
ChatGPT 讓使用者能以聊天對話的方式,向機器提問且獲得解答,簡易的互動降低了一般人使用 AI 的門檻,不僅更貼近日常使用,也更接近人們想像中的 AI。背後關鍵的「大型語言模型」(LLM,large language mode)究竟擁有哪些能力,又該如何使用呢?
LLMs是什麼呢?
大型語言模型(LLM)指的是擁有超過 100 億參數的語言模型,LLM 通常以 Transformer 架構為主,因為 Transformer 可以處理較長的語言序列,並透過注意力機制學習每個序列間的關係,例如:「昨天我和同事去游泳,游的有點晚,所以我們今天很累。」以往機器並無法判斷句中的「我們」指的是「我和同事」,但是,經過訓練後的 Transformer 架構模型可以找到句中這兩個詞彙之間的關係。
下圖為目前較為知名的大型語言模型們(LLMs),依推出年份及公司排序,可以看到 Google(包含 Google DeepMind)與 OpenAI 在技術推進的過程中,佔了極大的份量。Google 推出的模型包含:T5、LaMDA、PaLM、Gopher、Chinchilla;OpenAI 推出的模型包含:GPT、GPT-3、instructGPT、ChatGPT、GPT-4。另外,值得一提的是由 Hugging Face 所釋出的 Bloom 為開源且開放商用的模型。
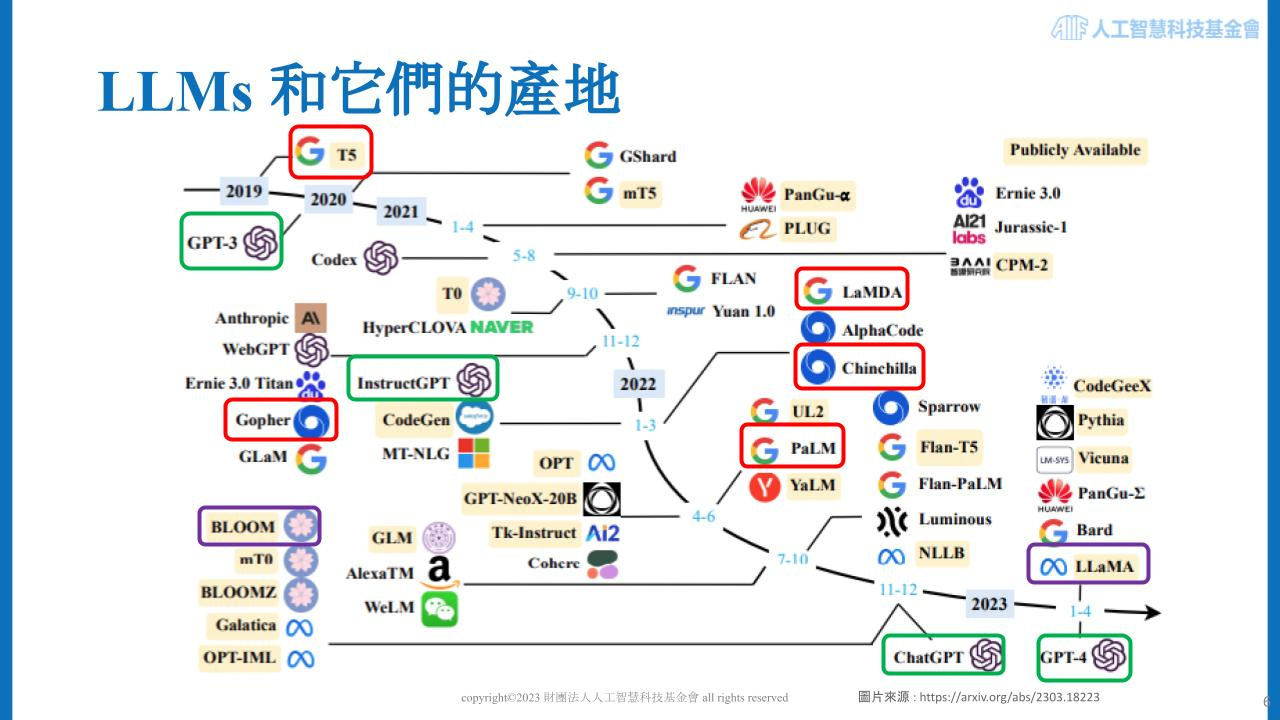
2019 年,Google 推出 T5 模型,在其發表的論文中提到,他們將所有自然語言處理的任務,重新構建為統一的文字以及文字格式;而 OpenAI 自 2018 年開始,一直以通用的語言模型為目標,逐步推出 GPT-2、GPT-3、GPT-4,並期望藉由大型語言模型能生成出各式成品,以解決各種各樣的實際問題,且它應該能聽懂人類的命令,以方便人類使用。
大型語言模型有多「大」?
大型語言模型到底有多大呢?在探討這個問題時,通常會提到兩件事,分別是「模型的參數量」及「預訓練的資料量」,可以把「參數量」比喻成模型的腦容量;而「預訓練的資料量」則像是模型後天閱讀過的文字與資料。以 GPT-3 為例,該模型的參數量為 1,750 億,相當於 BERT 模型參數量的 1,750 倍;而GPT-3預訓練的資料量則高達3000 億 Token,相當於讀了 95,000 套哈利波特全集的字,由此可知大型語言模型的巨大。
但是,為什麼要做到如此巨大?透過以下三個實驗測試,發現模型越大,準確度越高。例如第一個實驗,主要是在 LLM 的預訓練階段,以大型語言模型玩文字接龍的方式,當運算資源與參數量固定,隨著「資料量」增加,模型預測下個字的錯誤率越低;同樣情況下,隨著「參數量」增加,模型的錯誤率也隨之降低。如下圖所示。

第二個實驗顯示,若要讓大型語言模型學會正確語法,至少需要 1,000 萬至 1 億的單詞語料。但是,模型可能會說出符合文法卻不合常理的詞句,例如:我被熱水壺凍傷了。因此,在學會語法後,還需要讓模型學習世界知識,由於世界知識包含常識及事實型的知識,所謂事實型的知識如:第 46 屆美國總統是 Joe Biden,因此還需要使用超過 300 億的單字語料,才能期待模型說出一般人類可能會說的話。
第三個實驗,利用超過 100 種實際的自然語言任務來檢視模型的性能,可以發現在相對簡單的問答任務,如Q&A問答中,隨著模型規模的不斷增長,正確率也持續增長。這類任務多半是知識密集型任務,說明了這類任務對大模型中知識蘊涵的數量要求較高。
相對複雜困難或多步驟的任務,起初增加模型的大小時,正確率並不能有效提升,但如果將模型參數量提高到 100 億到1,000 億時,正確率開始大幅提升,相關文獻將之稱為湧現能力(Emergent Abilities)。如下圖所示。

過往語言模型未曾出現的特殊能力
1. Instruction following:以具體的自然語言任務訓練模型後,模型對於未曾學習過的任務類型,也能順利回覆,就像具備了舉一反三或觸類旁通的能力。
2. In-context learning:在沒有經過訓練的情況下,意指沒有經過梯度下降與參數更新,模型便能根據一些任務範例完成任務。
3.Step-by-step reasoning(Chain-of-Thought):對於需要多個步驟才能解決的問題,展現了逐步推理解決問題的能力。
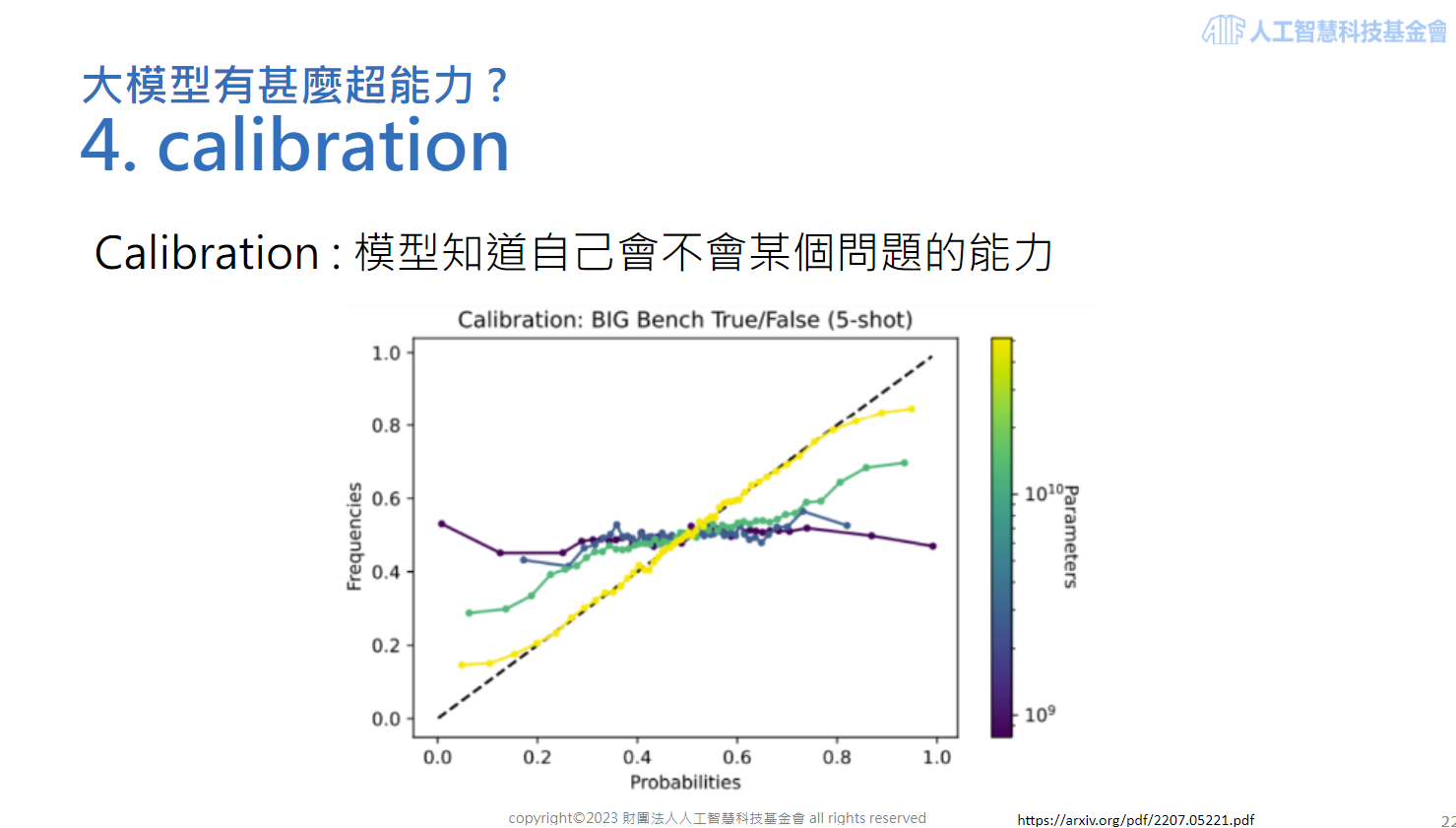
4.Calibration : 在越大的模型中,答題正確率的信心程度比較符合實際的正確率。如下圖所示,由於語言模型在回答問題時,將會依照機率選擇合適的回應,當模型越大,回應的機率分佈和正確率的分佈也越吻合,較不會有信心很強但答錯的情況。
該怎麼使用 LLMs?
以下提供使用 LLM 的兩種方法,第一種是利用API串接未開源模型,例如:OpenAI 以 API 串接模型的方式開放使用,這種方法適合用量較少的個人或中小企業。優點是能透過串接API 的方式,將自家產品與模型連接,一般軟體工程師較容易施作,且產生的回應品質能領先市面其他模型,但缺點是,可能在無意中,洩漏了企業的機敏資料,以及產品的服務可能因為 OpenAI 的服務中斷而受影響。
第二種為使用開源模型再加上自己的資料訓練模型,例如:Hugging Face 釋出的 Bloom,就是一個開源且可商用的模型,使用者可以加上自己的資料進行訓練,例如:加入繁中語料、企業客服問題集等,以 Supervised FineTune的方式,即可改造為企業獨有的 LLM,如此將能夠把較敏感的資料掌握在自己手中,且在高使用量的情況下較為便宜,但相較第一種方式,使用開源模型需要龐大的基礎設備、初始成本、專業的 AI 人才等條件。
想了解更多大型語言模型的基礎知識與特殊能力,請參考【AI CAFÉ 線上聽】你 chat up GPT 了嗎?考古 LLM 的那些事




