表格資料(Tabular data)是關鍵的機器學習資料。儘管傳統機器學習方法如梯度提升樹(包含知名的 LightGBM 以及 XGBoost)在這方面表現突出,但大型語言模型(LLM)的興起帶來了新的挑戰與機會。本文探討 LLM 如何在未直接接觸資料的情況下分類表格資料,並分析「TabLLM」項目的創新方法和成果。
表格資料(Tabular data)是生活中常見的資料類型,在金融、醫療、製造業領域都很常見,相信也是許多人踏入機器學習領域的第一份資料。十幾年來,得益於半導體製程的進步,深度學習蓬勃發展,在電腦視覺、自然語言處理的領域不斷突破;然而對於表格資料,當今的深度學習模型仍難以勝過 XGBoost、LightGBM 這類梯度提升樹(Gradient-boosted trees)進行集成(Ensemble)後的模型,在 Kaggle 或 T-Brain 這類的競賽平台,常常可以發現這個現象,這點競賽常客應該格外地有感觸。
TabLLM
隨著大型語言模型(Large Language Model, LLM)在各領域取得的成功,資料科學家也開始思考,我們能不能將 LLM 背後驚人的知識量,應用在表格資料的任務上呢?「TabLLM:Few-shot Classification of Tabular Data with Large Language Models」實現了這個想法,並在表格資料的分類任務上取得有趣的成果。
整體架構
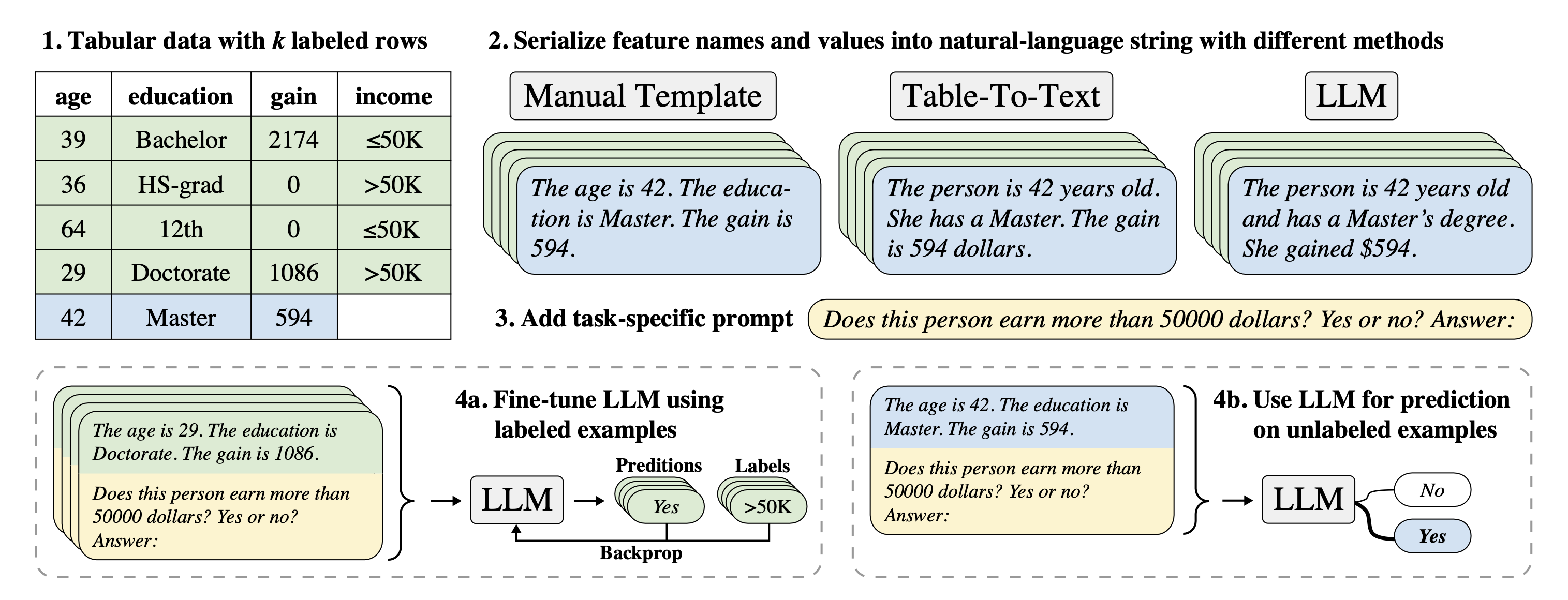
▲ 圖 1:TabLLM 整體架構圖,圖取自 Hegselmann et al. (2023)。
圖1 描述了 TabLLM 的幾個重要步驟,大致上是先將表格資料先分為有標籤和無標籤,對於 k 個有標籤的樣本,先將其特徵值部分轉換為類似於自然語言的描述,再搭配特定格式的提示詞(Prompt)輸入 LLM 來進行微調(Fine-tune),最後就能以微調後的 LLM 來針對無標籤資料進行預測。
不同的 Serialization 方法
Serialization(國教院中譯為串列化)是指將表格資料轉為近似於自然語言的處理過程,也是 TabLLM 探討的重點。TabLLM 進行了一項有趣的實驗,他們使用了以下 9 種不同的 Serialization 來測試對結果的影響:
- List Template:直接條列特徵項目及其值,且保持固定特徵順序
- Text Template:用接近口語的方式逐項說明特徵及其值,如圖 1 裡面「Manual Template」下方的文字
- Text T0:將特徵項目、特徵值配對,再使用 T0 並搭配提示詞「“Write this information as a sentence:”」來得到自然語言的描述
- Text GPT-3:與 Text T0 類似,但因為 GPT-3 可直接將條列好的特徵轉換為自然語言的描述,因此只需要輔以提示詞“Rewrite all list items in the input as a natural text.”就能得到自然語言輸出
- Table-To-Text:使用已針對 Table-To-Text 任務微調後的語言模型進行轉換
除了上述 5 種,還基於以上的方法做了進階的嘗試:
- List Only Values:刪去特徵名稱,目的是觀察特徵名稱是否影響了結果
- List Permuted Names:擾亂特徵名稱,可以觀察特徵名稱與值之間的關係是否重要
- List Permuted Values:擾亂特徵值,觀察模型是否使用了數值型特徵的細顆粒度(Fine-grained)資訊
- List Short:將 List Template 限制在最多只能使用 10 個特徵,超過的部分直接捨去,這一項的目的觀察受限的資訊量是否會影響模型的判斷
提示詞部分,TabLLM 採用如圖 1 所示的方式來結合 Serialization 後的字串,然而針對不同資料集,會因資料特性以及為了符合語言模型的輸入限制,而有一些細微的差異。
資料集與語言模型
TabLLM 總共進行了兩個階段的分類任務,對每一個資料集的分類結果計算 AUC 。
- 第一階段:對 Bank、Diabetes 以及其他總共 9 個公開資料集進行分類任務,其中也有兩個來自 Kaggle 平台,皆為二類別或多類別
- 第二階段:進行二類別分類,共有 End of Life、Surgical Procedure 以及 Likelihood of Hospitalization,這些資料由美國的某壽險公司提供,並經去識別化處理
TabLLM 使用 Hugging Face 上的 T0 (bigscience/T0pp),並以 T-few 進行微調。T0 擁有 110 億參數,token 限制為 1,024,在原文中研究團隊也嘗試以 T0_3B (bigscience/T0_3B)作為語言模型來進行實驗,結果顯示效能相較於 T0 略為降低。
實驗結果
TabLLM 以兩個圖表說明重要的實驗結果,我們從以下幾個面向來切入:
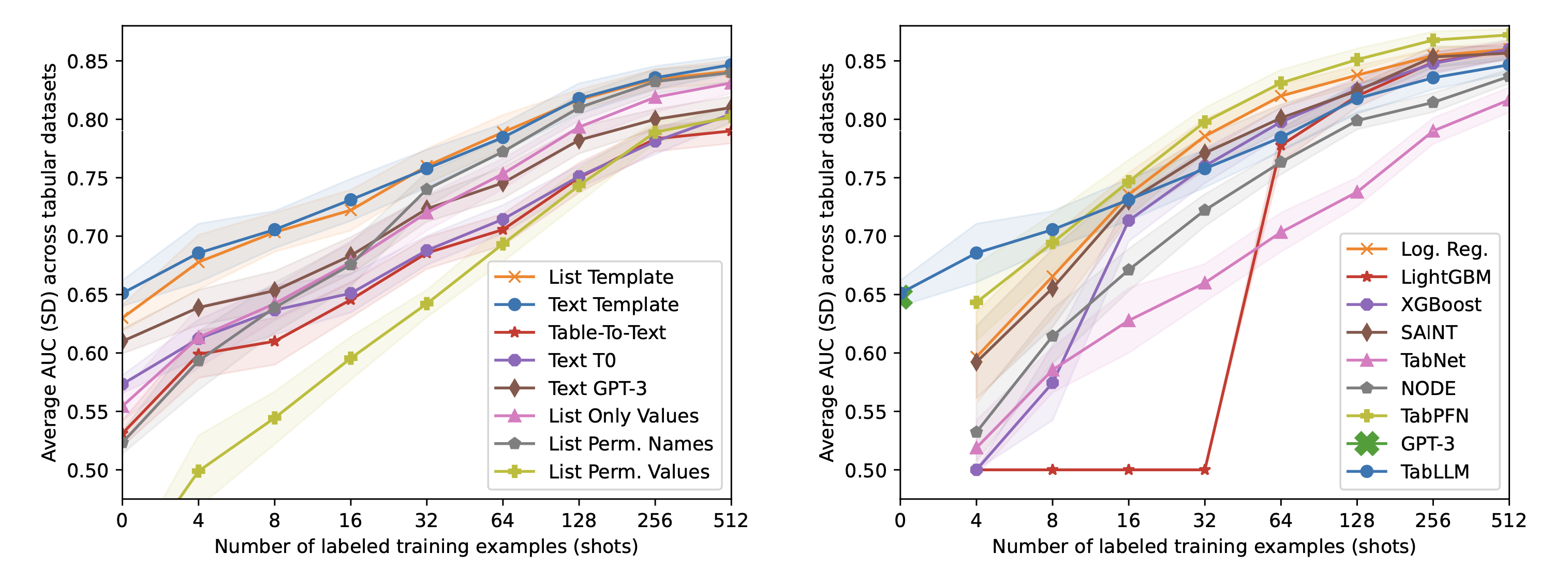
▲ 圖2:左圖是 TabLLM 在 9 個資料集的實驗結果;右圖則是與不同模型的效能比較,橫軸皆為使用的資料筆數,縱軸為 AUC 平均值,並以網底顯示標準差。圖取自 Hegselmann et al. (2023)。
Serialization 對分類結果的影響
透過圖 2 我們發現,當樣本數約略在 0 到 16 時,Text(以接近口語的方式逐項描述特徵)比 List(直接將特徵條列)還要好一點,但隨著樣本數繼續增加,變得幾乎沒有差距。當使用語言模型,搭配適當的提示詞進行 Serialization,AUC 大致上與模型參數量有相同趨勢,在 3 個使用的模型中,參數量分別為:GPT-3 有 1,750 億,T0 有 110 億以及 BLOOM table-to-text 有 5.6 億。有趣的是,語言模型似乎對某些樣本產生了幻覺,例如在 Car 資料集裡,GPT-3 擅自替某一筆樣本加上了〝this car is a good choice〞的描述,對同一筆樣本,T0 則是在開頭直接說了〝The refrigerator has three doors and is very cheap〞。這些多餘或甚至不相干的資訊,可能多少影響了分類結果,而我們也的確發現,用語言模型進行 Serialization 的 AUC 不如直接使用 Text 或 List。
對特徵動手腳後,LLM 會被影響嗎?
如果我們刻意擾亂特徵項目與值之間的關聯,語言模型還能正確判斷嗎?為了測試語言模型是否確實讀懂特徵描述,作者設計兩種擾亂的方法,一是 List Permuted Names,二是 List Permuted Values,前者調換了特徵名稱,後者則擾亂了特徵值。圖 2 顯示如果我們將名稱調換,和原先的 List 比起來,在 16 個樣本數以下的實驗,AUC 都有明顯的下降,而當特徵值被擾亂,我們就看到更大的下滑幅度。這個現象透露了比起名稱,模型更在乎特徵的值。
和其他模型的比較
圖 2 右側展示了 TabLLM 與其他模型在分類任務的 AUC 比較,TabLLM 部分是以 Text 作為 Serialization 方法。在 zero-shot 的測試中,T0 能夠與多出十餘倍參數量的 GPT-3 並駕齊驅,而跟 LightGBM、XGBoost 比起來,TabLLM 只有在樣本數低於 64 時較好,在樣本數 4 或 8 時則有明顯差距。比較意外的是,羅吉斯迴歸只輸給以 Transformer 為基礎的 TabPFN,同時在 16 個樣本數以上的測試完勝 TabLLM。
TabLLM 憑藉大型語言模型擁有的先備知識,在部分資料集以 few-shot 甚至是 zero-shot 超越目前對表格資料較為擅長的模型;然而當樣本數持續增加,XGBoost以及 LightGBM 依然能夠超越 TabLLM。考量到光是不同 Serialization 就造成明顯的效能差異,如果再針對提示詞進行調整,的確有機會再提升效能,但如果又將微調的運算成本、硬體需求納入考量,我認為 LightGBM 或 XGBoost 這類較「輕量」的模型仍會是首選。
LLM 的先備知識是否運用在判斷樣本上?
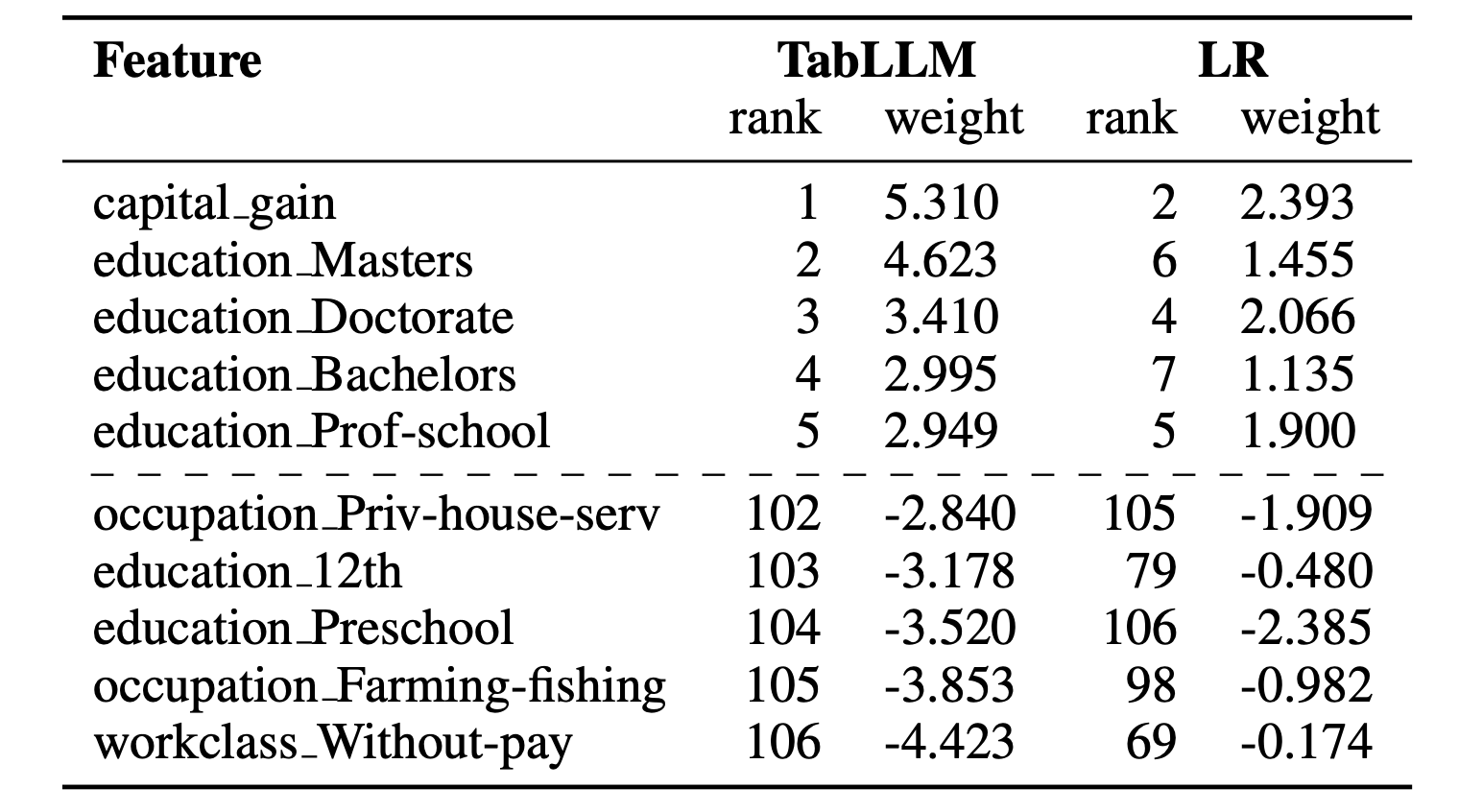
在 Income 資料集的分類結果,TabLLM 於 zero-shot 得到了 0.84 的 AUC,且 XGBoost 一直到使用所有樣本進行訓練時才超越 TabLLM,因此作者試著比較 TabLLM 以及羅吉斯迴歸的特徵權重,結果如表 1。兩模型大致上對特徵權重有類似的排序,在 TabLLM 排在前 5 的特徵(可以看到多為教育程度特徵),全出現在羅吉斯迴歸的前 7 名中,然而羅吉斯迴歸對教育程度的排序似乎比較合理一點。此外,Income 有幾項特徵與金錢有關,由於 T0 是在 2021 年訓練,而 Income 建立於 1994 年,如果沒有針對這 27 年間的通貨膨脹數據進行調整,所得到的 AUC 僅有 0.80。
以上幾項實驗,TabLLM 的特徵權重是以原始特徵作為輸入、預測結果作為標籤,訓練出一個羅吉斯迴歸模型,接著以該模型的特徵權重代表 TabLLM。
▼ 表 1:TabLLM 以及羅吉斯迴歸模型的特徵權重,僅列出排名前五以及末五名。取自 Hegselmann et al. (2023)。
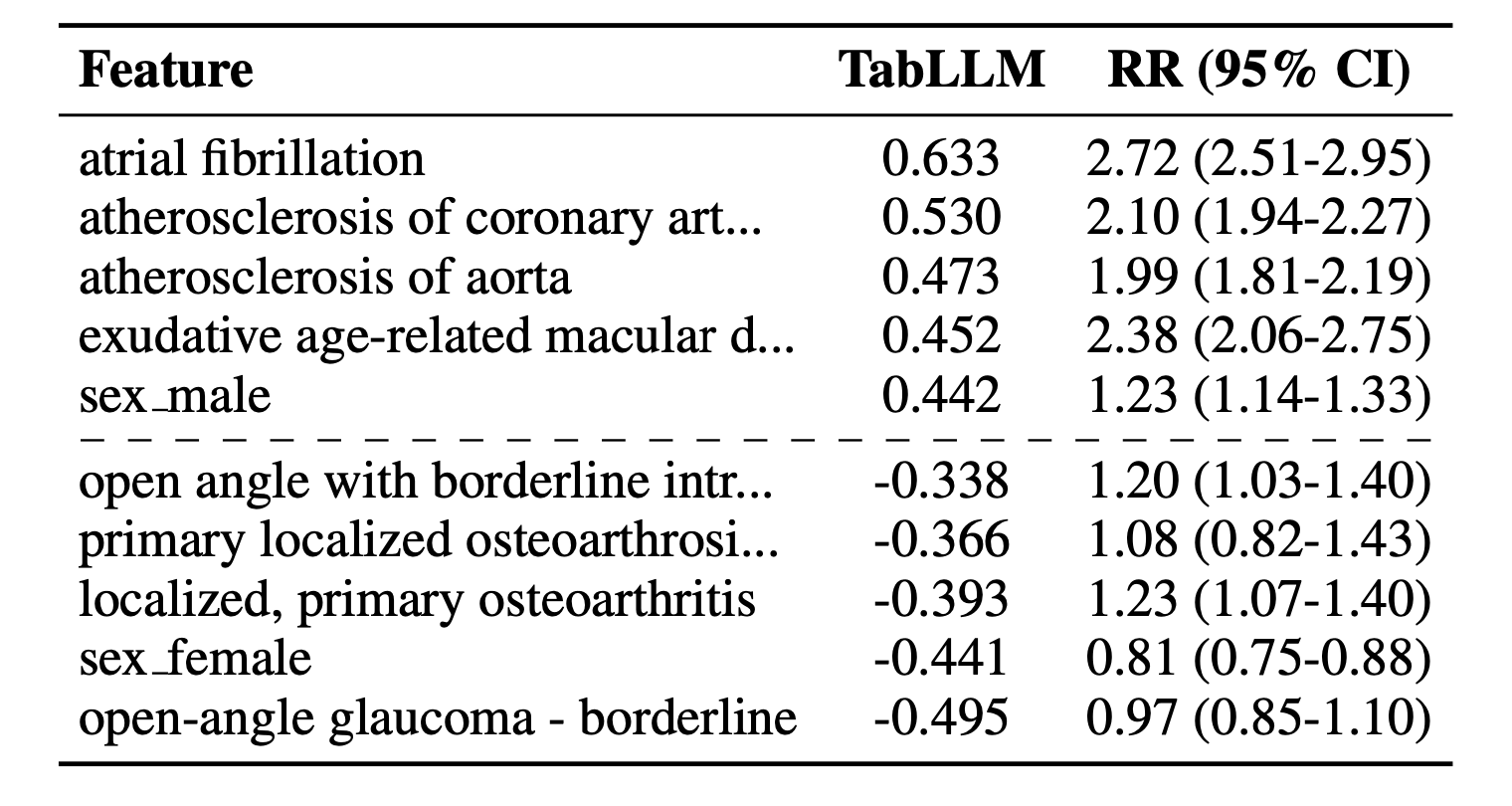
接著是健康醫療類型的資料集 End of Life (EoL),這個資料集的目的是預測樣本的死亡率,每個樣本都有記載疾病史與基本資料作為特徵。將 TabLLM 的特徵權重和相對風險(Relative risk)對照後,如表 2,發現 TabLLM 排名前 5 的特徵,其相對風險值皆偏高(以罹患疾病為例,相對風險的 95% 信賴區間如果都高於 1,表示暴露組罹患疾病的風險顯著高於非暴露組;若都低於 1 則相反),大致上有權重愈高的特徵相對風險也愈高的趨勢。留意表中的性別特徵,無論是 TabLLM 與相對風險的數值,都一致認為性別對結果有不同的影響。
▼ 表2:TabLLM 的特徵權重與 Relative risk (RR)。取自 Hegselmann et al. (2023)。
結論
TabLLM 成功運用語言模型具備的領域知識,降低了所需要的訓練資料量,甚至達到 zero-shot;然而,在模型訓練與測試資料的年代相差過大時,確實會對降低模型的 zero-shot 效能,未來在實作上需要留意。不同 Serialization 方式的測試結果,說明了輸入文字的些微變化,會對語言模型的輸出有一定程度的影響,然而實驗結果也顯示當訓練資料數量上升,彼此間的差異就逐漸降低。另一方面,大型語言模型可能因為訓練資料而帶有些微偏見或刻板印象,當被用來判斷較為敏感的資料,勢必得謹慎的處理。從 TabLLM 我們看到大型語言模型的知識,也能被用在表格資料上,隨著語言模型能力日漸提升,可以期待未來的發展。
(撰稿工程師:吳宇翔)
參考資料