
AI 除了作曲也能分離不同的樂器聲音,不論人聲、背景音、各種樂器聲,透過 AI 模型辨識出不同音訊並達到精準分離,稱為「聲源分離」。
聲源分離技術的應用十分廣泛,如:音樂後製、影音降躁、機器檢測、線上授課等。本篇文章將從深度學習在音訊處理的概念切入,分享音訊在特徵處理及「音訊處理模型」如何進行聲源分離任務的做法。
什麼是音訊?
音訊的定義為:一個聲波的振動。假設下方圖片中間的黑點是一位正在說話的人,當他說話時,附近的空氣分子會隨之震動,震動時所產生的聲波會往外形成疏密波,疏波的地方為波谷,密波的地方是波峰,而聲波會一直往外傳遞能量。

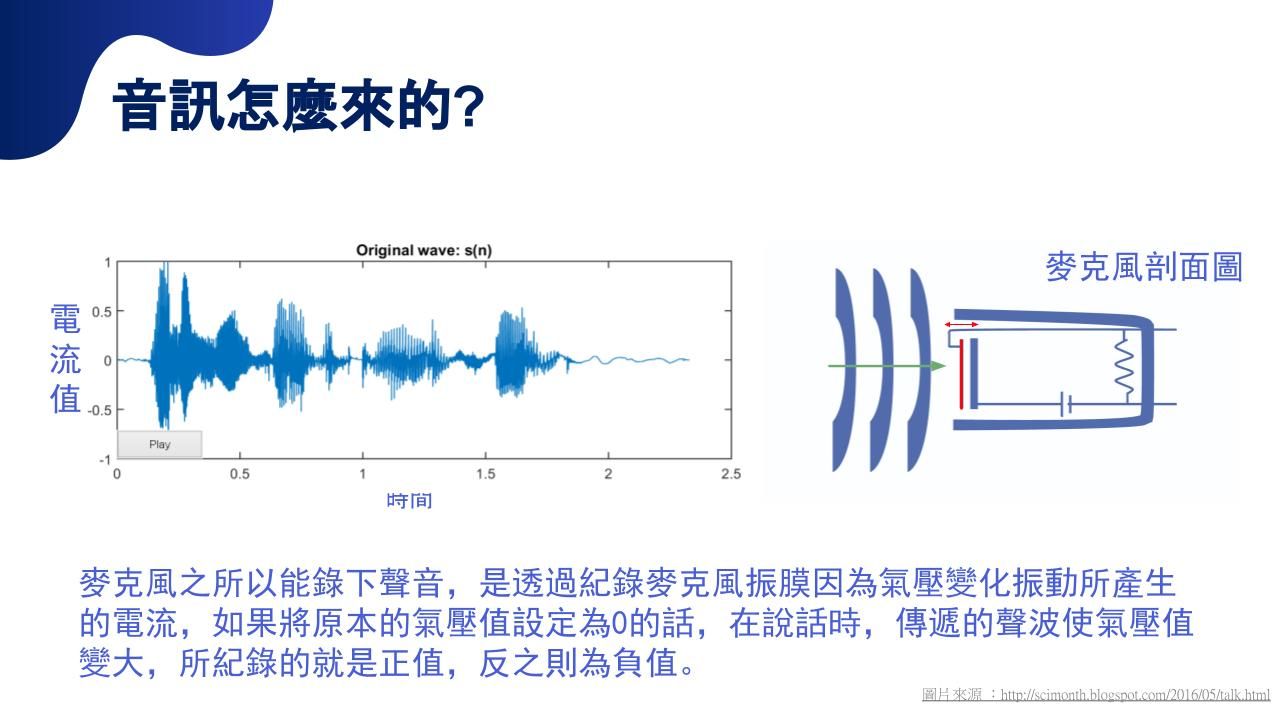
麥克風是怎麼收到聲音的?
空氣中震動的聲波,無法像圖像一樣可視化,那該如何將聲音表現為可被處理的資料呢?我們會將聲波振幅轉換成電流值記錄下來。以麥克風為例,麥克風內部的振膜會記錄空氣振動所產生的電流,當我們在說話時,因為聲波的疏波與密波一直往外傳遞,如下方圖片,紀錄麥克風通電及未通電的電流值就是我們的聲波。
音訊特徵處理方法
聲音在聲波傳遞的過程中被記錄成各種數值(電流量),這些數值對模型而言,是沒有規則或意義的數字。為了讓模型能夠判斷各別的差異,需要經過「特徵處理」才能將這些代表音訊的數字轉為模型可以處理的內容。
音訊特徵處理有許多方式,以語音辨識(ASR)的任務為例,特徵處理的過程是,先將這段聲音切成時間序列(sequence),由於聲音是連續的訊號,所以要將聲音切分成好幾段幀(frame),這裡的切分方式並不是獨立分段,而是用比frame更短的時間平移切分,例如:每個frame以25毫秒為一單位,那下一段frame會平移10毫秒,再切一次25毫秒的frame。透過這個方式,可以將聲音訊號切成時間序列,再利用STFT轉換成頻譜圖(spectrogram);接著丟入可以處理時間序列的模型,得到語音辨識的結果,如:音位(phoneme)、字(character)、詞(word),並使用語言模型組合成完整句子,完成語音辨識的流程。
而處理音訊的模型有許多類型,例如:可以將聲音檔案轉換成文字內容;丟入文字檔案後輸出成人念文字的音檔;或是將聲音轉化成非原來的聲音,例如:男生說話聲音變成女生說話聲音,不同的模型有不同的處理方法,音訊特徵處理的方式也會因為模型而有所不同。
如何進行聲源分離
「聲源分離」顧名思義是指不論是人的歌聲、說話聲、背景雜音、樂器聲等,透過模型將不同音訊精準分離,稱為聲源分離。假設今天有一段音樂,是由不同樂器錄製的音檔疊加而成,這個音樂的聲源分離就是要將不同樂器的聲音再分離出來。要完成聲源分離的任務,主要會分成兩個類別,分別是Frequency domain與Time-domain。
Frequency domain主要的做法有兩種,一種是對頻譜圖訓練遮罩(mask),讓遮罩消除其他聲源與噪音、只保留目標聲源,另一種是訓練一個U-Net模型(由二維卷積層組成、先降維再升維的模型)直接輸出目標聲源的頻譜圖,這兩種做法在輸入資料時會透過STFT(或類似的轉換)將聲波轉換成頻譜圖,輸出時再利用反向的inverse STFT將頻譜圖轉換回聲波的形式。
Time domain的作法就省去了STFT的步驟,模型的輸入與輸出都是聲波,通常是透過Wave-U-Net(一維卷積所組成的U-Net)對聲波做卷積以擷取特徵,有些模型會在卷積的最深處加上一個雙向的LSTM去學習資料的前後關聯(如Demucs模型)。
而近期在 Music Source Separation on MUSDB18 中分數較高的聲源分離模型是 Hybrid Demucs,是由Meta Research所建立的,是混合了以上兩種作法進行訓練,模型在接收到資料後一邊將聲波放入Wave-U-Net,另一邊將聲波轉換為頻譜圖放入U-Net,在中間會透過雙向LSTM進行資訊的交換,最後再各自輸出結果並合併,這樣的做法就能同時擷取到Frequency domain與Time domain的特徵,幫助我們完成聲源分離的任務。
了解AI如何處理音訊及聲源分離的模型架構,若對以上內容有興趣,Meta Research也有提供Hybrid Demucs 聲源分離模型的程式碼給不同需求的人使用,歡迎點選連結查看官方程式碼:Meta Research,目前也有線上版可以使用,請點選連結:聲源分離模型線上Demo




