隨著深度學習技術快速的發展,近來許多應用都會使用深度學習做為模型框架,但隨之而來的攻擊行為將對社會或公司形成隱憂,例如,攻擊者會透過改造訓練樣本,干擾模型的輸出結果。因此,如何確保深度學習技術安全,已經成為當今電腦科學領域亟需關注的問題。
近年來,許多研究者都提出了對抗性樣本的影響不僅在圖像領域,在文本、音頻及語意上也有著類似的問題。為了因應對抗性樣本帶來的威脅,又有哪些對策呢?國立中央大學資訊工程學系特聘教授王家慶以「AI Security in audio」為題,分享近年來在音訊領域中常見的攻擊手法與防禦方法,希望更多人一起關注相關領域的發展。
王家慶說,語音及音訊系統就像圖像辨識系統一樣,隨著深度學習技術的飛快進步,各種深度神經網路模型也蓬勃的發展,無論是辨識精準度或速度都有大幅提升,各個大廠也積極投入開發與研究資源。但模型的落地也帶來了威脅,對抗性樣本就是其中一種,干擾放入模型做預測的輸入,例如一個已經訓練好的語音辨識模型,故意在錄音後加入特定的雜訊,就會影響模型的準確度。在圖像辨識上,模型可能會將熊貓誤認為小狗,或是在人像辨識上出現錯誤;在音訊領域上,則會使得音訊辨識出現錯誤。不僅使得模型的準確性受到質疑,更可能造成隱私洩露或是系統不穩定等安全疑慮。
模型可能遇到哪些攻擊呢?
針對AI模型的攻擊,會讓精心訓練的模型輸出錯誤結果,或變成攻擊者所指定的結果,因此防禦者必須在模型遇到攻擊時,使之能正常輸出結果,不受到攻擊影響或降低干擾。王家慶說,在進行對抗性樣本研究時,不論是攻擊或防禦,都能在研究過程中了解模型的穩健性,以及模型的學習方法等相關資訊。但他也指出一個值得思考的問題:「對抗性樣本的存在,是否為數據集中的一種缺陷?」
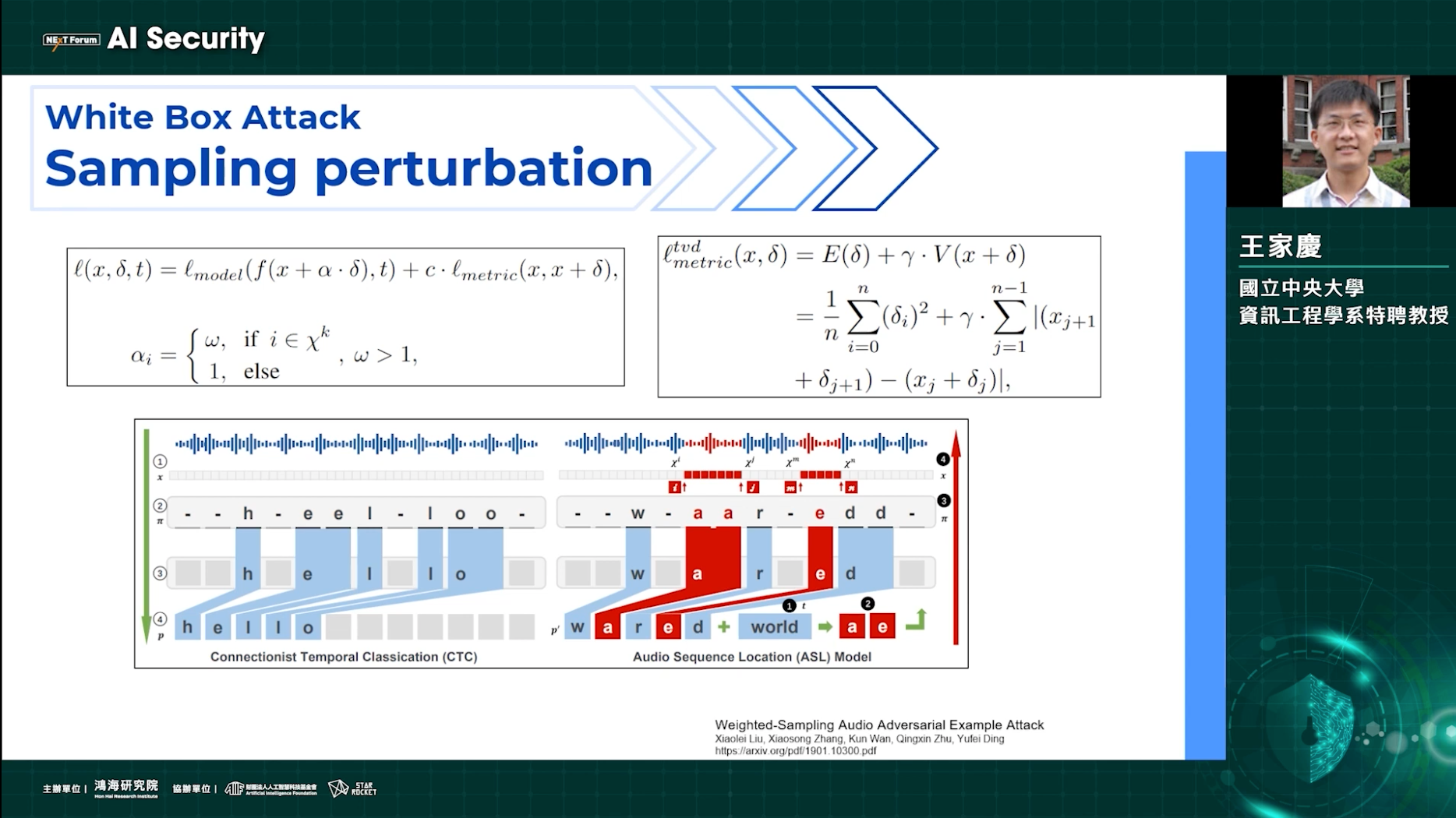
幾種常見的攻擊包括白箱攻擊與黑箱攻擊,所謂的「白箱攻擊」,指的是對訓練細節瞭若指掌的模型進行攻擊;而黑箱攻擊則是在無法得知模型架構、參數權重等資訊下進行攻擊。由於黑箱攻擊所掌握的資訊較少,在生成對抗性樣本上比較困難。
另外,攻擊還可以分為通用性與遷移性。什麼是通用性攻擊呢?王家慶解釋,一般來說,一個模型中有許多正常的樣本,要造成擾動的話,必須要針對每個樣本都做出不同的擾動。但是通用性攻擊可以同時針對每個樣本發動攻擊。例如針對圖像,可以用同一種規範的照片一起生成出來;但在音訊上,若要使用通用性攻擊,則需要考慮到音訊長短、錄音品質、頻段等諸多因素。至於遷移性攻擊則是指在不同的類型、數據或平台上產生擾動,以達到攻擊的效果,例如把被擾動過的二維頻譜圖進行重建,以欺騙一維的模型。
王家慶表示,目前的攻擊手法已有足夠的效果,因此,新的攻擊者轉而強調效率的增強,也就是能用更快的速度產生對抗性樣本。
如何防禦這些攻擊呢?
有人攻擊就會有人防禦,防禦的研究緊跟在攻擊之後,王家慶也提到了幾種常見的防禦方式。例如針對輸入數據進行預錯率,或是在數據輸入前,就先檢測是否為對抗性樣本?也可以在數據輸入後,針對結果進行篩檢,若輸出結果為異常,就視為無效的結果。另一方面,也可以將對抗性樣本視為數據的一種特徵,進行對抗式訓練。又或者是限制硬體的輸入設定,以過濾擾動。
王家慶舉例,雜訊除了做為攻擊,也可以將攻擊反過來當作防禦及對抗性訓練。針對圖像的對抗性訓練,同樣也能應用於音訊領域。例如先將音訊轉成頻譜圖,接著對二維頻譜圖做擾動,再將擾動過的頻曝圖當作訓練數據,使新訓練的模型對對抗性樣本也有穩健性。
有競爭力的才能存活
王家慶認為,從2018年發展至今,對抗性的研究已涵蓋許多針對音訊的攻擊與防禦,並且訓練出足夠穩健的深度學習模型。雖然對抗性樣本是目前深度學習領域亟需克服的大障礙,但也不用太擔心攻擊者會過於狂妄的攻擊。因為就像網路安全一樣,有人攻擊就會有人防禦,而防禦的研究會緊跟在攻擊之後,只有具有競爭力的才能存活下來,讓人類得以得利。
精彩演講內容




