「一週又過去了,這次meeting的期刊報告你準備好了嗎?」、「說好的產業分析報告整理得怎麼樣了?」以上場景是否讓人覺得似曾相識?
被看不完的文件追著跑的人有福了!在OpenAI推出ChatGPT後,許多神奇的小工具也隨之出現─ChatPDF就是其中一個很好的應用。使用者只要上傳自己的PDF檔,不論是論文、新聞、產業報告甚至是書籍,都可以透過提問的方式,快速進行文件摘要總結,甚至請它提供建議。是不是讓人很心動?
目前ChatPDF的免費額度上限是每天3個120頁內的文件,總共可以問50個問題。看到這裡,如果你急著趕報告的話,可以先去趕進度沒關係。但是,如果想知道如何打造一個文件對話的工具,肯定要繼續看下去。我們會教各位如何簡單利用LangChain實作ChatPDF的功能,不用受每日的提問上限,讓人想問多少就問多少!
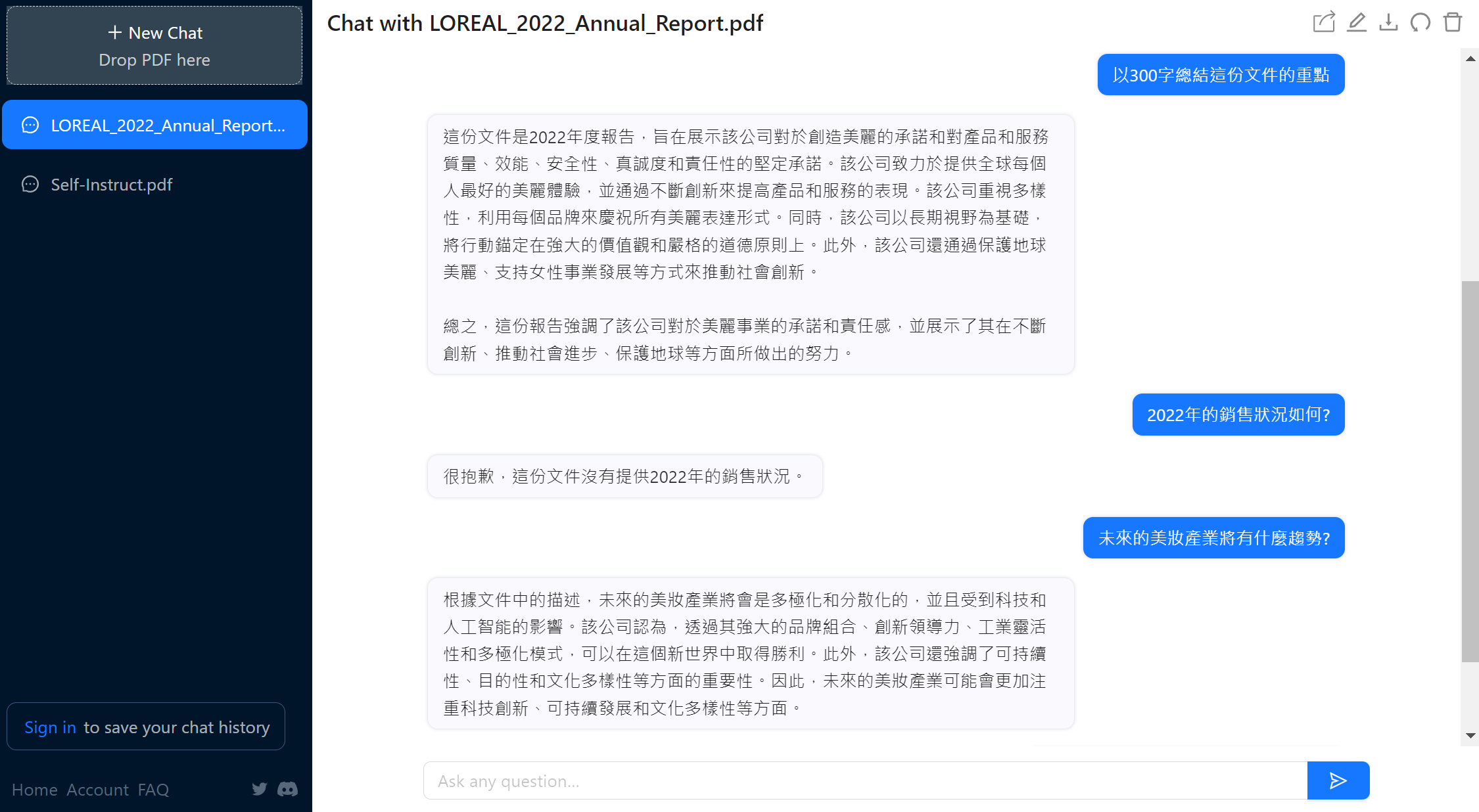
LangChain是一個框架,幫助我們在開發應用程式時導入語言模型的功能,可以更快速的將資料來源連接到語言模型,並使用語言模型進行後續處理。開始之前,我們先來看看ChatPDF的效果,範例中,我們以巴黎萊雅集團2022年的年度報告為例,對ChatPDF提出幾個簡單的問題,它會依照文件的內容進行回答。
利用LLM做出文件問答
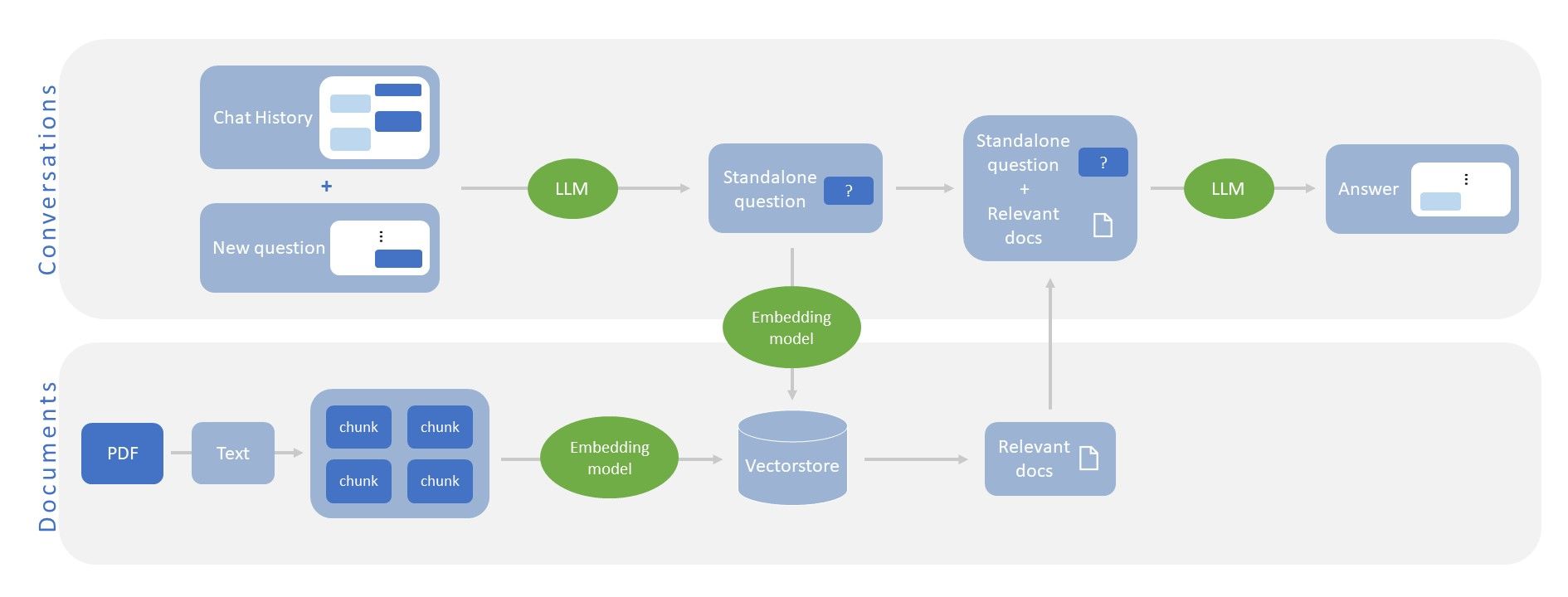
文件問答的做法大致可分為四個步驟,且每一個步驟中都會使用到LLM:
1. 將文件儲存成vector store
由於LLM輸入的字數通常都有上限,我們在讀取PDF檔後會對文字做切割,切分成多個小的區塊(chunk),並使用一個embedding model將文字轉換成向量,儲存成vector store以供後續查詢。
2. 在對話中提出問題
問答系統會記錄聊天的過程,當使用者提出新的問題時,會利用LLM將之前的對話以及新的問題,改寫成一個獨立的問句,這樣就不用把整個對話紀錄都丟進去做查詢。
3. 搜尋文件中與問題最相關的部分
使用剛剛的embedding model將問題本身轉換成向量,就可以查詢vector store中與問題最相關的部分有哪些段落。
4. 針對問題並根據相關文件進行回答
取出最相關的內容之後,讓LLM閱讀問題以及相關文件的內容,最後給出答案。

實作解析
接下來我們會使用LangChain實作出文件問答的功能,習慣使用介面的人可以先使用ChatPDF就好,但如果想要更了解流程和程式碼的人可以繼續往下。
首先,將相關套件安裝並import 進來
設定你的OpenAI API key(https://platform.openai.com/account/api-keys)
讀取PDF檔案。這裡我們使用LangChain提供的讀檔方式。
由於語言模型一次能讀取的文字數量有限,我們需要將文件切分成多個小區塊。
選擇一個欲使用的embedding模型 (也可以使用HuggingFace上其他的模型),並透過Chroma (一個專門為LLM embedding database設計的工具) 將剛剛的文字轉換成向量,最後儲存成一個本地的vector store。
最後建立對話chain,這裡我們使用LangChain的ConversationalRetrievalChain,每次都根據使用者提出的問題 (question) 以及對話紀錄 (chat_history) 對文件進行搜索。其中,所使用的LLM也可以替換成其他模型。
如果我們想要使用到對話的功能,必須每次將對話紀錄儲存起來並交給對話chain,在這裡我們使用一個while迴圈進行對話,這樣一來也可以擁有追問的功能。

結語
以上,我們利用LangChain簡單實作出了ChatPDF的功能,讓我們能以聊天的形式,快速了解文件內容,以後就不用怕來不及看文件了啦,那這次先寫到這,我要去趕報告了: )
Reference
ChatPDF:https://www.chatpdf.com/
LangChain:https://python.langchain.com/en/latest/index.html
L'Oréal Paris annul report:https://www.loreal-finance.com/eng/annual-report
GPT-4 Tutorial: How to Chat With Multiple PDF Files:https://www.youtube.com/watch?v=Ix9WIZpArm0
(撰稿工程師:林芊)

