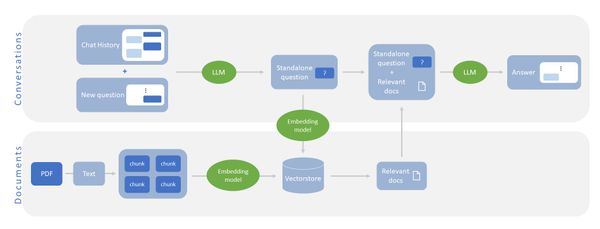
檢索增強生成 (Retrieval Augmented Generation, RAG) 是近期的熱門應用技術之一,但要建立一個足夠穩定的 RAG 架構,並不容易。本篇文章著重在 RAG 技巧中的流程設計與調整,帶領大家快速了解一些實用的 RAG 模組,也透過實際操作,學習 LangChain 與 LangGraph 工具
LLM 實作系列文章
檢索增強生成 (Retrieval Augmented Generation, RAG) 近期在 LLM 的強大威力下,成為熱門應用技術之一,透過提供特定的檢索資料 (e.g. 公司內部文件),使得 LLM 的回應更加穩定,也讓使用者能更快速地得到問題解答。
然而要建立一個實際使用時,足夠穩定的 RAG 架構,並非那麼容易。對於檢索資料的處理、搜尋結果的精準程度、或是生成結果的後處理或檢核等方面都需要特別設計,也是現今仍不斷有新方法或模組被提出的原因。
本篇文章著重在 RAG 技巧中的流程設計與調整,參考 Adaptive RAG 中所提出的架構以及 LangChain團隊之實作範例,並將其精簡化,希望帶領大家快速了解一些實用的 RAG 模組,也透過實際操作,學習 LangChain 與 LangGraph 工具如何協助快速建立 LLM 相關服務流程。
Note:若對 RAG 流程的各步驟 (如:向量資料庫(vectorstore)的用途與使用方式) 不熟悉的讀者們,可參考本文開頭所提到的LLM實作系列文章或是自行搜尋 LLM 先行了解相關內容喔。
進階RAG流程說明
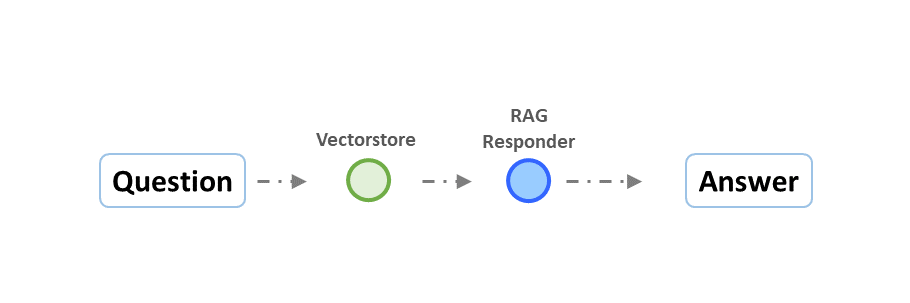
圖一:基本的 RAG 流程。
上圖為最簡單的 RAG 流程。首先,問題 (Question) 會進入到 vectorstore 內提取最相近的文件,接著文件與問題會同時交由 LLM 產生答案。

圖二:本次實作之 RAG 流程。
其中綠色圓圈代表流程中使用到的工具節點,藍色圓圈代表 LLM 節點,而橘色菱形則代表 Route 模組,將會依照判斷結果將其導向不同的節點。
而此圖則為本次實作的 RAG 流程,在單純的 RAG 中加入了許多不同的模組進行處理,在此又區分為圖左側的 Query Analysis 與右側的 RAG+Self-reflection 兩大塊,以下分別進行說明。
Query Analysis
透過分類器將問題導向不同的工具或模組中。在Adaptive RAG論文中主要目的是區分問題的複雜程度,並依照複雜程度低到高分別交由 LLM 自身回應、使用內部資料庫 (vectorstore) 後回應、或進行網路搜尋後回應。而在本次實作中則調整為依照問題面向不同,而調整使用的工具。
note : 在實際應用中此機制非常常見,透過判斷問題的性質將其分流至專門處理此類型問題的流程中。
RAG + Self-reflection
此部分主要借用了CRAG與Self-RAG的概念 (note:在此沒有做模型finetune),利用多個判斷機制確認提取資料與模型生成答案的有效性,並且在失敗時重回先前的模組再次執行。
此次的流程中納入的判斷模組如下:
- Retrieval grader:利用 vectorstore 或 web search 等工具搜尋資訊後,針對每篇結果判斷是否與問題相關,並將無關的結果刪除,降低提供無效資訊讓 LLM 生成回應的可能性。(後續若所有結果皆與問題無關,將會重新使用網路搜尋功能再行嘗試,否則即交由 RAG Responder進行答案生成)
- Hallucination grader:RAG Responder 生成回應後,確認此回應是基於檢索的資訊而產生,而不是 LLM 自身的知識或是幻覺,降低提供錯誤資訊的可能性。(若為幻覺則需重新生成,否則可進入 Answer grader 流程)
- Answer grader:RAG Responder 生成回應並通過 Hallucination grader 判斷後,再度確認答案是否是針對問題回應。(若否則重回 web search 工具重新搜尋相關的資訊)
實作時間
這次我們同樣使用 langChain 框架幫助我們建立 RAG 的架構。另外,在 2024 年 1 月 langChain 團隊也提出了 langGraph 套件以方便使用者建立和維護較為複雜的 LLM 應用流程,若對 langGraph 不熟悉的讀者們,透過這次實作應該能很快地掌握這個框架。
以下我們將依序說明程式碼內容(想一次執行完成的讀者們請直接開啟上面的連結)
0. 載入套件與設定 API_KEY
在本次的實作中我們使用 OpenAI gpt-3.5 與 text-ada-embedding-002 作為 LLM 與 embedding model,另外在網路搜尋功能上則使用 Tavily Search API,請讀者們事先申請相對應的 API_KEY (OpenAI API需要付費才能使用,Tavily Search API則有每個月的免費額度)。
import gdown
import os
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_openai.chat_models import ChatOpenAI
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.output_parsers import StrOutputParser
from typing_extensions import TypedDict
from typing import List
from langchain.schema import Document
from langgraph.graph import END, StateGraph
os.environ["OPENAI_API_KEY"] = <your_openai_api_key>
os.environ['TAVILY_API_KEY'] = <your_tavily_api_key>
1. 建立 Vectorstore 與 Web Search tool
首先我們先建立流程中需要使用的工具(圖二中的綠色圓點)。
本次實作使用衛服部的牙周病診治健康照護手冊做為內容,並利用Chroma建立向量資料庫。
為使得流程簡潔,Chunk 切分的方式單純以固定長度做切分,若實際應用情境上文件更新頻率極低,則可以人為切割 chunk 使得某個 chunk 的語意完整度更高。
# 下載範例檔案
gdown.download("https://drive.google.com/file/d/1IuPEquZCw19VQxoLOvF6bc1WrfHn84ks/view?usp=sharing", fuzzy = True)
# 讀入範例所使用的 pdf 檔案
loader = PyPDFLoader("/content/牙周病診治健康照護手冊.pdf")
# 定義splitter,將所有文字切分成不同的chunk
splitter = RecursiveCharacterTextSplitter(chunk_size = 512, chunk_overlap = 128)
doc_split = loader.load_and_split(splitter)
# 定義要使用哪個Embedding model 將chunk內的文字轉為向量
embeddings = OpenAIEmbeddings()
# 使用Chroma建立vectorstore,並將其轉為retriever型態
vectorstore = Chroma.from_documents(
documents=doc_split,
embedding=embeddings,
)
retriever = vectorstore.as_retriever()
# web search tool
web_search_tool = TavilySearchResults()
2. 建立 LLMs
接著我們開始建立流程中需使用到的 LLM 模組與其 Prompt (圖二中的藍色圓形與橘色菱形部分),各模組功能請參考本文稍早的描述。
Question Router
負責根據問題內容選擇後續使用的工具
# 定義兩個工具的 DataModel
class web_search(BaseModel):
"""
網路搜尋工具。若問題與牙周病治療或照護"無關",請使用 web_search 工具搜尋解答。
"""
query: str = Field(description="使用網路搜尋時輸入的問題")
class vectorstore(BaseModel):
"""
紀錄關於牙周病治療或照護的向量資料庫工具。若問題與牙周病治療或照護有關,請使用此工具搜尋解答。
"""
query: str = Field(description="搜尋向量資料庫時輸入的問題")
# Prompt Template
instruction = """
你是將使用者問題導向向量資料庫或網路搜尋的專家。
向量資料庫包含有關牙周病治療或照護文件。對於這些主題的問題,請使用向量資料庫工具。其他情況則使用網路搜尋工具。
"""
route_prompt = ChatPromptTemplate.from_messages(
[
("system",instruction),
("human", "{question}"),
]
)
# Route LLM with tools use
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
structured_llm_router = llm.bind_tools(tools=[web_search, vectorstore])
# 使用 LCEL 語法建立 chain
question_router = route_prompt | structured_llm_router
RAG Responder
負責根據問題與提取的文件擬定答案
# Prompt Template
instruction = """
你是一位負責處理使用者問題的助手,請利用提取出來的文件內容來回應問題。
若問題的答案無法從文件內取得,請直接回覆你不知道,禁止虛構答案。
注意:請確保答案的準確性。
"""
prompt = ChatPromptTemplate.from_messages(
[
("system",instruction),
("system","文件: \n\n {documents}"),
("human","問題: {question}"),
]
)
# LLM & chain
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
rag_chain = prompt | llm | StrOutputParser()
Plain LLM
不利用額外的資訊,單純根據問題做出回應
# Prompt Teamplate
instruction = """
你是一位負責處理使用者問題的助手,請利用你的知識來回應問題。
回應問題時請確保答案的準確性,勿虛構答案。
"""
prompt = ChatPromptTemplate.from_messages(
[
("system",instruction),
("human","問題: {question}"),
]
)
# LLM & chain
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
llm_chain = prompt | llm | StrOutputParser()
Retrieval grader
負責判斷提取出的文件內容是否與問題有關
class GradeDocuments(BaseModel):
"""
確認提取文章與問題是否有關(yes/no)
"""
binary_score: str = Field(description="請問文章與問題是否相關。('yes' or 'no')")
# Prompt Template
instruction = """
你是一個評分的人員,負責評估文件與使用者問題的關聯性。
如果文件包含與使用者問題相關的關鍵字或語意,則將其評為相關。
輸出 'yes' or 'no' 代表文件與問題的相關與否。
"""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system",instruction),
("human", "文件: \n\n {document} \n\n 使用者問題: {question}"),
]
)
# Grader LLM
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# 使用 LCEL 語法建立 chain
retrieval_grader = grade_prompt | structured_llm_grader
Hallucination grader
負責判斷 LLM 生成的答案是否為幻覺(hallucination)
class GradeHallucinations(BaseModel):
"""
確認答案是否為虛構(yes/no)
"""
binary_score: str = Field(description="答案是否由為虛構。('yes' or 'no')")
# Prompt Template
instruction = """
你是一個評分的人員,負責確認LLM的回應是否為虛構的。
以下會給你一個文件與相對應的LLM回應,請輸出 'yes' or 'no'做為判斷結果。
'Yes' 代表LLM的回答是虛構的,未基於文件內容 'No' 則代表LLM的回答並未虛構,而是基於文件內容得出。
"""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system",instruction),
("human", "文件: \n\n {documents} \n\n LLM 回應: {generation}"),
]
)
# Grader LLM
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# 使用 LCEL 語法建立 chain
hallucination_grader = hallucination_prompt | structured_llm_grader
Answer grader
負責確認 LLM 生成的答案是否可回應問題
class GradeAnswer(BaseModel):
"""
確認答案是否可回應問題
"""
binary_score: str = Field(description="答案是否回應問題。('yes' or 'no')")
# Prompt Template
instruction = """
你是一個評分的人員,負責確認答案是否回應了問題。
輸出 'yes' or 'no'。 'Yes' 代表答案確實回應了問題, 'No' 則代表答案並未回應問題。
"""
# Prompt
answer_prompt = ChatPromptTemplate.from_messages(
[
("system",instruction),
("human", "使用者問題: \n\n {question} \n\n 答案: {generation}"),
]
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeAnswer)
# 使用 LCEL 語法建立 chain
answer_grader = answer_prompt | structured_llm_grader
3. 定義 Graph
同圖二:本次實作之 RAG 流程。
在langGraph中會以graph來表示LLM應用的流程,相較於原先langChain 較屬於線性的設計,利用graph可簡單地處理較為複雜的流程問題(e.g. 需要重回上一步或循環的狀況)。
Graph中包含了兩種重要的元素:節點(Node)與邊(Edge)。以graph形式呈現LLM流程時,節點(Node)代表著處理單元,經由某節點處理過後的資訊(在後續稱為graph state)應該進到後續的哪個流程則由邊(Edge)決定。以圖二的資訊做說明,其中綠色圓圈代表工具節點,藍色圓圈代表LLM節點,而橘色菱形則代表Route模組(conditional Edge),將會依照判斷結果將其導向不同的節點。
Graph State
Graph State中會記錄不同Nodes需要共享的資訊,在本次的實作中需要紀錄的資訊包含了問題(question)、透過工具提取的資訊(documents)、以及LLM產生的回應(generation)。
class GraphState(TypedDict):
"""
State of graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question : str
generation : str
documents : List[str]
Nodes
接著我們開始建立graph中每個Node (圖二中的圓圈部分,包含了綠色的工具與藍色的LLM),其會依照當下的Graph State執行特定任務並更新State的內容。
def retrieve(state):
"""
Retrieve documents related to the question.
Args:
state (dict): The current state graph
Returns:
state (dict): New key added to state, documents, that contains list of related documents.
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents":documents, "question":question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"] if state["documents"] else []
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = [Document(page_content=d["content"]) for d in docs]
documents = documents + web_results
return {"documents": documents, "question": question}
def retrieval_grade(state):
"""
filter retrieved documents based on question.
Args:
state (dict): The current state graph
Returns:
state (dict): New key added to state, documents, that contains list of related documents.
"""
# Grade documents
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
documents = state["documents"]
question = state["question"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke({"question": question, "document": d.page_content})
grade = score.binary_score
if grade == "yes":
print(" -GRADE: DOCUMENT RELEVANT-")
filtered_docs.append(d)
else:
print(" -GRADE: DOCUMENT NOT RELEVANT-")
continue
return {"documents": filtered_docs, "question": question}
def rag_generate(state):
"""
Generate answer using vectorstore / web search
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE IN RAG MODE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"documents": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def plain_answer(state):
"""
Generate answer using the LLM without vectorstore.
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE PLAIN ANSWER---")
question = state["question"]
generation = llm_chain.invoke({"question": question})
return {"question": question, "generation": generation}
Conditional edge
最後,圖二中的橘色菱形代表的是Conditional edge,其會針對Graph State中的內容進行判斷決定流程後續進入到哪個Node中。
註一:grade_rag_generation包含了hallucination_grader與answer_grader兩個判斷。
註二:在完整的程式碼中將會額外印出特定的資訊使讀者在執行時能夠快速了解整個graph運作的流程。
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
question = state["question"]
source = question_router.invoke({"question": question})
# Fallback to plain LLM or raise error if no decision
if "tool_calls" not in source.additional_kwargs:
return "plain_answer"
if len(source.additional_kwargs["tool_calls"]) == 0:
raise "Router could not decide source"
# Choose datasource
datasource = source.additional_kwargs["tool_calls"][0]["function"]["name"]
if datasource == 'web_search':
return "web_search"
elif datasource == 'vectorstore':
return "vectorstore"
def route_retrieval(state):
"""
Determines whether to generate an answer, or use websearch.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
return "web_search"
else:
# We have relevant documents, so generate answer
return "rag_generate"
def grade_rag_generation(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
grade = score.binary_score
# Check hallucination
if grade == "no":
# Check question-answering
score = answer_grader.invoke({"question": question,"generation": generation})
grade = score.binary_score
if grade == "yes":
return "useful"
else:
return "not useful"
else:
return "not supported"
完成了上述的前置作業後,我們終於可以將 graph 的各個部分都連接起來。同樣地,對於 langGraph 還不熟悉的讀者們,可以將以下的程式碼與圖二相互對照,可以很快地了解 langGraph 的方便。
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("retrieval_grade", retrieval_grade) # retrieval grade
workflow.add_node("rag_generate", rag_generate) # rag
workflow.add_node("plain_answer", plain_answer) # llm
# Build graph
workflow.set_conditional_entry_point(
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
"plain_answer": "plain_answer",
},
)
workflow.add_edge("retrieve", "retrieval_grade")
workflow.add_edge("web_search", "retrieval_grade")
workflow.add_conditional_edges(
"retrieval_grade",
route_retrieval,
{
"web_search": "web_search",
"rag_generate": "rag_generate",
},
)
workflow.add_conditional_edges(
"rag_generate",
grade_rag_generation,
{
"not supported": "rag_generate", # Hallucinations: re-generate
"not useful": "web_search", # Fails to answer question: fall-back to web-search
"useful": END,
},
)
workflow.add_edge("plain_answer", END)
# Compile
app = workflow.compile()
實際測試
我們可以透過以下程式碼來試著提出幾個問題
def run(question):
inputs = {"question": question}
for output in app.stream(inputs):
print("\n")
# Final generation
if 'rag_generate' in output.keys():
print(output['rag_generate']['generation'])
elif 'plain_answer' in output.keys():
print(output['plain_answer']['generation'])
run("牙周病該怎麼治療?")
根據提取出來的文件內容,牙周病的治療方式包括非手術性治療和手術性治療。非手術性治療包括洗牙、牙根整平術等,而手術性治療則包括牙周翻瓣手術和牙周再生手術等。此外,支持性治療也是治療的重要一環,包括定期回診、洗牙、牙周探測紀錄等。患者也應該學會口腔清潔及維護,使用潔牙工具如牙刷、牙線、牙縫刷等,以維持治療效果。因此,患者應在牙醫師的協助下,選擇最適合自己的治療方法。
run("你好")
你好!有什麼問題我可以幫助你解答嗎?
run("台灣的總統府在哪個城市?")
台灣的總統府位於台灣的首都台北市。
從上面的範例可以看到對於不同類型的問題,本次的 RAG 流程皆可回覆出適當的內容。另外,為展現此次實作的內部運作流程,以下呈現使用完整程式碼執行時所產生的輸出。
run("牙周病要手術治療的話需要花多少錢")
---ROUTE QUESTION---
-ROUTETO VECTORSTORE-
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
-GRADE: DOCUMENT NOT RELEVANT-
-GRADE: DOCUMENT NOT RELEVANT-
-GRADE: DOCUMENT NOT RELEVANT-
-GRADE: DOCUMENT NOT RELEVANT-
---ROUTE RETRIEVAL---
-DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, ROUTE TO WEB SEARCH-
---WEB SEARCH---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
-GRADE: DOCUMENT RELEVANT-
-GRADE: DOCUMENT RELEVANT-
-GRADE: DOCUMENT RELEVANT-
-GRADE: DOCUMENT RELEVANT-
-GRADE: DOCUMENT RELEVANT-
---ROUTE RETRIEVAL---
-DECISION: GENERATE WITH RAG LLM-
---GENERATE IN RAG MODE---
---CHECK HALLUCINATIONS---
-DECISION: GENERATION IS GROUNDED IN DOCUMENTS-
---GRADE GENERATION vs QUESTION---
-DECISION: GENERATION ADDRESSES QUESTION-
根據提取出來的文件內容,大多數的牙周病治療在台灣是納入健康保險補助的範疇,通常患者只需支付健保費用加上部分自費金額,總金額落在$150到$470之間。然而,牙周病治療中仍有一些項目是不納入健康保險的自費項目,包括一些特殊的手術。因此,若需要進行特殊手術治療,可能需要支付額外的費用,具體金額可能會因醫療機構、醫師診斷及治療方式而有所不同。
透過輸出,可以發現最初根據問題的領域,此服務首先使用 vectorstore 來搜尋相關資訊,然而在 Retrieval_grade 時發現所有資訊皆無法回應問題,因此改為使用 web search 工具來進行額外的搜尋,最終才依其資訊做 RAG 回覆並通過其餘確認。
結語
為使流程較為順暢與簡潔,本次實作未加入太多複雜的機制,一些可能的模組或機制在此列出,希望能帶給讀者們更多想法
- 搜尋功能的優化 (e.g. 改寫問題進行 multi-query retrieve)
- 搜尋結果的後處理 (e.g. re-rank module)
- 重新嘗試的上限次數
- 針對特定問題類型拒絕回應的機制
透過本次的實作,希望讀者對於 RAG 的配套模組或機制能有更深入的認識,也能夠利用 langChain 與 langGraph 建立自己的 RAG 流程。
(撰稿工程師:蔡岳霖)