醫療產業的 AI 應用向來備受矚目,過去許多科技大廠都曾嘗試跨入醫療領域,並且發表出亮眼的實驗成果,但落實在實際場域的表現卻總是無法盡如人意,例如 IBM 當年風光成立的 Watson Health,最後卻被拋售而黯然收場。
隨著ChatGPT的出現,再讓產業興起希望,期待能將生成式 AI 運用在實際醫療場域,協助醫護人員提高醫療效率。但醫療產業有許多實際的法規與風險需要考量,過往在導入 AI 的過程中,實際遇到的挑戰為何?是否能作為新一波生成式 AI 應用的借鑑呢?
在智慧醫療的發展上,早在幾年前就已看到許多 AI 論文快速陸續發表,還有許多應用成果逐步出現,例如透過肺部影像輔助判別是否染疫及嚴重程度;或協助監測病人的生命跡象,並提前預警;也有疫情變化預測的應用。乍看以為人工智慧似乎已能順利應用於醫學上了,台大醫院智慧醫療中心副主任李建璋認為,從醫療實務的經驗,人工智慧要能實際應用於醫學上的仍有一段距離,最大的原因不在演算法而在資料;而高品質的資將是台灣發展人工智慧醫療的機會。
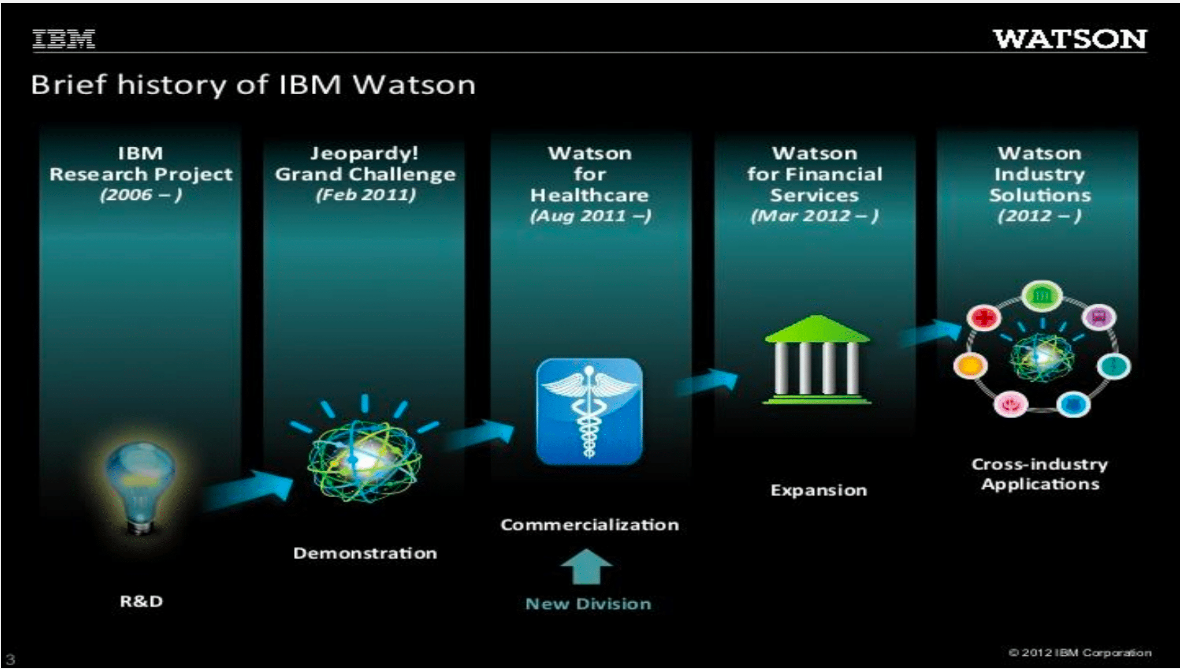
從備受矚目到黯然收場,Watson Health問題出在哪?
十年前,IBM開發的人工智慧系統「華生」(Watson)在益智節目《Jeopardy》中擊敗真人抱走百萬獎金,也開啟IBM AI進軍醫療這個兆元產業的契機,並在2015 年成立專責部門Watson Health,目標是幫助醫生進行診斷,並依照診斷結果給予病人醫療建議。這個吸引許多知名合作機構投資巨額資金的計畫,卻在十年後傳出IBM有意拋售,並被外界視為AI醫療的一大挫敗。為什麼Watson會走到這一步?
Watson的腫瘤診斷治療輔助系統,醫生的建議在不同國家的吻合狀況落差很大,區域穩定度並不高;另一個讓醫師沒有信心的重要關鍵是,Watson會給出傷害病患的治療決策。而造成這個結果的關鍵原因並不是演算法不佳或是引用錯誤文獻,而是「資料本身」。李建璋說,由於目前提供的資料有80%是文字記錄,並且有許多專有名詞,加上許多不同習慣的縮寫及醫師主觀的描述。
另一方面,即使Watson已經和美國首屈一指的癌症中心合作,但資料量還是太少,因此科學家創造了類似的病人資料以幫助電腦學習,但是,這些「創造出」的資料可能是現實生活中不會出現的,因此給了錯誤的決策。除此之外,還有一些與醫療實務相關的資料同樣也有問題。
資料出了哪些問題?
「Garbage in,Garbage out」是人工智慧專案中常聽到的一句話,當我們提供給電腦的資料有問題時,所產生的結果也會有偏差。李建璋認為資料的問題,可分為兩大方面:異質性及台灣獨特的問題,都讓訓練的難度提高。
資料異質性產生的原因包括:一、不同醫院對不同藥物有不同的偏好。二、不同時期針對同一事件給予的醫療決策也會不同。例如過去認為急救時要給病人百分之百的氧氣,後來發現這樣的處理會對病人造成傷害,因此做了調整。而這些變化很快的醫學治療方式,如果用歷史資料去訓練,就有可能會讓電腦產生誤判。三、不同級別的醫生對於疾病的見解也會有所不同。四、不同醫師所選擇檢測的項目不同。李建璋說,由於醫療的決策是有自由度的,即使是同一疾病,不同醫師選擇檢驗的項目差異很大。因為這些不一致,導致模型的訓練難度提高。
台灣獨有的問題,則來自語言使用及醫療環境。李建璋認為,台灣病歷使用的語言是英文加上中文,要在一個由西方世界發明出來的自然語言處理系統上轉移,本身就有難度。再來是病歷紀錄有許多醫生特有的縮寫語及簡寫,且在不同醫院有不同的意思。
另外,西方由於醫病糾紛十分頻繁,所以醫師會花很多力氣將雙方的對談及診斷過程記錄情處,但台灣由於看診時間壓縮,病例多是處方的紀錄,因此,電腦無法學習背後的思路過程。李建璋說,由於受限於資料品質的關係,當今的人工智慧醫療的應用才會多以醫療影像辨識為主。
台灣的三座資料金山
李建璋認為,台灣在發展人工智慧醫療方面有四大關鍵機會與挑戰:高品質的資料、跨領域人才,好的算力、真實場域的應用。在醫學影像的世界擁有絕佳的機會,因為我們擁有累積24年資料的健保資料庫,這可能是世界上最大的醫療放射影像資料庫。這些資料要是能經過基礎標注形成公開資料的話,將為醫療影像帶來革命性的影響。

除了健保資料庫,台灣的醫院電子化程度高,歷年累積的電子病歷資料庫以及由中研院所發起的人體生物資料庫都是十分好的資料來源,但要克服的挑戰也不少,最關鍵的就是必須花更多的力氣保護資料的隱私,同時也要跟民眾溝通資料的隱私保護及應用,才能降低民眾疑慮。由於當前歐美國家所訓練的模型資料多以西方人為主,若套用到亞洲國家的話,可能會因為種族的差異而有誤差,因此,台灣在人工智慧的發展上仍有大好機會,甚至能將眼光放遠至華人社會。

(整理:楊育青)




