
GAN被譽為是21世紀最難被訓練的類神經網路之一,近五年來,有非常多的學者都針對GAN進行探討,不管是演算法的更新或是實際應用在其他領域,都有非常多的paper發表。除了生成圖片,還可以做到很多事情,如:五線譜生成、文章生成,甚至小說生成,可生成的東西非常多。只是台灣較常用使用在瑕疵檢測、超解析度(Super Resolution),以及圖片修復。到底什麼是GAN?主要可以應用在哪些地方?本篇文章一次解答。
我們可以看到以下這兩張照片,左邊是動畫圖,右邊是人臉照,你相信眼前的這些人臉並不是真人,而是用AI畫出來,這有可能嗎?

GAN也被稱為生成式對抗網路,英文是Generative Adversarial Network。這一個網路架構是在2014年,由Ian Goodfellow所提出的一個「非監督式學習」的網路架構。所謂的非監督式學習可以把它想像成,在訓練模型時,沒有在訓練資料上加上任何標籤,而直接進行訓練。CNN的初始的創造者Yann Lecun,曾形容GAN這個網路架構可說是這10年來最有趣的想法。
GAN能做什麼呢?
當我們藉由訓練目前現有的資料分布,這就好像將貓跟狗的圖片全部輸入後,目標是要生成與其有相關性分布的數據,白話來說,就是生成圖片。那什麼叫作有相關性的分布呢?
一個簡單的解釋是,假設下方圖片左下角是GAN目前想看到的圖片,當GAN在學習時,可能會看到加菲貓,也可能會看到小黑狗,猜一猜,GAN最後出來的結果會是甚麼?結果,GAN可能會畫出一隻小黑貓。GAN的目標是根據一些原始的東西,然後畫出一個很像貓與狗的圖片,正好呼應前面提到GAN可以看到很多人臉,然後畫出一些更有趣的人臉出來。

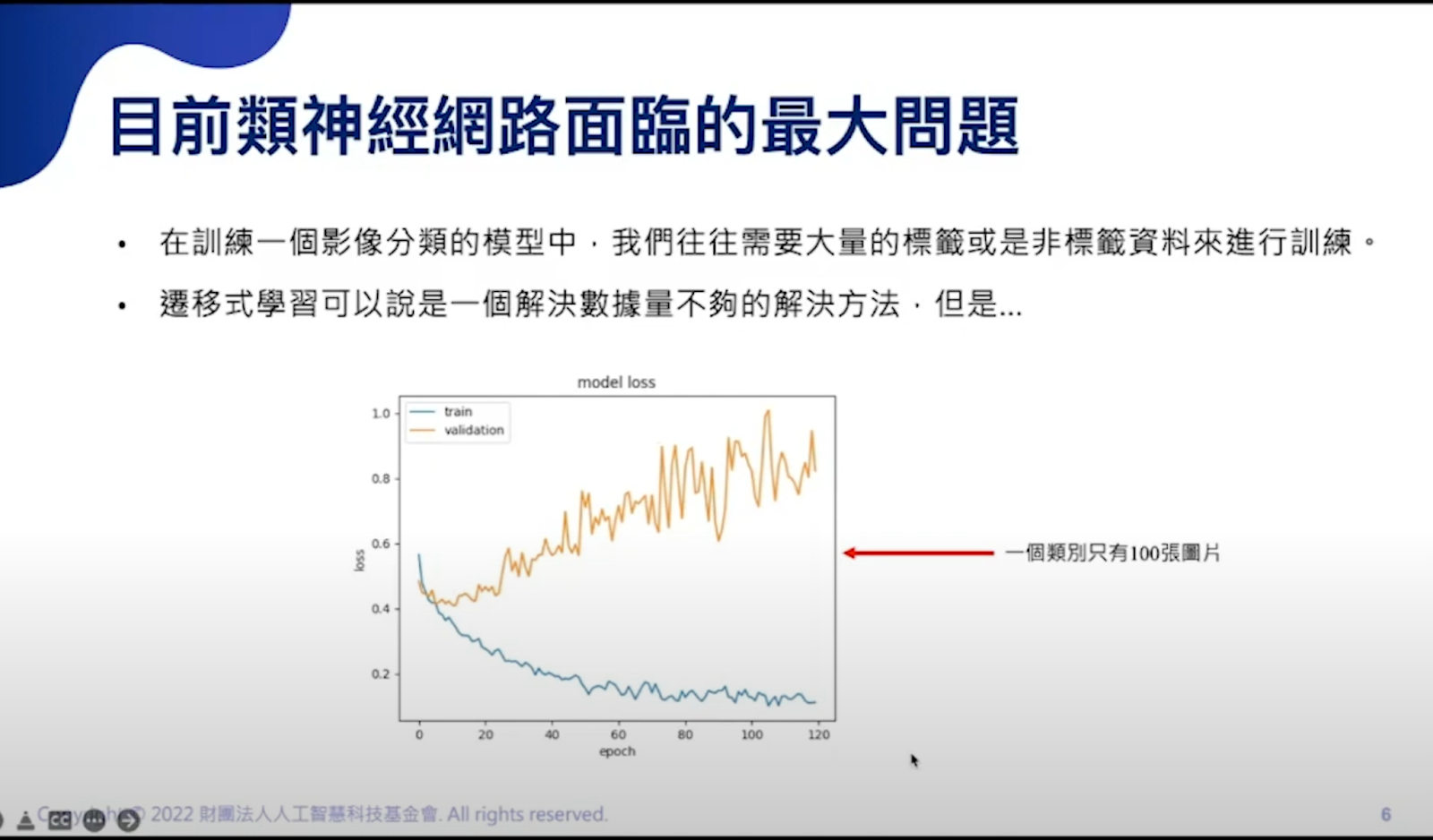
那麼,GAN通常會用在哪些地方?目前類神經網路面臨到一個很大的問題,假設我們今天的目標是要去訓練到一個影像分類的Model,通常會去train一個classifiaction的模型,這往往需要大量的標籤或是非標籤的資料進行訓練。假設目標是要分貓跟狗,那可能會用很多貓跟狗的圖片進行訓練,這樣模型能在接下來的測試時,判斷圖片是貓還是狗。
一開始提到transfer learning可以解決資料量不夠的問題,假設今天圖片很少,遷移式學習可能是一個解法。但是,從下面的圖片中,我們可以看到,X軸指的是模型看所有圖片的次數,所以我們預期今天的資料數量越高,理論上模型就學得越好;因此,Y軸的目標就是Loss越低越好。圖片上有兩條線分別代表,訓練集與驗證集,在做訓練集時,會發現訓練集一直在往下降,也就是說,如果這個類別中,各自有一百張貓跟狗的圖片,驗證時會發現,他出了一些麻煩,明明訓練集越訓練越好,為什麼驗證集越來越麻煩,這是一個overfitting的問題,代表說你的資料量可能不夠。當資料量不夠時怎麼辦?通常會增加資料量,這雖然是一個很棒的解法,但並不是所有資料都像貓跟狗這麼容易取得,例如以下資料就不好取得。
醫療用資料像是胸腔X光片、睡眠品質資料圖,因為牽涉到隱私問題,部分醫院不一定會提供,所以在這一塊,要使用醫療資料去做模型訓練也較為困難。
或者是敏感性的資料,例如極權國家可能會去封鎖一些資料,讓資料難以取得;另外,目前在台灣很常會應用到的瑕疵資料,例如車用晶片的良率不可能是百分之百,99、98都是極有可能的比例,所以可能會找到1%到2%的瑕疵資料,可以想像瑕疵資料筆數就會非常少。假設瑕疵資料如果很多的話,也可能代表良率不高,那公司還有辦法撐下去嗎?所以,如果很多公司要做瑕疵檢測的題目,也會需要增加瑕疵資料?
在增加資料量上,過去的做法是利用傳統的資料擴增,例如下方圖片,我們透過一些方式,如水平翻轉、圖片縮放,甚至去對影像rotation做一點改變,讓貓咪圖片的角度產生一些變化,甚至可以針對pixel wise的顏色進行調整。但是,透過不同手法讓貓迷圖片增加了六張,好像資料量增加了,但實際上還是一樣的貓,整體貓的分布並沒有被改變。而我們希望的是,在做貓狗分類時,可以加入加菲貓、波斯貓,或是其他不同種類的貓,重點在多樣性,而不是單一種類的貓。所以這個模型想要學的是同個標籤上圖片的變化量,就是問題種類的貓,這才是我們的目標。但傳統資料擴增無法做到。

那麼,有其他方法可以做到資料擴增,並能做到資料集增加呢?
這時候,我們可以用GAN的方式生成資料,例如下圖的風景畫就是由GAN生成出來,這些風景畫並不存在,而是讓電腦看了不同種類的風景畫後,自己學習並畫出風景畫應該要有的pattern。
所以可以預期如果生成的圖片品質越高,多樣性也就越高,那才是真的達到增加資料集的目的,也是GAN的目的。

常見的GAN架構為何?
一個基本的GAN叫做DCGAN,是用一個叫做Convolution Neural Network的東西先做Feature Extraction,然後進行生成,就是一個簡單的圖片生成的GAN。接下來的Cycle GAN則是一個形樣轉變Style Transfer的做法,做法也很簡單,假設要將白天轉換成夜晚的影像,或是輸入一張風景畫,然後輸出成各種不同畫家所畫出來的圖,這個東西我們稱為形樣轉變。
另外,在台灣各領域很常用到的Super Resolution GAN。各位可以想像,假設我有一張大小只有100 x 100的圖片,這張小圖在手機上看可能覺得還可以,但如果要拿到電腦上看的話,就會發現這張圖片超模糊。這時候,我們可以利用GAN做超解析度的轉換,把100 x 100的圖片轉換成1024 x 1024的圖片,轉換以後還可以把它的細節保留下來。
另一個還蠻有趣的是Stack GAN,假設input一段文字,例如:「This bird is black with green and has a very short beak」,它會根據這段文字產生相對應的圖。最後的Style GAN是目前整個Generative Model裡,可以產生品質最高、圖片解析度最好的架構。這是由Nvidia所提出來的,最高可以生成1024 x 1024的圖片,但是,訓練資源相對也較其他模型高,所以不是每個人都可以把玩的。
GAN的實務應用
今天會分享兩個例子,第一個例子是車用器材的瑕疵檢測。由於目前的瑕疵檢測十分耗費人力與工時,且還是很多工廠是用人力去做。於是這間公司希望能訓練一個深度學習的模型協助工作並減少人力耗費。但是,這個專案遇到了幾個問題,首先是公司提供的影像並不清楚,我們很難從照片中判斷哪個有瑕疵?另一個則是瑕疵的零件數量非常少,所以在做類神經網路訓練時,其實並不好訓練。
首先,我們針對影像進行一些基本的預處理,接著,就是用GAN去生成更多的瑕疵資料。為什麼要用GAN而不用傳統的資料擴增?因為我們沒有把握瑕疵究竟有哪幾種pattern,而廠商提供的資料也許根本沒有足以抗衡所有pattern的存在,所以試圖用GAN生成更多不同種類的瑕疵品。
第二個案例則是腦波圖的睡眠品質分析,現代社會中,我們可能會因為很多原因導致睡眠不佳,所以有越來越多人會去探討自己的睡眠品質,就是監測睡眠。目前睡眠品質的分析,還是需要仰賴專業人士判讀,而這個判讀過程非常煩瑣。這個專案中,我們遇到的第一個問題就是搜集的資料量不足,因為搜集一個人睡眠的腦波圖資料非常費時,加上測試者再貼上感測器後,需要花費許多晚的時間才能適應,也才能得到睡眠數據。蒐集完資料後,還需要專家判讀。當初做專案時,我們希望可以訓練一個類神經網路做到這個EEG的睡眠分類。
這個專案當初碰到的問題,還包括嚴重類別不平衡。當初在做訓練時,資料量嚴重不足,所以模型沒有辦法學到整個EEG的pattern。於是,我們就用GAN去生成。我們利用based on GAN生成更多EEG的資料,然後輸入模型中訓練。我們用一個簡單的CNN分類模型進行評估,主要比較的地方包括,利用原始資料集,不做任何的生成直接訓練,另一個則是用DCGAN的方式。接著,我們提出SleepGAN去做生成,至於要如何利用SleepGAN生成品質良好的資料,我們將在後續的進階的實作課程分享。




