
隨著 AI 模型近幾年越來越強大,所需要的參數量與運算量也越來越大。但在許多場合,可能沒辦法放著一台碩大的伺服器去進行 AI 運算,這時候就需要將模型放入邊緣裝置(Edge device)中,也就是所謂的「Edge AI」。
什麼是邊緣裝置(Edge device) ?
Edge device 是一個具備運算與聯網能力,能搜集、處理和傳送資料的小型硬體設備,相較於PC而言,價格較為便宜。因為功耗極小,可以僅使用電池或行動電源供電就能完成一些簡單的任務。不僅體積小,方便部署;也可以連接感測器,所以很適合蒐集各種感測資料,如:氣溫,並使用網路傳送回伺服器。
常見的邊緣裝置:

為什麼需要 Edge AI?實際使用會遇到什麼問題嗎 ?
模型訓練及執行模型是人工智慧的兩個重要流程,且大多仰賴大型伺服器進行模型訓練,但在實際場景中,不一定適合放置伺服器來進行運算。因此,透過 Edge device 搜集資料並回傳雲端運算後,再將結果回傳給 Edge device並進行邏輯判斷。但是,這些傳輸過程都需要時間,若有即時性的考量,應用將會受限,例如自駕車,假使偵測到路上行人,再經過資料回傳雲端運算後,等到自駕車收到回傳的結果後,再做煞停判斷,這中間的所經過的時間,即有可能車子已經撞到人。所以,如果 Edge device 本身具有 AI運算能力,就可以獨立搜集資料並做 AI 運算,就能達到即時性。
但是, Edge device 畢竟是個小型硬體設備,而目前的AI模型所需的參數量或運算量仍十分龐大,極可能因為運算力或硬體資源不夠,導致模型運算速度太慢或無法放入設備中的狀況。為了將AI模型放入設備中,且不影響精準度,模型壓縮就是一個方法。
模型壓縮的方法
模型壓縮顧名思義就是將模型縮小,讓參數量或是運算量降低,且在過程中不會過度影響模型準度。目前常見的方法主要有網路剪枝、量化參數,以及知識蒸餾。
網路剪枝是最早出現的模型壓縮方法,目標是刪除一個大模型中不重要的權重或神經元,隨後得到一個相對參數量較低的模型。這個方法要先有一個訓練好的大模型,接著找出權重與神經元的重要性,再刪除重要性較低的神經元,進而得到一個相對較小的模型,最後使用原本訓練的資料對小模型微調,始之可以使用剩餘的神經元進行學習。
量化參數則是目前常用的方法,其目標是以更少的電腦空間儲存模型訓練好的權重,以降低檔案大小與運算資源。Mix Precision 是其中一個作法,且在目前常見的深度學習API,如:Tensorflow、Pytorch 都有支援。通常,預設儲存於電腦空間的訓練參數大小都是浮點數 FP32 ,而這個方法則是希望能將半精度的 FP16 也加入訓練模型中,就能減少多餘浪費的空間,讓模型佔用的記憶體更小,並能在訓練時使用更大的 batch ,使模型在訓練時更加穩定。至於為什麼不要全部都用半精度的 FP16 進行訓練呢?因為會產生 underflow 的問題,在模型訓練後期,back propagation 運算出來的梯度非常小,甚至在乘以 Learning rate 後更小,在半精度的情況下,無法將小位數的數值儲存起來,因此,才需要混合 FP32跟 FP16做訓練。

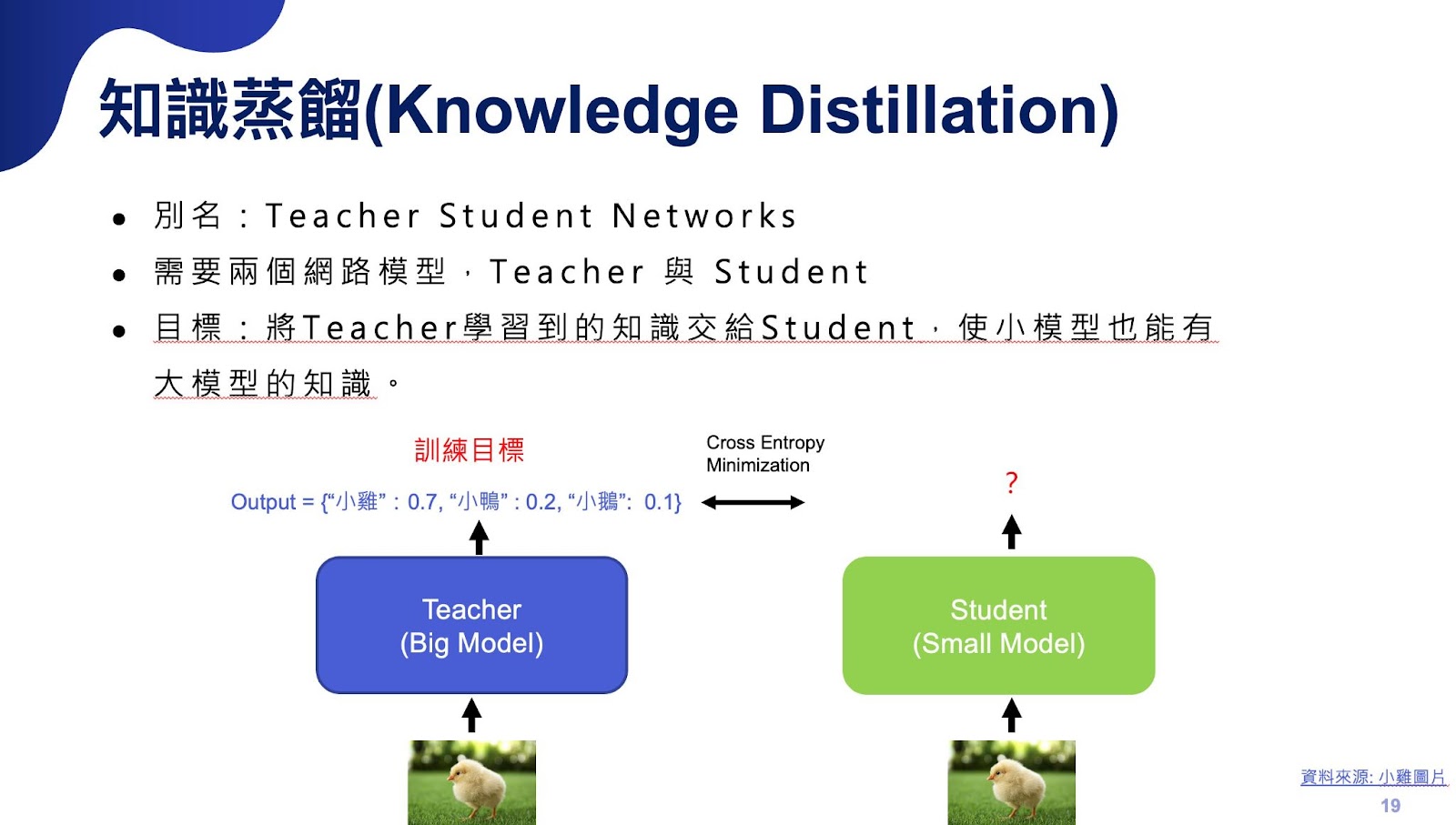
知識蒸餾則是近年來十分熱門的方法,它需要兩個AI 模型,一個是參數量大的模型(代稱「老師模型」),另一個是參數量小的模型(代稱「學生模型」)。以三個類別的圖像分類任務為例,通常會先以訓練資料訓練老師模型,讓老師模型學到任務的 pattern,接著將一張圖片輸入至老師模型中,並輸出每個類別的機率。然後,才是讓學生模型學習,它要跟老師模型學習的並不是單純的分類結果,而是每個類別分別輸出的機率。以一張小雞圖片為例,學生模型要向老師模型學習為什麼輸出為可能性 70% 的是小雞,而 20% 則是小鴨,並找出 20% 中的哪些特徵,讓模型產生出這些結果。目標是要讓學生模型學習到老師模型的輸出分佈,避免讓學生模型因為太依賴一些訓練圖片而偏向其中一個類別的結果。
隨著AI應用逐漸增加,預期未來 Edge device 與 AI 的應用將會越來越成熟,不論是在模型準確度或硬體設備的支援上,模型壓縮都會是個備受討論的議題。雖然,目前常見的做法是網路剪枝與量化參數,但如果要極致地壓縮模型,連帶精準度也會大受影響。而知識蒸餾將是未來會被大幅應用於實際場域的方法,除了可以更有效地壓縮模型大小,也能更大幅度保留模型精準度,且以知識蒸餾作為壓縮的方法也越來越多,後續應用也十分值得期待。




