
生成式 AI 可說是今年最為熱門的關鍵字,除了圖片,還可以生成出聲音、文字等成果,也可以看到越來越多的 AI 生成工具出現,例如 Midjourney、Stable Diffusion 就是十分受歡迎的繪圖工具。透過本篇技術原理的說明,你將知道如何有效利用這些工具快速產出想要的圖片。
其實,AI 生成圖片並不是這兩年才發展出的技術,早在 2014 年就有人提出利用 GAN (對抗式生成網路)的概念,並以此生成出許多以假亂真的圖片,不過自從 Diffusion Model 這個生成模型被提出之後,AI 生成圖片的品質也大幅度提升,更衍伸出 Midjourney與 Stable Diffusion 兩大 AI 繪圖工具。
使用過 Midjourney、Stable Diffusion 等工具的朋友,應該會發現在生圖的過程中,圖片會由一團模糊的雜訊開始,逐漸出現輪廓、五官等特徵,最後才變成一幅精緻的畫作,這過程和 Diffusion Model 的訓練原理相關。
Diffusion Model 的模型訓練目標是將一張充滿雜訊(噪音)的圖片,利用神經網路找出並去除圖片中的雜訊,進而生成出新的圖片。但是,這些圖片上的雜訊並不會一次就清除乾淨,而是需要經過多次預測與雜訊清除,最後才能生成出清晰又美麗的圖片。
為了達到生成圖片的目標,在模型的訓練過程中,會針對需要訓練的圖片「加上」雜訊,這個作法稱為 Diffusion process,再讓神經網路試著預測經過 Diffusion process 處理的圖片,預測後「去除」雜訊,此作法稱為 Denoising process,如下圖所示。

而熱門的 Midjourney(註1)也是在這個原理下發展而來,以下介紹使用 Midjourney 時,幾個重要的關鍵字(Text prompt)與功能:
- /imagine:輸入詠唱咒語即可生成圖片。目前有文字生圖,與文字加圖片生圖片的功能。
- /describe:分析現有的參考圖片,生成其圖片的詠唱咒語。
- /Pan:基於原本的圖片,再向外延伸繪圖。目前適用的版本為 v5、v5.1、v5.2。
- /Vary Region:透過圈選的方式進行局部重新繪製。如下圖所示。
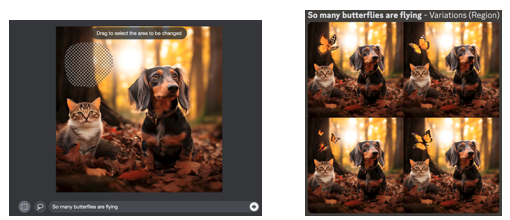
想畫出理想的圖片,該怎麼跟 Midjourney 説?
-長度:使用簡短且明確描述的咒語,集中在想要創建的主要概念上
-文法:詞語的內容比句子結構更為影響生成,能夠清楚說明更為重要
-需求:描述想要的內容與細節,嘗試使用 --no 參數避免不想生成的元素。
-元素:明確表達主題、環境、光線、顏色、氛圍、構圖和具體數字。
Stable Diffusion 又是什麼?
Stable Diffusion 則是由 StabilityAI、Runway、CompVis 團隊,基於 Diffusion model 合作開發的模型,Stable Diffusion 的訓練與生圖過程是在 Latent Space中,將圖片轉換至 Latent space,這個方式可以提高訓練與產圖的效率,同時也能保留圖片的重要特徵,幫助 Diffusion process 與 Denoising process 的效果。可以想像,假設原先 1024x1024 的圖片,經過轉換為 64x64,即可提高運算效能。
訓練過程為透過一張正常的圖片,經過 Image encoder 轉換到 Latent Space 變成 64x64 的 Latents,再進行 Diffusion process,加上 User Condition(例如:Prompt 為兩隻狗狗在海邊一起玩球),Stable Diffusion 會依照此限制,進行 Denoising process,逐步去除噪音生成圖片。如下圖所示。
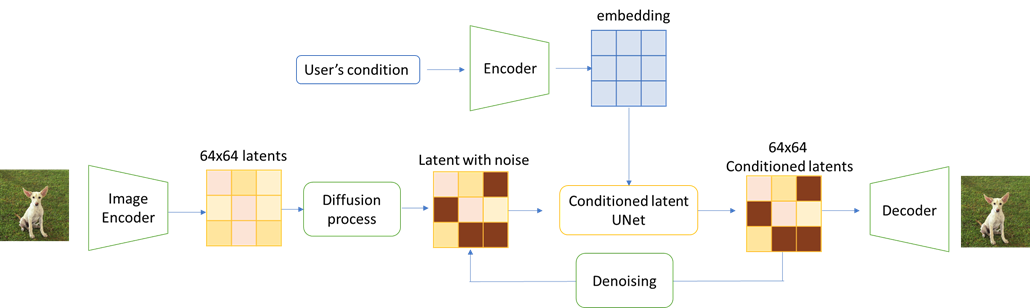
生成過程由一張充滿噪音的Latents,加上 User Conditional,生成一張完整漂亮的圖片。

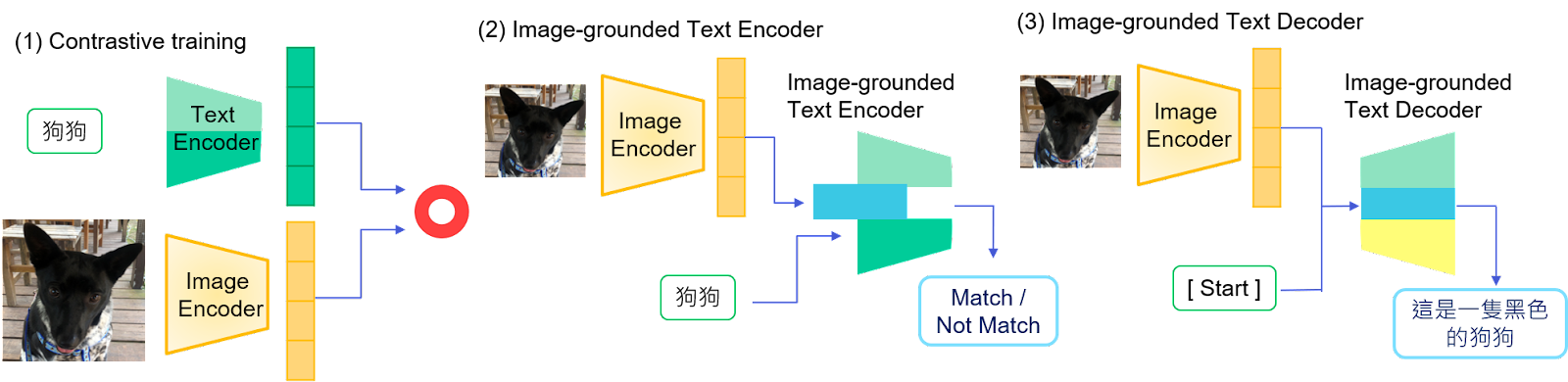
Stable Diffusion 運用 CLIP(Contrastive Language-Image Pre-Training)與 BLIP(Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation)的套件,分別達成「文生圖」與「圖生文」來生成圖片。
CLIP 是由 Open AI 提出的多模態模型,以多組圖文及 Contrastive pre-training 訓練 Text Encoder 與 Image Encoder, 使用 Text Encoder 進行文字轉換,確認文字與圖片是否匹配。在 Stable Diffusion 是利用 CLIP 中的 Text encoder 解析 User Conditional 並放入 Stable Diffusion 當中。
BLIP 則是透過圖片解析出文字來生成圖片,以下為 BLIP 的訓練方式:
- Contrastive training:分辨文字跟圖片是否匹配,用於訓練 Encoder。
- Image-grounded Text Encoder:將圖片資訊加入 Text Encoder,判斷圖片資訊跟文字資訊是否有連結
- Image-grounded Text Decoder:訓練 Decoder 輸出一段文句
Stable Diffusion 的優勢
Stable Diffusion 之所以能成為主流的生成模型,在於使用者能更自由的對圖片進行調整,例如 Inpainting 的功能,此功能可以圈選想要重新繪製的部分,再加入 Prompt 重新繪圖。如下圖所示。

而 ControlNet 的功能,能夠以新增條件的方式調整圖片的風格,也可以透過外掛工具,如:LoRA,指定繪圖的重點。如下圖所示。

今年7月,Stable Diffusion 團隊提出新的架構 SDXL,將產圖的流程分為兩種模型,Base 是產生 Latent 的模型,Refiner 是針對產生的 Latent 進行細部優化的模型,並同時搭配專屬的 VAE Decoder。如下圖所示。SDXL 不僅在細節的呈現優於 Stable Diffusion,也能精確地畫出文字。

Midjourney 與 Stable Diffusion 該選誰?
整體而言,Stable Diffusion 擁有較多彈性調整的功能,若需要使用 API、客製化服務,或已有設備並可以自行架設環境,推薦使用 Stable Diffusion。若是想要簡易且穩定,產出高品質的圖片,較適合使用Midjourney,下圖提供六大面向比較:

註1:Midjourney 的服務是在 Discord Bot 上使用,讓使用者透過輸入詠唱咒語(Prompt)進行繪圖創作。
想知道更詳細的 AI 生成圖片原理,請參考【AI CAFÉ 線上聽】拿起神奇畫筆:AI 變成小畫家




