
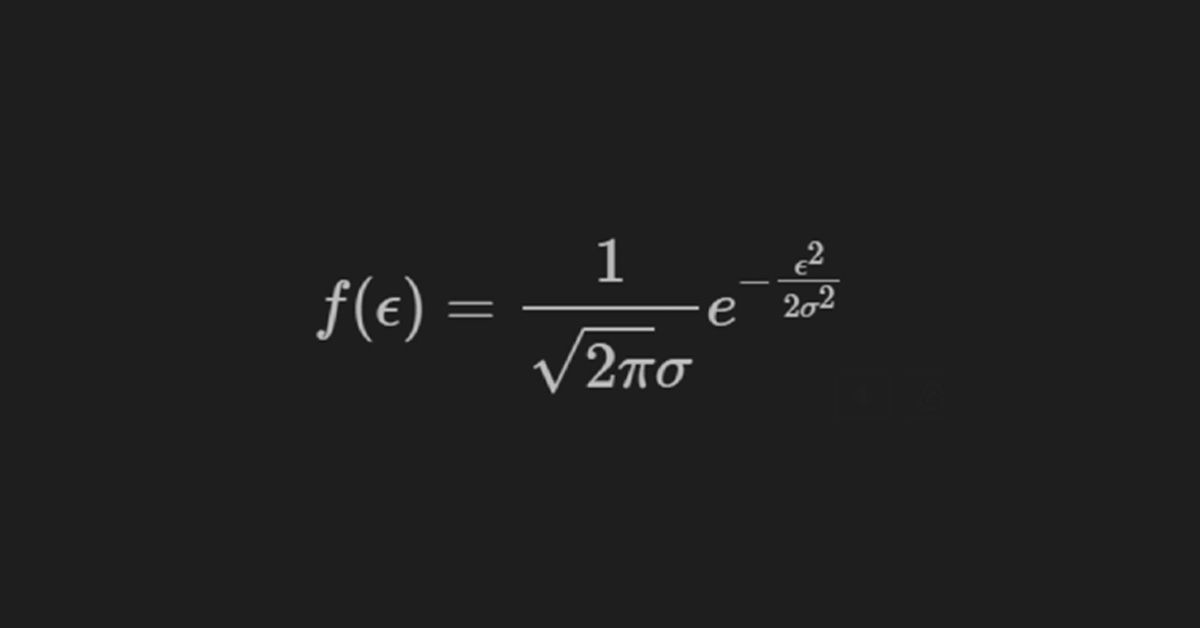
堪堪就在三百年前,數學王子高斯(Karl Friedrich Gauss,又譯「咖兒費力氣搞死」)首次提出了「常態分佈(或正態分佈,或高斯分佈)」,用來描述觀測星球移動軌跡的誤差。
他優雅地說道:
然後呢?然後就火了。我們數學平民看到公式頭上就著火了,在科學界,則是大紅火了。
科學家不斷在各種自然與社會現象中發現常態分佈的蹤跡,例如中央極限定理、大數法則,而這又進一步構成了現代統計學的重要基礎。
把常態分佈抓來簡單粗暴解剖一番,大概可以看到這幾個特性:
- 極端案例遠少於一般案例
- 最常見的一般案例位於中心位置
- 極端案例呈現對稱狀態
說個最簡單的例子,隨機挑選的一群人之中,明顯偏胖或明顯偏瘦的人都偏少,越接近整群人體重均值的人數越多,因此,以人數與體重作圖,可以得到一個單峰而對稱的圖形,再稍微調整一下,用均值與標準差這兩個簡單參數就足以描述常態分佈的所有數學性質。
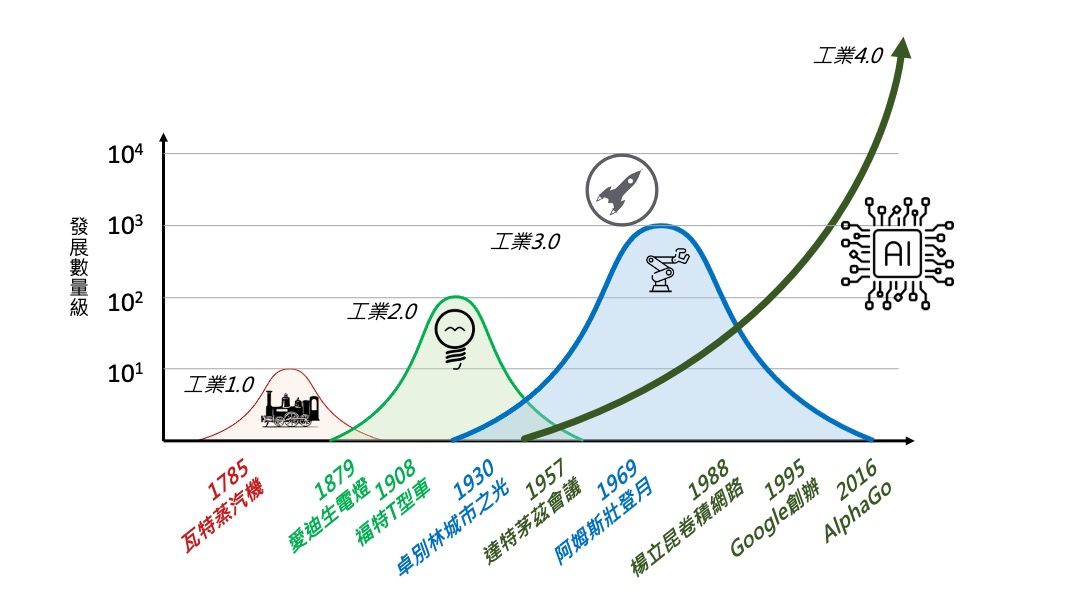
常態分佈之義大矣哉,粗淺掌握這個概念就足以理解整個工業革命發展歷程,還能說明何以AI科技導入有其必然性及必要性。
在工業革命發展之前,人力與獸力居於生產動力的核心位置。在那個時候,產量少、品質不穩定,生產所得勉為餬口,不過人們已經很滿意了。這時以產能與品質作圖,會得到一個小小的、不起眼的、扁平的隆起,像個小青春痘一樣,敘述著一段青澀的質樸歲月。
十八世紀中期,紡織機出現後,各式各樣由自然物理力量驅動的設備被發明出來,人們進入了大量生產的時代,在這個以物理動力設備為標誌的時代裡,代表產能與品質的常態分佈曲線向右邊跨出了一大步,也變得更巨大,代表著機器將原本的生產力翻了好幾倍。在這百餘年之間,人們的工作型態也開始有了根本性的變化,原本都是個人或少數人在小工坊裡工作,此時可能是數十、數百人追趕著機器的節奏,彼此分工,一同完成過去難以想像的數量。
二十世紀初,愛迪生帶來現代意義的電力,於是有了不夜城市與摩天高樓,亨利福特將馬趕出馬路,讓一個巨大的鐵塊帶著人們與貨物四處遊走。人對於時間與空間的掌握能力變大許多,也因為電力,製造業得以全面實現全日無休的生產能力,支持城市與人口進一步快速膨脹。此時以描述產能與品質的常態分佈,又來到了更右邊象徵巨大產能的位置,波峰變得更集中托高,意味著品質更穩定。
二次世界大戰死傷人數約2億,幾乎佔到當時全球25億人口的一成。戰爭結束,百廢待舉,這是全人類的悲劇,卻是生產者的天堂。當時的巨大需求推著生產者必須提供更多的產品,然而人力不足也是現實,逼得生產者從機械化生產進一步推進到自動化生產的世界中。此時的品質產能常態分佈曲線又繼續朝著變高變瘦的方向走去,產能更大、品質更穩定,而在自動化設備的支持下,成本也變得更低。在資本家與工人之間也出現了一個全新的社會階層或專業類型——白領,擔負起專業管理的任務,也因為要讓自己的工作變得更簡單、可預期,白領也自然成為穩定社會的重要群體。
產能大、速度快,聽起來就很迷人,不過,一旦出現問題,那損失也是嘩啦啦的。因此,與其追求生產最好最賺錢的產品,倒不如追求最穩定最低成本的生產模式,因此有了「品質」與「工程能力」(Process Capability)的概念。簡單地說,就是在生產過程中維持一定品質的能力,其間,又衍生出一系列的指標與管理工具,作為生產過程的品質管理工具。
工業革命第一階段的特徵是機械化生產,第二階段是電力,第三階段則是自動化。那麼,工業4.0的特徵會是什麼,目前普遍認為是基於數據驅動的智慧化應用。
1998年,楊立昆(Young LeCun)發表一篇關於CNN捲積神經網路的論文,這也是整個現代深度網路的開山之作。在前一年,大神 Jeffery Hinton 發表了反向傳播。這段時期中一系列的創新與洞見,建立了當代深度學習神經網路的基礎架構,在2016年 AlphaGO 橫空出世後,原先只在小說、電影與實驗室中存在的精靈,來到人類眼前,不多時就已經滲透到日常生活之中,無所不在。人工智慧工具最大的優勢就是對於非線性行為的擬合能力。
生產線上,每個機台、每道製程運行中所產生的數據都被收集起來,經過機器學習工具進行消化,得出結果,與實際結果相連接,進一步再反饋到製程與企業經營上。這個循環就將前述的製程能力與人工智慧連結起來。此前基於規則的的專家系統也花了許多年時間未曾克服的非線性障礙,被基於模型的人工智慧一舉突破。
按照慣例,基於產能及效益的常態分佈曲線,應該繼續一路飄向右方,還要吸飽市場力量,繼續壯大起來。
確實應該如此,但又並非如此。原因在於市場激烈變化所帶來的衝擊如此巨大,使得原該繼續變高變瘦變大的曲線被打碎成為許許多多更小的常態分佈曲線,人們看到的其實是所有變動聚合(aggregate)的結果。
何以如此?這是因為市場需求變得多樣化且潮流存活時間極短。對此,製造端除了接受,別無選擇,也因而導致個別產品的製程能力相對難以提升,畢竟很可能數據還沒穩定下來,工單已經完成,而且,參數不斷變動,線性工具已經難以勝任,畢竟我們此時已經身處高維非線性空間裡了。
常態分佈曲線初步描述了工業革命後各階段的部分細節,可能會讓人誤會在各個階段之間還存在中間狀態,事實絕非如此。
工業革命後各個階段的變動並非線性放大,而是升維——從點到線到面,再到立體,乃至於高維。彼此之間可以用量子跳躍來形容,要不是這個狀態,否則就必然是各個狀態之一,不存在中間階段。而以當前的實踐現況來說,如果有人興高采烈對世人大聲宣告自己已經完成工業4.0的數位轉型工作,也許他真的成功了,不過也說不定只是因為對自己沒甚麼要求。
工業發展進程中必然是百花盛開的局面,每朵嬌豔花兒都是局部微幅的優化,千萬花朵一同造出這個燦爛耀眼的局面,但如果其中有哪朵花自矜自貴,非說自己是花中之王,為這片花園帶來什麼了不起的變化,讓花園瞬間進步到幾點幾的版本,就不禁讓人先是一頭霧水,接著要掩口莞爾了。
1935年海德格在他的《哲學獻稿》中提到未來現代技術危機的三大特徵,分別是計算、加速與海量數據。其中,因為人們亟欲控制與規劃自己所在的實體世界,其手段就是計算,也因此而消除了以探究意義為核心的問題,因為意義無從計算,只能靠思辨來處理。
這樣的世界中不問意義、不論存在,只談計算,不能被計算的事物就只能被遺忘。計算帶來加速,速度讓人覺得有安全感,但也使得這樣的社會欠缺容忍、無心等待,這一切都來自於海量數據,而海量數據也將帶來海量爆發。
很熟悉,對吧?
海德格在1935年就準確地預測將近百年之後的時間,按例應該也還得給海德格一個「現代數位網路世界人工智慧技術創新哲學思考未來學之父」才算堪堪跟他的遠見相稱吧?




