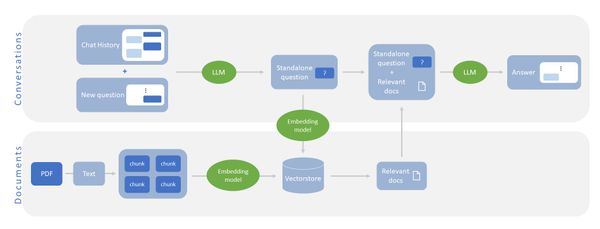
相信不少人已經知道 ChatGPT 這類的大型語言模型(LLM,Large Language Model),雖然對話能力強,卻也常亂接話。而RAG(Retrieval Augmented Generation)的做法便是讓 LLM 在回答問題時能夠參考相關文件,有效避免了因知識不足而產生的幻覺現象(hallucination),例如基金會與天下雜誌合作推出的「孫主任 AI 助教」,正是利用此技巧,讓 LLM 可以根據《孫主任的經濟筆記》這本書的內容,提供較正確、適當的回應。
當然,日常生活中除了文字,還包含了圖片、語音等不同類型的資訊內容。近期,LLM的發展也邁向多模態模型(multi-modal)的領域,使得模型能夠更全面地理解包括圖片在內的多種資訊。本文將分享如何將圖像整合到 RAG 中的實作方法,使應用場景能更加豐富。
如果你對 RAG 還不太熟悉的話,建議可以先參考上一篇文章《利用LangChain實作ChatPDF:問個問題,輕鬆找出文件重點》,這篇文章介紹了如何將RAG加入對話機器人中。
一、讀取PDF檔
首先,我們以《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》這篇論文的 PDF 檔案為例,利用 unstructured 套件中的 partition_pdf 工具,將PDF文章細分為「文字」、「表格」和「圖像」三種元素,後續依元素類型將有不同的處理方式。
import os
import uuid
import base64
from IPython import display
from unstructured.partition.pdf import partition_pdf
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.schema.messages import HumanMessage, SystemMessage
from langchain.schema.document import Document
from langchain.vectorstores import FAISS
from langchain.retrievers.multi_vector import MultiVectorRetriever
os.environ['OPENAI_API_KEY'] = "sk-*****"
output_path = "./images/Swin"
# Get elements
raw_pdf_elements = partition_pdf(
filename="./PDFs/Swin.pdf",
extract_images_in_pdf=True,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
extract_image_block_output_dir=output_path,
)二、將文字、表格及圖像轉換成文字摘要
得到「文字」、「表格」和「圖像」三種元素後,緊接著要思考如何將它們存到 Vectorstore 中。我們選擇將三種元素都轉換成文字摘要,再將文字摘要轉換成向量,以便進行後續搜索,這麼做的原因主要是因為文件檢索時,通常會使用文章的向量相似度進行搜尋。此外,在生成摘要的過程中,使用”gpt-3.5-turbo”模型處理文字和表格部分,並以”gpt-4-vision-preview”模型處理圖像部分。(如下圖所示)
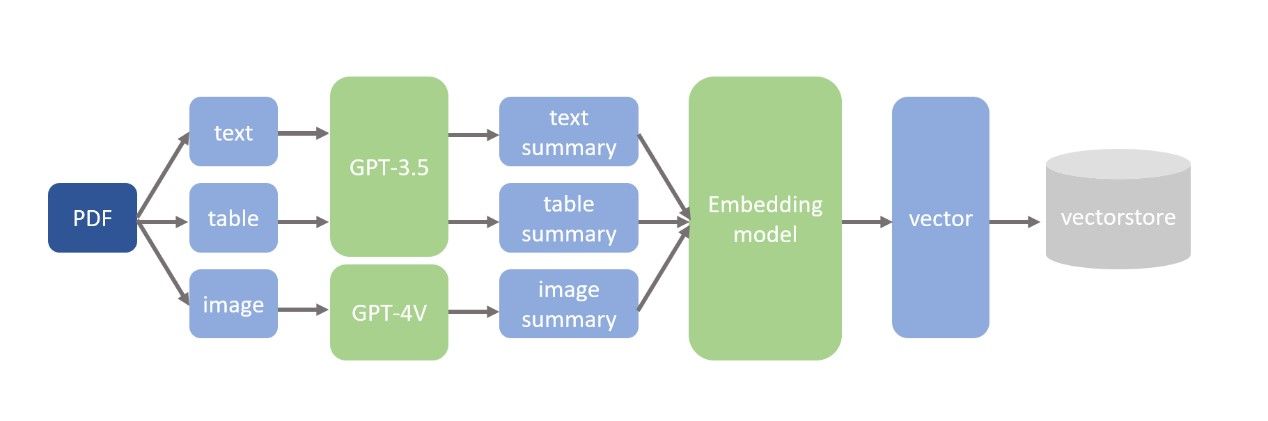
# Get text summaries and table summaries
text_elements = []
table_elements = []
text_summaries = []
table_summaries = []
summary_prompt = """
Summarize the following {element_type}:
{element}
"""
summary_chain = LLMChain(
llm=ChatOpenAI(model="gpt-3.5-turbo", max_tokens=1024),
prompt=PromptTemplate.from_template(summary_prompt)
)
for e in raw_pdf_elements:
if 'CompositeElement' in repr(e):
text_elements.append(e.text)
summary = summary_chain.run({'element_type': 'text', 'element': e})
text_summaries.append(summary)
elif 'Table' in repr(e):
table_elements.append(e.text)
summary = summary_chain.run({'element_type': 'table', 'element': e})
table_summaries.append(summary)
# Get image summaries
image_elements = []
image_summaries = []
def encode_image(image_path):
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode('utf-8')
def summarize_image(encoded_image):
prompt = [
SystemMessage(content="You are a bot that is good at analyzing images."),
HumanMessage(content=[
{
"type": "text",
"text": "Describe the contents of this image."
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encoded_image}"
},
},
])
]
response = ChatOpenAI(model="gpt-4-vision-preview", max_tokens=1024).invoke(prompt)
return response.content
for i in os.listdir(output_path):
if i.endswith(('.png', '.jpg', '.jpeg')):
image_path = os.path.join(output_path, i)
encoded_image = encode_image(image_path)
image_elements.append(encoded_image)
summary = summarize_image(encoded_image)
image_summaries.append(summary)以下是 LLM對表格資料及圖像資料做的摘要,明顯可看出無論是複雜的模型架構,或是缺乏文字解說的流程圖,LLM 都展現出具一定水準的理解能力。緊接著,就要利用這些摘要內容展開進一步搜尋。
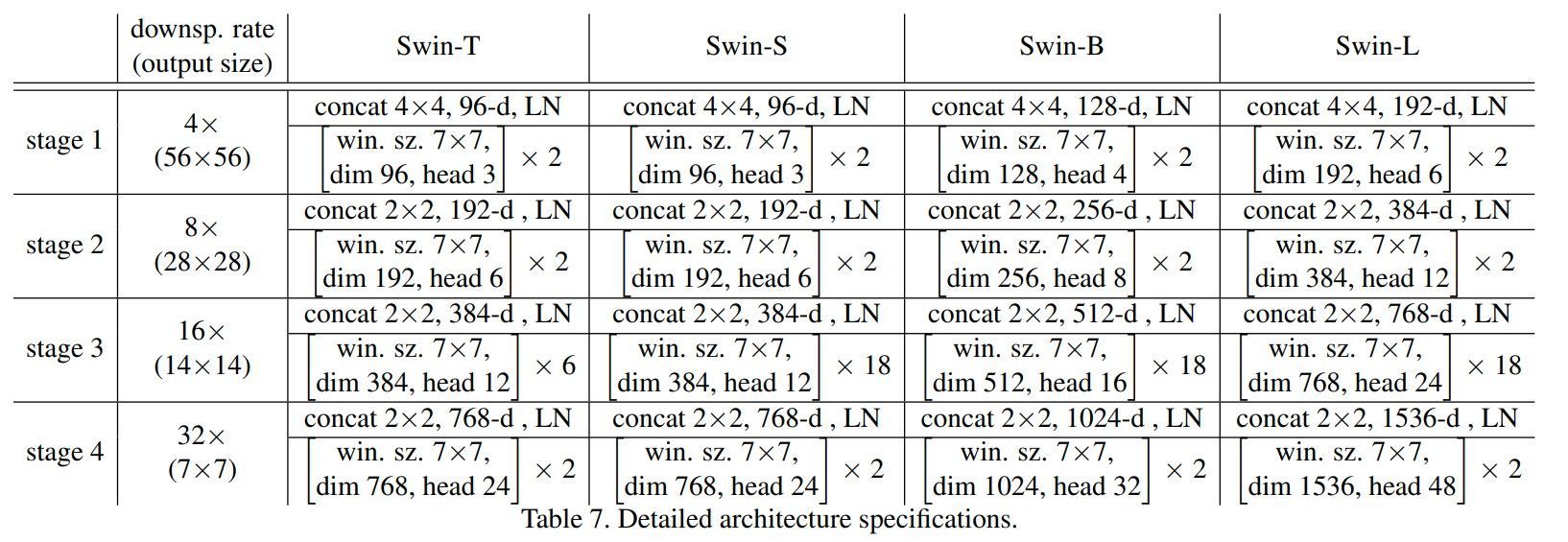

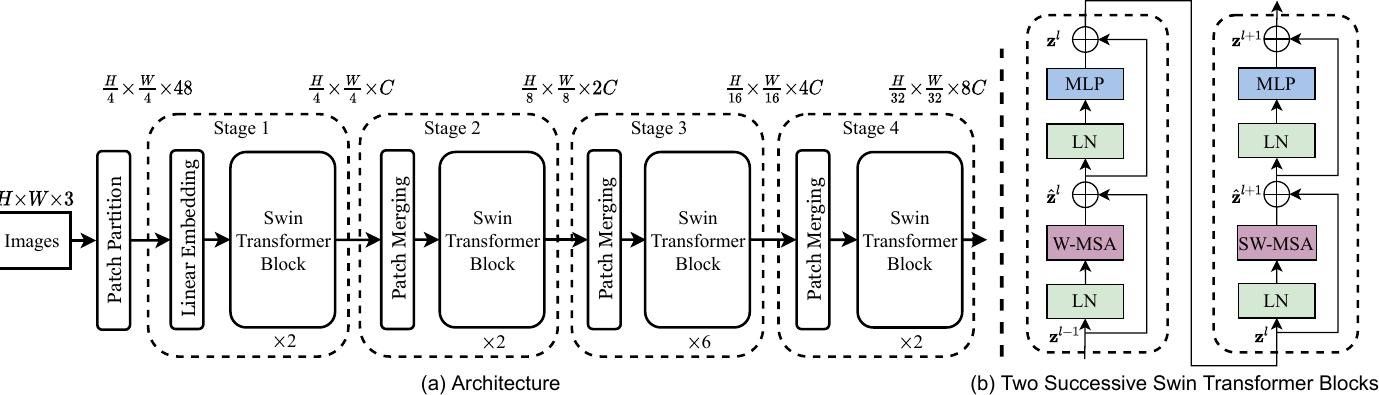

三、將文字摘要轉換成向量
接著,我們透過 Embedding 模型將摘要轉換成向量並儲存到向量資料庫(vectorstore)中。由於向量資料庫提供了強大的演算法,針對向量快速進行相似度搜尋,因此,我們將向量與原始資料連結在一起,以便可以只針對摘要進行檢索,並取出未經轉換的原始資料。
# Create Documents and Vectorstore
documents = []
retrieve_contents = []
for e, s in zip(text_elements, text_summaries):
i = str(uuid.uuid4())
doc = Document(
page_content = s,
metadata = {
'id': i,
'type': 'text',
'original_content': e
}
)
retrieve_contents.append((i, e))
documents.append(doc)
for e, s in zip(table_elements, table_summaries):
doc = Document(
page_content = s,
metadata = {
'id': i,
'type': 'table',
'original_content': e
}
)
retrieve_contents.append((i, e))
documents.append(doc)
for e, s in zip(image_elements, image_summaries):
doc = Document(
page_content = s,
metadata = {
'id': i,
'type': 'image',
'original_content': e
}
)
retrieve_contents.append((i, s))
documents.append(doc)
vectorstore = FAISS.from_documents(documents=documents, embedding=OpenAIEmbeddings())四、對向量進行搜索並回答問題
最後,當我們輸入一個問題時,模型可以先從向量庫中依據摘要取出最相關的n個內容,再將「文字與表格的原始資料」及「圖像的文字摘要」放入 LLM 中做為參考,這樣的回答模式,使 LLM 除了可以參考文章中的文字,也能從圖像與表格中得得更多資訊。以下程式碼便是模型對於問題「What is the difference between Swin Transformer and ViT?」的回答以及其所參考的圖像。
answer_template = """
Answer the question based only on the following context, which can include text, images and tables:
{context}
Question: {question}
"""
answer_chain = LLMChain(llm=ChatOpenAI(model="gpt-3.5-turbo", max_tokens=1024), prompt=PromptTemplate.from_template(answer_template))
def answer(question):
relevant_docs = vectorstore.similarity_search(question)
context = ""
relevant_images = []
for d in relevant_docs:
if d.metadata['type'] == 'text':
context += '[text]' + d.metadata['original_content']
elif d.metadata['type'] == 'table':
context += '[table]' + d.metadata['original_content']
elif d.metadata['type'] == 'image':
context += '[image]' + d.page_content
relevant_images.append(d.metadata['original_content'])
result = answer_chain.run({'context': context, 'question': question})
return result, relevant_images
結語
本文藉由一個簡單範例實作 LLM 應用領域中,使用多模態模型完成的 RAG 工具。首先將不同形式的文件內容轉換成文字摘要,再將文字摘要轉換成向量進行搜尋,使得模型在回答的過程中既參考文字內容、又能夠從圖像和表格中獲得更多資訊。從過去對單一模態的回答到現在,我們看到 LLM 技術不斷地演進,其應用甚至已擴展至多模態場景,使模型能更全面的理解文本中不同種類的資訊。假使讀者手邊有一些包含文字及圖像的多模態資料,不妨嘗試利用這個方法,實際試做看看。
(撰稿工程師:林芊)