Scikit-learn 是 Python 中流行的機器學習框架之一,提供豐富的機器學習演算法和工具,讓使用者可以方便地進行數據分析和建立模型。在機器學習流程中,經常需要進行資料前處理、特徵選擇和模型選擇等一系列步驟,為了簡化這些步驟,Scikit-learn 提供 Pipeline 工具,讓人可以更輕鬆地構建和評估機器學習模型。
Pipeline 是一個可以將數據轉換和建立模型步驟組合在一起的工具,以實現更高效的機器學習流程。每個步驟都是一個 Transformer 或一個 Estimator。而 Transformer 是一個轉換器,用於資料前處理,例如特徵標準化、特徵選擇、資料編碼等。 Estimator 是一個模型,用於建立機器學習模型,例如線性回歸、支援向量機、決策樹等。使用 Pipeline 可以更好地管理和維護程式、提高生產力和開發效率,讓使用者可以更快速地比對不同的模型和參數設定,進行機器學習實驗和模型開發。
以下,我們要使用 Kaggle 上的經典資料集 —— Titanic,並著重在介紹 Pipeline 工具的使用方法,完成基本機器學習流程的步驟。關於資料集的觀察及分析將不在本文詳述,可另行參閱參考連結。
步驟 1:載入資料集
首先,我們需要載入Titanic 資料集。該資料集可以在 Kaggle 上直接下載,並載入我們需要的相關 Python 套件,包括 pandas 等。載入後,可以觀察資料集的前幾行來了解資料內容。
可以發現到特徵含有不同資料型態(數值/類別),也有些欄位具有遺漏值,我們將挑選一些適合展示 Pipeline 工具使用方法的特徵,進行資料前處理。
步驟 2:資料前處理
根據上述 Titanic 資料集的狀態,我們可以針對特徵透過 Pipeline 進行以下的前處理:
- 填補缺失值
- 標準化轉換
- 類別編碼
接著,來看一下 Pipeline 怎麼使用吧!
Pipeline的建構形式是一序列由 (key, value) 等 tuple 形式構成的步驟,其中 key 用來指定此步驟的名稱,而 value 則是想要採用的 Transformer 或 Estimator 物件,例如:
補充: Transformer 通常用於 Pipeline 中的前幾個步驟,以便對資料進行預處理。 Estimator 通常用於 Pipeline 中的最後一個步驟,以便對資料進行訓練和預測。
以下我們就要透過 Pipeline 來構建所需的前處理,先載入需要的套件,本實作sklearn版本為1.2.2。
接著創建 Pipeline 物件,可以依據特徵、型態分別做不同的前處理。
透過 ColumnTransformer 將特徵欄位與 Transformer 做整合,建立出的物件也為 Transformer 可作為後續 Pipeline 串接的 Transformer 。
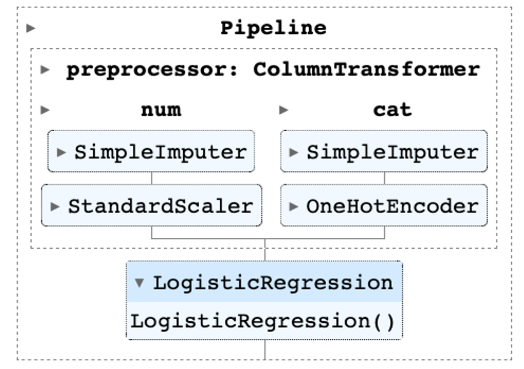
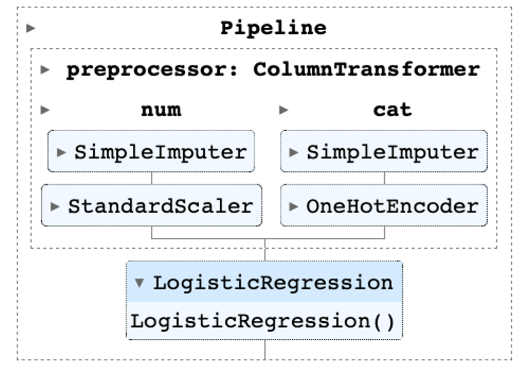
若在互動式直譯器環境下(jupyter notebook)編寫程式,還能視覺化 Pipeline 的結構,圖為印出我們定義的 preprocessor 的結果,可以更清楚各欄位所進行的前處理內容。

接著篩選欄位特徵,準備在建立模型階段時,將前處理 Transformer 與模型一同透過 Pipeline 串接處理。
步驟 3:建立模型
完成資料前處理後,我們需要建立模型,同樣也可以使用 Pipeline 將先前的前處理 Transformer 與模型 Estimator 串接起來。在這裡,我們使用 Scikit-learn 提供的 LogisticRegression 模型來預測乘客是否生還。
可以看到我們建立的模型 Pipeline 將前處理 Transformer 及模型 Estimator 串接起來,用視覺化及模組化的方式呈現,可以更快速且清晰的調整所需做的前處理及模型設計。
步驟 4:模型評估和優化
建立模型後,我們需要進行模型評估和優化。在這個步驟中,可以使用交叉驗證來評估模型的效能,並使用網格搜尋法來優化模型的參數。
步驟 5:測試集預測
預測測試集時,測試集也必須經過與訓練集相同的前處理,這裡正好也是凸顯 Pipeline 好處的部分,直接針對 Transformer 及 Estimator 的 Pipeline 採用 predict,Pipeline 即會採用 transform 做完前處理及套用模型預測。
最後,即可將預測結果輸出到 CSV 檔案中,提交到 Kaggle 上進行比賽。
完整程式碼
總結
總結來說,Scikit-learn 的 Pipeline 工具是一個非常方便的機器學習工具,它可以將轉換器 Transformer 和模型 Estimator 串聯在一起,讓整個機器學習流程更加流暢和易於理解。建議使用者在進行機器學習開發時,考慮使用 Pipeline 來減少錯誤和提高生產力,同時還可以使我們更加專注於機器學習模型的核心問題。
參考資料
Pipelines and composite estimators - construction
Step by Step Tutorial of Sci-kit Learn Pipeline - James Ho
Titanic - Machine Learning from Disaster
Titanic Data Science Solutions
A Data Science Framework: To Achieve 99% Accuracy
Predicting the Survival of Titanic Passengers
機器學習實作-手把手-Kaggle-鐵達尼號生存預測
Kaggle競賽-鐵達尼號生存預測 (前16%排名)
(撰稿工程師:蕭雅方)




