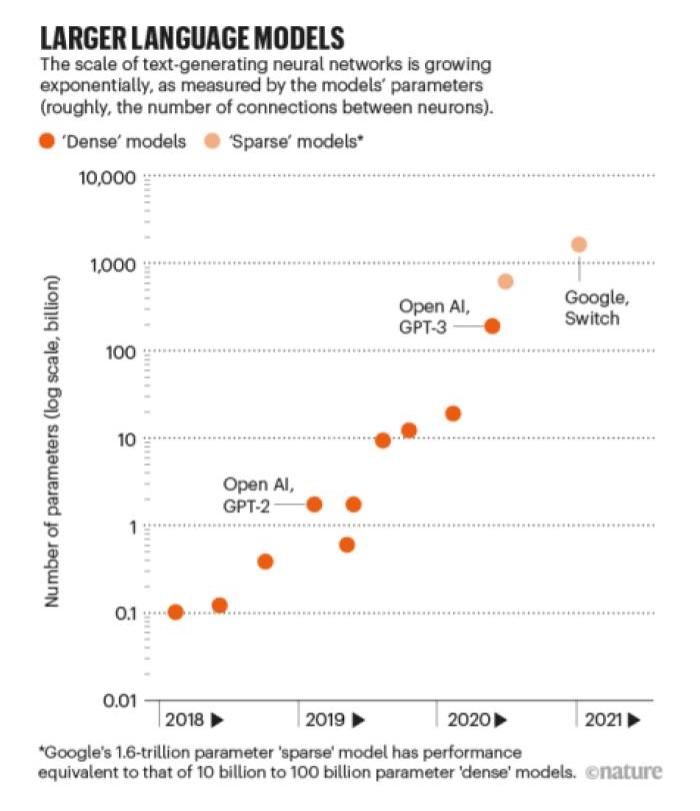
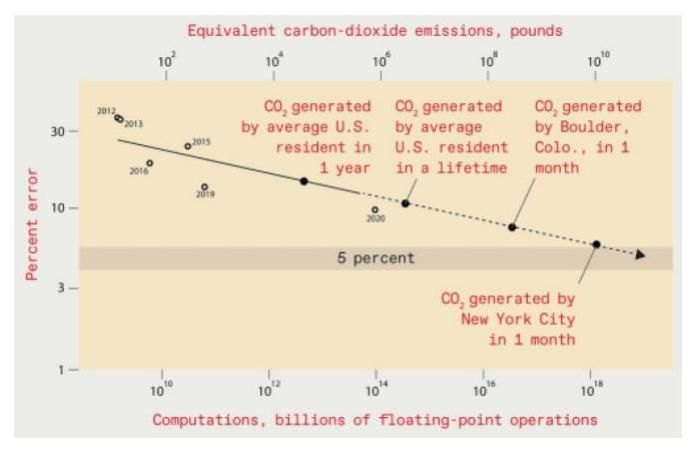
簡單地說,模型軍備競賽已經發展到一個不可思議的地步。這些模型都不是天上掉下來的餡餅,而是靠著一部又一部高性能運算設備堆出來,說起來就是金山銀山。研究 [註6]指出,「現在的 AI 已經接近人類社會承受能力的邊緣了。」到底有多誇張?如果要訓練一個錯誤率低於 5% 的影像識別模型,先不談訓練費用,光是訓練過程所產生的碳排放就幾乎相當於整個紐約市一個月的排放量。按照紐約市政府 2020 資料顯示,全年排放約 34 百萬噸[註7],換算起來單月排放 2.8 萬噸,將近 9 億度電。如果還要達到一般人隨口說說的 99% 正確率呢?看起來,可能五倍不止,細思極恐。
讓我們回到主題,我們花了這麼大力氣,就為了讓 AI 有文化。有文化的 AI 可以帶來什麼?總是笑容滿面的科技樂觀主義者說,「這樣我們就可以擺脫無趣的漫長學習過程,而將有限的心力投入在更多人的共同福祉上。」 chatGPT 又是怎麼想的呢?

我們不禁要問 chatGPT 一個問題,「臺灣資源有限,應該也加入開發大型語言模型的行列嗎?」
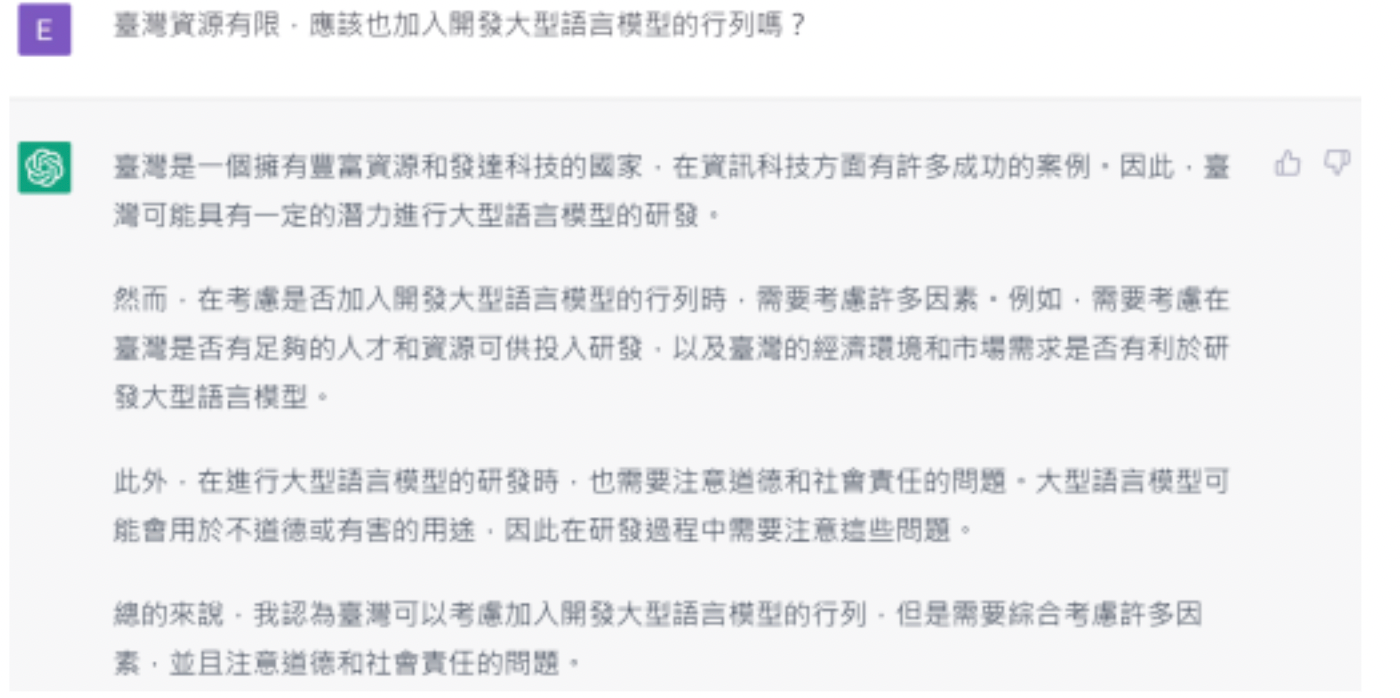
回答中規中矩,密不透風,既說了好話,也提出關注,誰曰不宜?頗有士大夫之風。然而,發展 AI 的地方可不止臺灣,中國也正在快速發展,而且挾着巨大資源與堅決意志,絕對不可小覷。

當 chatGPT 出現,許多人認爲強 AI 世紀就要來臨了,任誰都可以舉出一百個成功案例, 說明 AI 有多聰明,但聊天是一回事,實際應用是另外一回事,在實際應用中,我們真正關心的,不是 AI 對了多少次,而是錯的那一次有多嚴重。換句話說,對於 AI 的未來,也許我們應該換個角度發問,「我們能不能有效配置與分散風險?」而這個問題又將歸結到另外一個同樣重要,但不那麼綜藝化的題目——「可信賴 AI 」。
沒有任何一個人有能力檢視並驗證深度學習模型的參數,那到底要如何才算是「可信賴 AI 」?

最後一個問題,你猜這篇是誰寫的?
參考資料:
1.Stokel-Walker, C. (2022, December 9). Ai Bot chatgpt writes Smart Essays - should professors worry? Nature News. Retrieved December 28, 2022, from https://www.nature.com/articles/d41586-022-04397-7↩︎
2. Singhal, K., Azizi, S., Tu, T., Mahdavi, S. S., Wei, J., Chung, H. W., Scales, N., Tanwani, A., Cole Lewis, H., Pfohl, S., Payne, P., Seneviratne, M., Gamble, P., Kelly, C., Scharli, N., Chowdhery, A., Mansfield, P., Arcas, B. A. y, Webster, D., … Natarajan, V. (2022, December 26). Large language models encode clinical knowledge. arXiv.org. Retrieved December 29, 2022, from https://arxiv.org/abs/2212.13138↩︎↩︎
3. Zhou, H.-Y. (F. (2022, December 27). Finally, it comes... med-palm (540-billion parameters) achieved 67.6% on MedQA USMLE (United States Medical Licensing Examination) compared to 60.2% achieved by codex (175-billion parameters).for reference, the passing and expert scores of human beings are 60.0% and 87.0%. https://t.co/2rfhnc3nrt. Twitter. Retrieved December 30, 2022, from https://twitter.com/HongYuZhou14/status/1607638208850059264? ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1607638208850059264%7 Ctwgr%5E943cc7bfd0175bb77db153dfb49edfbc31cce36c%7Ctwcon%5Es1_&ref_url=https% 3A%2F%2Fwww.techbang.com%2Fposts%2F102802-google-med-palm-doctor↩︎
4. Fedus, W. (2021, January 11). Switch Transformers: Scaling to Trillion Parameter Models with. . . arXiv.org. https://arxiv.org/abs/2101.03961↩︎
5. Hutson. (2021, March 3). Robo-writers: the rise and risks of language-generating AI. Robo writers: The Rise and Risks of Language-generating AI. Retrieved December 29, 2022, from https://www.nature.com/articles/d41586-021-00530-0↩︎
6. Thompson, N. C. (2020, July 10). The Computational Limits of Deep Learning. arXiv.org. https://arxiv.org/abs/2007.05558↩︎
7. GHG Inventory - NYC Mayor’s Office of Sustainability_. (n.d.-b). https://nyc-ghg inventory.cusp.nyu.edu/↩︎
8. Thompson, N. C., Greenewald, K., Lee, K., & Manso, G. F. (2021, September 24). Deep Learning’s Diminishing Returns. Ieeespectrum. https://spectrum.ieee.org/amp/deep-learning computational-cost-2655082754↩︎
(本篇作者:黃逸華、chatGPT )




