
在前一陣子的文章有談到 Apple M系列強大的 GPU 與 ANE 強大的計算能力,這次文章會再強調 Apple 晶片的一大特色「統一內存架構 (unified memory architecture)」。它使得 CPU 與 GPU 可以直接使用相同的記憶體區塊(momory pool),這樣的優勢在於可以減緩 CPU 與 GPU 記憶體存取上的延遲,避免不必要的效能損耗。
一、前言與任務說明
這次文章使用 Apple 新發布的深度學習框架 MLX(ml-explore),完成圖片深度圖(depth map)的預測任務,深度圖預測任務常應用在自駕車的場景,通常獲取圖片「深度」資訊可以知道前方物體距離拍攝者多遠,簡單來說可以透過距離資訊來避開障礙物。常見獲取距離資訊的方式:
- LiDAR:又稱光學雷達,透過可見光或不可見光照射物體,透過捕獲反射來計算距離
- 雙鏡頭測距:透過雙鏡頭各拍一張照片,利用圖片視差進行量測
- 單鏡頭量測:透過預先準備好的資料(圖片、深度圖),進行深度學習的學習訓練,使得能透過電腦來推論出距離 (本文採用的方式)
Github:depth_map.git
二、環境配置
- 使用 apple m系列的晶片
- python ≥ 3.8
- macOS ≥ 13.3
- 建議搭配 Conda 環境開發,Conda 環境安裝方式可以參考這篇(第二章節)
-
ordered item 2
- conda create -n mlx python=3.10
- conda activate mlx
- pip install mlx
三、資料集準備與說明
資料下載位置(Kaggle) : https://www.kaggle.com/datasets/sakshaymahna/cityscapes-depth-and-segmentation
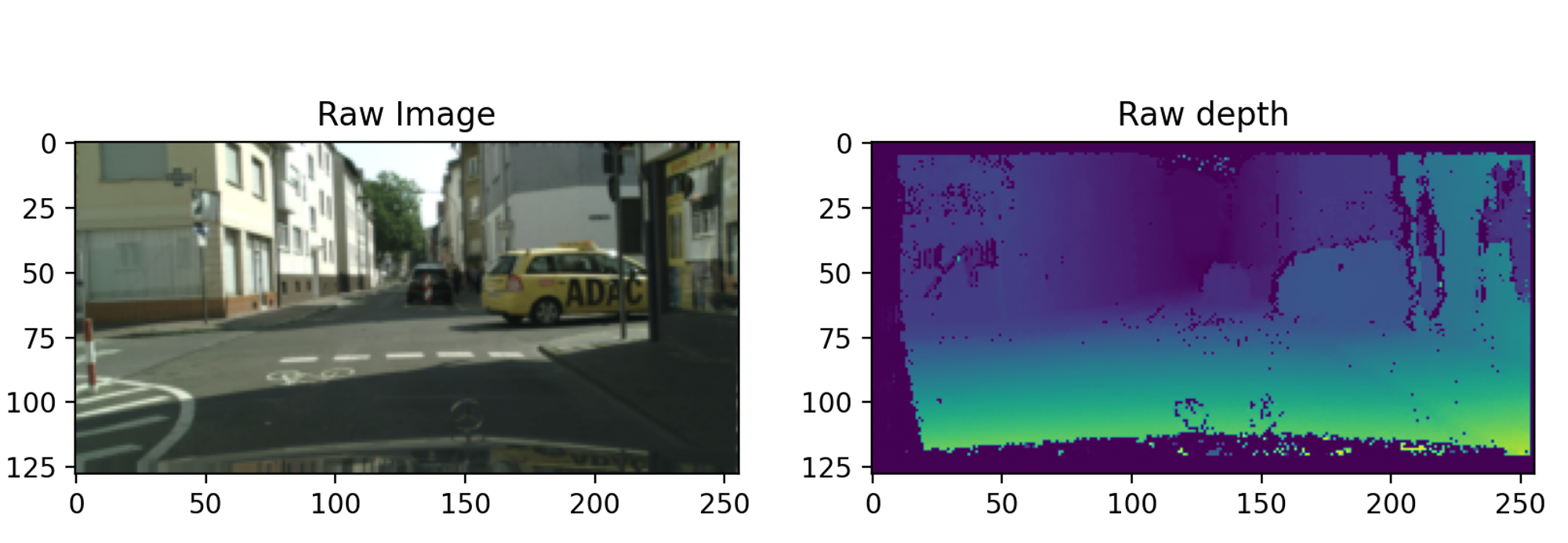
四、訓練流程
1. Samples & Buffer & Streams (like: pytorch Dataset, Dataloader)
- Samples
- 讀取 npy 檔案,為確保輸入資料與標籤資料對齊所以進行排序,這邊透過 os.listdir() 取出檔名清單
npy_datas_x = sorted(os.listdir(path + "image"))
npy_datas_y = sorted(os.listdir(path + "depth"))
2. 將 npy 檔名清單與相對路徑組合,並將結果轉換成”ascii”編碼以符合 MLX 讀檔要求
data_path = path + "image/" + npy_datas_x[i]
label_path = path + "depth/" + npy_datas_y[i]
data_paths.append(data_path.encode("ascii"))
label_paths.append(label_path.encode("ascii"))
3. 輸出格式必須是 “List”, 儲存內容以一筆資料為單位的 “dictionary”
return [
{
"x_file":data,
"y_file":label
}
for data, label in zip(data_paths, label_paths)
]
- Buffer
將上一步準備好的 list 資料,轉換成 mlx buffer,可以透過 index 對其讀取每一筆資料,根據 Samples 的資料種類會對應到不同的轉換 function。最常見方式 buffer.from_vector(),針對 Samples 輸出是 list 格式。官方文件針對不同 Samples 處理方式 (Buffer api)。
train_dataset = dx.buffer_from_vector(collect_data(train_data_path))
vaild_dataset = dx.buffer_from_vector(collect_data(valid_data_path))
- Streams
train_dataloader = (
train_dataset
.shuffle()
.to_stream() # <-- making a stream from the shuffled buffer
.load_numpy("x_file", output_key="image")
.load_numpy("y_file", output_key="label")
.key_transform("image", lambda x: x * 255)
.key_transform("image", aug_fn)
.batch(batch_size)
.prefetch(8, 8)
)
使用 MLX 的Stream 機制實作資料讀取、資料前處理與 Batch 設定
- shuffle() : 將 Buffer 資料打亂順序
- to_stream() : 通常資料量過於龐大,沒有辦法一次讀取,所以透過 stream 方式建立資料迭代器,批次讀取資料。
- load_numpy() : 因為資料是 numpy 格式,所以使用 load_numpy,官方文件有提供其他資料讀檔方式(I/O operations)。
使用格式: (key,output_key)
key : dataset 第 3 點建立 dictionary 時所設定的 key,output_key : 資料讀取對應的key。
4. key_transform() : 主要進行資料轉換方法,使用格式 (key, function) ,下面介紹兩種常見的作法。
key : dataset 第 3 點建立 dictionary 時所設定的 key
- lambda:通常用於簡易的資料處理,e.g 圖片來說就是正規化(0~1),本文所使用的資料在 kaggle 上已經正規化完成,所以跳過此步驟。
key_transform("image", lambda x: x / 255)
2. function : 通常用於複雜資料處理,e.g 資料擴增。
資料擴增方法 (aug_fn) 參考 Github
key_transform("image", aug_fn)
- 如果沒有設定 output_key 將會覆蓋原有的值
5. batch() : 設定訓練時 batch 大小。
使用格式: batch(int )
6. prefetch() : 設定以多少線程完成資料處理,e.g. prefetch(16, 8) 8 筆資料用 8 個線程完成,通常第一個數值會是 batch 大小,第二個數值會隨運算資源調整。
- 如何取資料,根據上面定義的 key 取得對應的資料,記得將資料轉換成 mx.array()。
e.g “image” 圖片資料, “label”標籤資料
for batch in dataloader:
x = mx.array(batch[“image”])
y = mx.array(batch[“label”])
2. Training pipeline
- 模型架構
如果熟悉 PyTorch 的話會對他的模型設計方法不陌生,大致使用方式相同,下面提醒一些需要主義的項目:
- 在PyTorch中的向前傳播使用 forward(),在 MLX 使用 call()
- 在PyTorch中 Batch Normalization layer 會依據輸入維度不同而選擇不同的 function,在MLX統一一種 BatchNorm()
- 大多 function 命名方式跟 PyTorch 不同,但跟 Numpy 相同,以 Numpy的命名方式在官方文件較容易找到目標
- 因為 MLX 目前還正在開發中,很多 layer function 還沒有 PyTorch 完善
- MLX layer 文件
- Loss function & Update parameter
- loss function
本文要解決的任務是距離預測任務,所以 Loss function 以回歸的 Loss 為主,huber_loss(),因為模型輸出 與 label 要越相近越好,所以本文多選擇 cosine_similarity_loss(),來計算模型輸出與 label 的相似度。
- 注意:MLX 的 loss 需要傳入 model
def loss_fn(model, x, y):
output = model(x)
loss1 = nn.losses.huber_loss(output, y, reduction='mean')
loss2 = nn.losses.cosine_similarity_loss(output, y, reduction='mean')
return loss1+((1-loss2)*0.5)
- nn.value_and_grad()
使用這個 function 定義在訓練過程用何種 loss function,且回傳梯度,用optimizer 參數更新。
loss_and_grad_fn = nn.value_and_grad(model, loss_fn)
(loss), grads = loss_and_grad_fn(model, x, y)
- optimizer.update()
MLX 的參數更新與 PyTorch 最大的不同是,MLX 不需要手動將梯度歸零。
optimizer.update(model, grads)
- training compile
compile 這個功能在 PyTorch2.0 之後也有支援,這可以大幅改進訓練過程的計算效率與記憶體的使用,目前使用上需要注意的是,如果訓練過程中有使用到非 MLX 的套件,會造成 error。
@partial(mx.compile, inputs=state, outputs=state)
def step(x, y):
loss_and_grad_fn = nn.value_and_grad(model, loss_fn)
(loss), grads = loss_and_grad_fn(model, x, y)
optimizer.update(model, grads)
return loss
compile 也可以單獨讀對定的 function,可以參考這裡教學。
3. Save model
- 使用 tree_flatten(model.parameters()) 將模型當中的 layer name 與 weight 做打包成 python tree,最後使用 mx.savez(path, **dict(flat_params)) 儲存模型。
flat_params = tree_flatten(model.parameters())
mx.savez("savemodel/model.npz", **dict(flat_params))
- MLX提供另外兩種儲存模型的格式用於大型模型 gguf, safetensors
五、模型推論
1. Load model
model = resnet20()
model.load_weights("savemodel/model.npz")
mx.eval(model.parameters())
2. Inference pipeline
過程跟PyTorch相同,差異只在將輸入資料要轉換成 mx.array()
img = np.load("data/val/image/0.npy")
img = np.expand_dims(img, axis=0)
img = mx.array(img)
depth_map = model(img)
六、補充:如果是圖片分類模型如何修改
1. Buffer
- Load Image : 使用 load_image(key, output_key) 可以讀取 .png, .jpg….圖片格式
- MLX 提供一些基礎的圖片處理工具,Image operations
2. Loss function
七、總結
在以往的深度學習框架都是以 Pytorch, Tensorflow, Jax….為大宗,直到現在也是如此,我們可以在paper with code 的趨勢中可已觀察到,如圖二所示,其中又以 PyTorch 為主流。
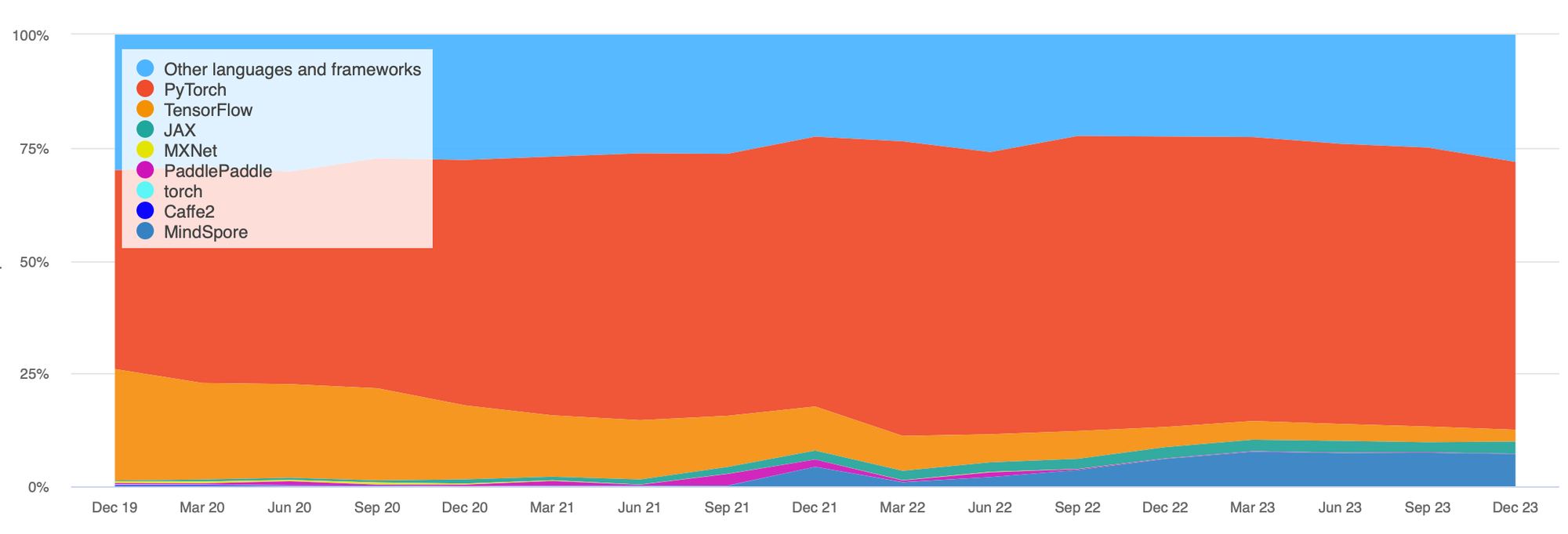
從圖二看到的這些框架,都是以 Nvidia 計算設備為主,如果要訓練大型模型所需要耗費的硬體成本是非常高的,而這些工具轉換至 Apple 設備上往往優化沒有像 Nvidia 設備上完善,而這樣就剛好突顯 Apple 的優勢,在相同的記憶體的計算資源下,Apple 的設備成本是低於 Nvidia,然而 Apple 的 MLX 又針對自家設備深度優化,對於一般的工程師來說是非常有吸引的,還有部署端 Iphone 的市佔率,可以想像Apple一條龍整合是非常有潛力。
- 計算設備 : mac
- 開發工具:MLX
- 部署工具 :CoreML, Swift
- 部署設備:Iphone
資料來源:




