
許多人以為蒐集完資料後,就可以直接進行模型訓練。事實上,在這之前,還有些工作需要進行,這也是本篇文章所要說明的事。
資料前處理的三個面向
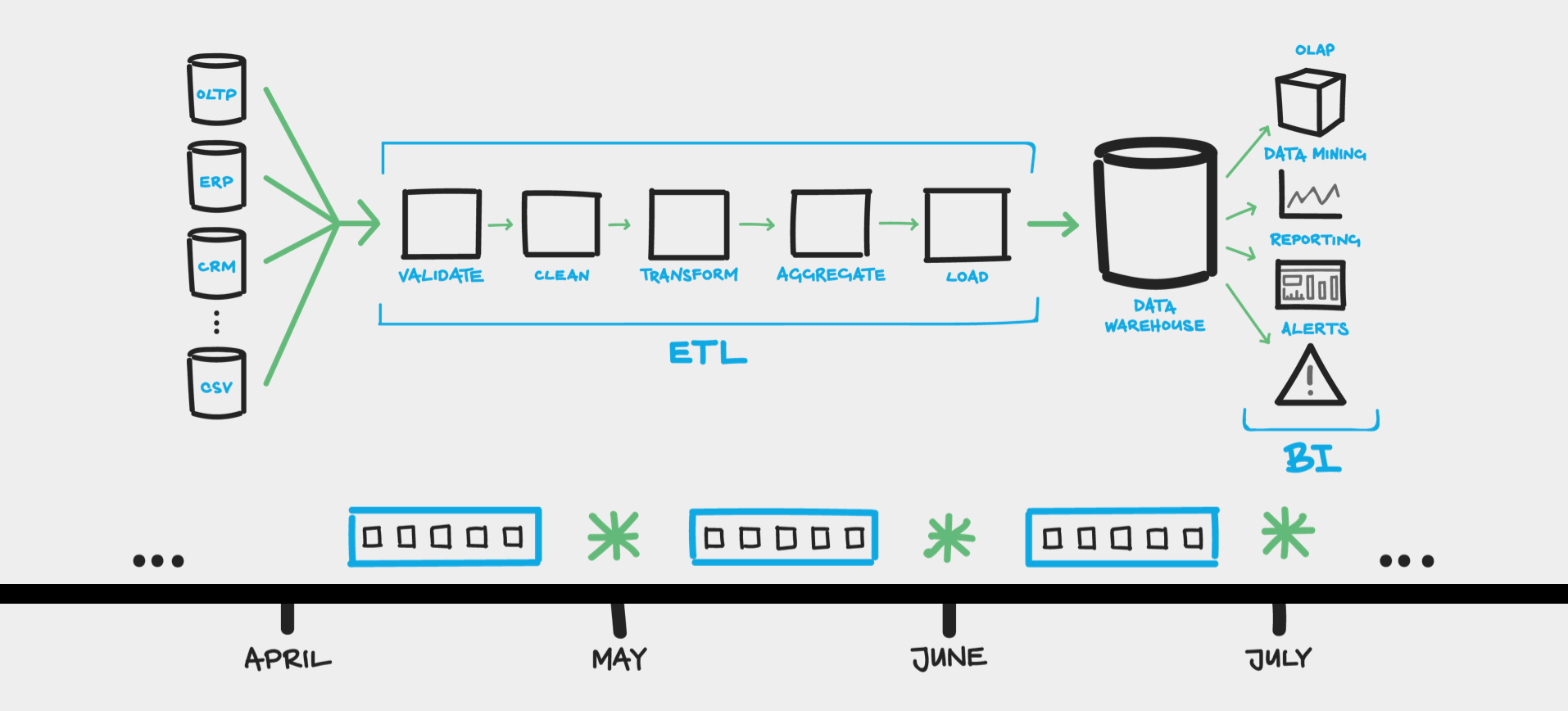
實務上在收集完資料之後,到真正進入模型之前還有一個重要的環節需要處理,稱為是「資料前處理(Data Preprocessing)」。收集到的資料是從使用者的角度下去規劃,不一定是最適合數學模型存取的樣子。在這個環節的主要工作就是將資料調整成適合模型的輸入,也有人把這個過程稱為 ETL (Extract-Transform-Load)。
ETL 用來描述將資料從來源端經過抽取(extract)、轉置(transform)、載入(load)至目的端的過程。ELT 這個字常用在 BI、 Data Pipeline、資料倉儲 領域上。Data Pipeline 是指利用程式自動化定期的資料處理過程,Data Pipeline 其實就是 MLOPs 前面那一段自動化過程。
資料前處理的另外一個工作,在真實的世界中資料往往沒有想像中的「乾淨可用」。在實務中,資料會有資料缺失(Incomplete/Missing data)、雜訊(Noise)、離異值(Outliner)等等的問題,這樣的資料會導致模型無法正常運算。資料前處理泛指的是在分析演算法之前,對資料進行處理跟調整,避免模型因為資料產生的瑕疵而誤判。
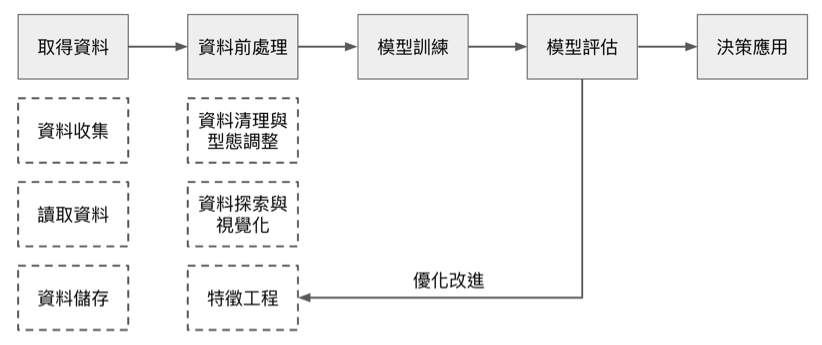
綜合上述幾個問題,我們可以把資料前處理分成三個面向:
- 資料清理與型態調整
- 資料探索與視覺化
- 特徵工程
資料清理:遺失值或錯誤資料處理
清理資料的目的是將原始資料中的「缺失值」或「錯誤值」轉成適合模型可以存取的資料。資料清理是資料前處理環節中必須的工作之一,如果有未清理的資料會導致模型無法順利運行。
那什麼是「適合模型的資料」呢?接著更進一步的定義「適合模型的資料」,我們稱為「模型可以學習(Learniable)」的資料,指的是能夠經由數學模型存取的資料格式,也就是數學上的「向量/矩陣」,在程式當中通常以「Vector/DataFrame」來存放。所以需要被處理的資料指的就是「無法透過數學運算的」,可以簡單分成幾種類型:
- 缺失值或不完整的資料 - Incomplete/Missing Value
- 錯誤或含有不合法字元(亂碼、特殊符號)- Noisy
- 資料型態不一致 - Inconsistent
缺失值(Missing Value)是指數據中有特定或者一個範圍的值是不完全的,可能是系統造成的,也可能是人為缺失。依照原因可以分為完全隨機缺失值(missing completely at random)、隨機缺失值(missing at random)、非隨機遺漏(not missing at random)。
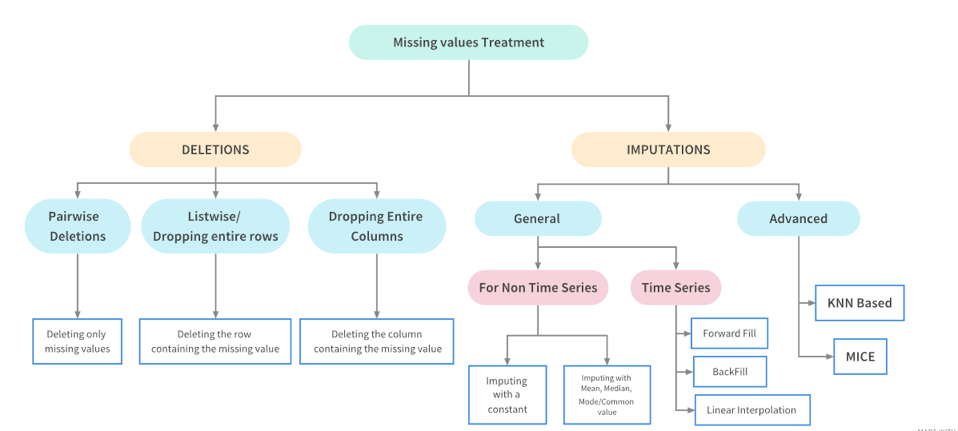
面對 Missing Value 的處理策略主要可以分成「刪除」或「填補」兩種策略,可以細分為以下手法:
- 直接刪除含有缺失值的資料或欄位
- 人工填補遺失值
- 常數(0/-1)或通用值(unknown)填補遺失值
- 類似資料/全部資料的統計值填補遺失值
- 利用統計方法進行補值(內差/回歸)
- 利用機器學習方法進行補值(預測)
在 Kaggle 平台上,也有人分享更多的操作手法:
資料型態不一致該怎麼辦?
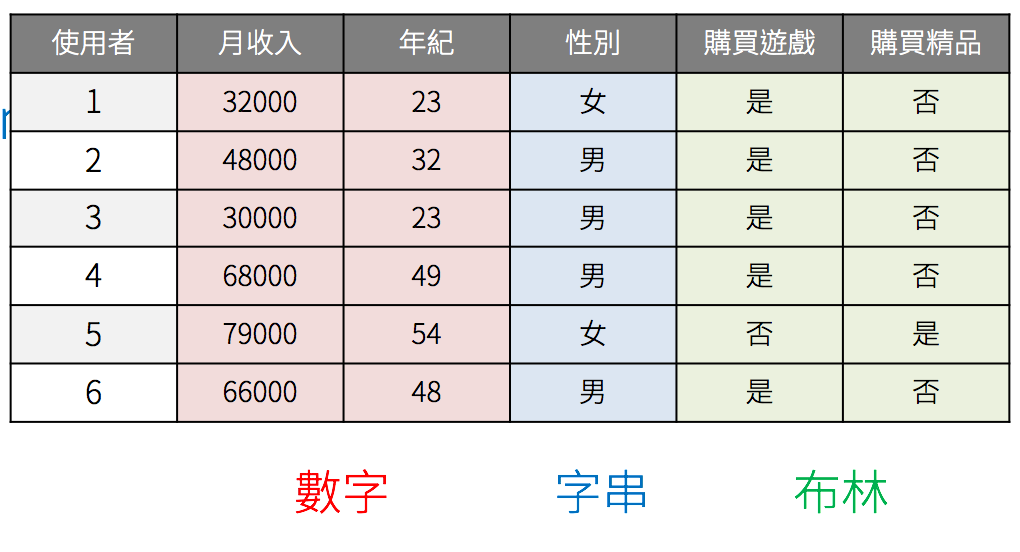
需要被處理的資料是指無法透過數學運算的資料,也就是空值和字串兩種。空值的部分我們在資料清理的階段處理,接下來來處理字串的資料。我們可以將資料分成「數字」、「字串」和「布林」三種類型。
針對資料的特性再近一步細分:
- 類別型 (categorical)
- 有序的
- 無序的
- 數值型(numerical)
- 連續的
- 離散的
- 其他(非結構型資料)
- 時序型
- 文本型
- 影像型
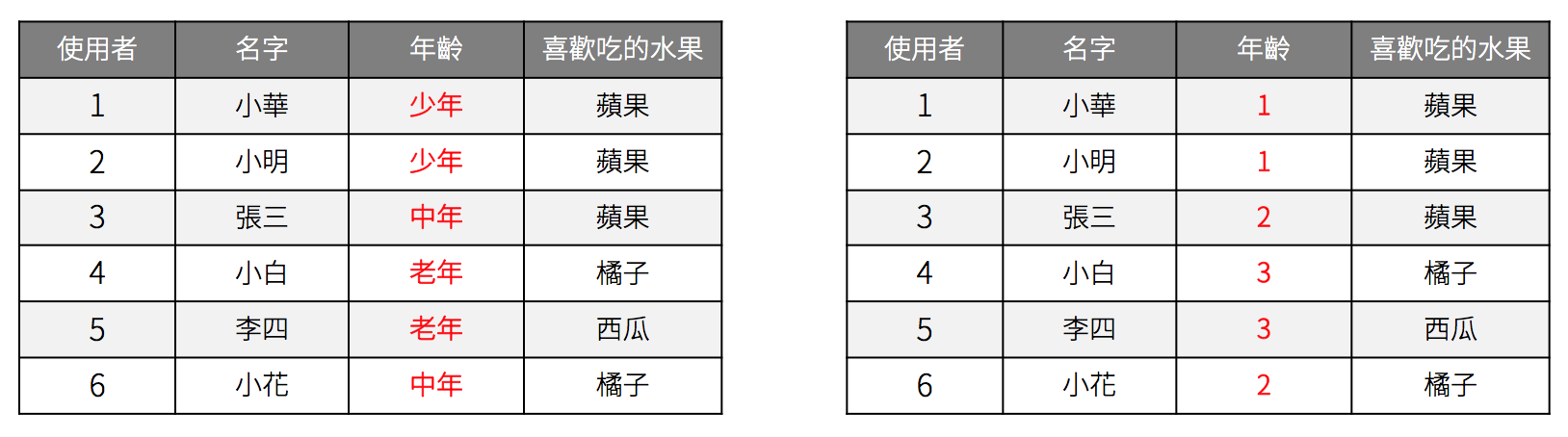
假如現在的資料有幾個欄位,分別包含不同的類別資料,當中的「年齡」跟「喜歡吃的水果」都是採用字串的方式定義。字串是模型無法存取的型態,需要想辦法轉成數值才可以。
Label Encoding
根據觀察資料,可以把字串的資料分成有序和無序的。最直覺的方法就是直接將「字串」轉換成一個對應的數字即可,這種方法我們稱為標籤編碼法(Label Encoding)。有序類別字串可以直接採用標籤編碼法,利用轉換後的大小關係維持資料間的順序。標籤編碼轉換後的大小會隱含資料間的順序關係。
One-Hot Encoding / Dummy Variable
但原本的資料如果是無序的類別字串直接使用標籤編碼法會有點問題,以這個例子來說,會讓原本應該無序的水果間產隱含大小的關係出現。而我們在模型當中,很常會使用「大小」來表示資料間的關係。
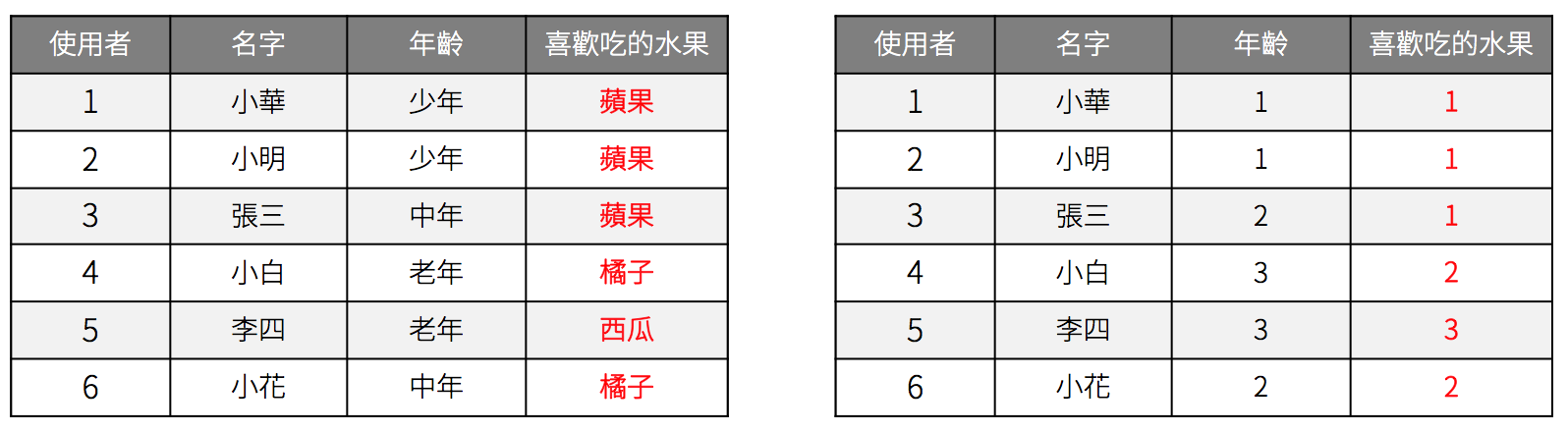
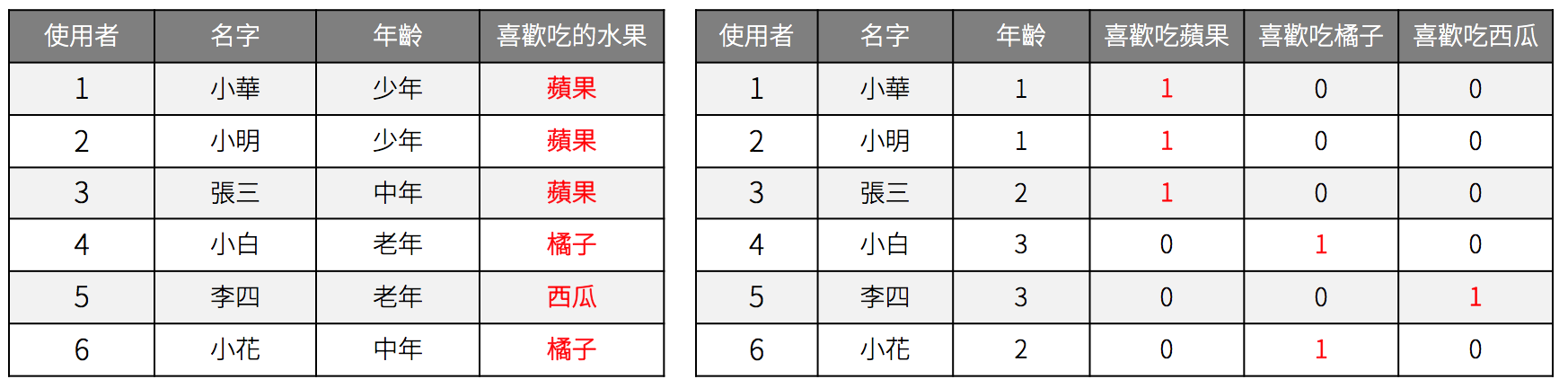
因此,無序類別字串轉數值會採用另一種方法,稱為是獨熱編碼(One-Hot Encoding)或虛擬變量(Dummy Variable)的方法。這種方式會將原本欄位的資料轉換鍋的欄位,藉此來維持資料就的無序關係。
資料前處理中必須要做的處理
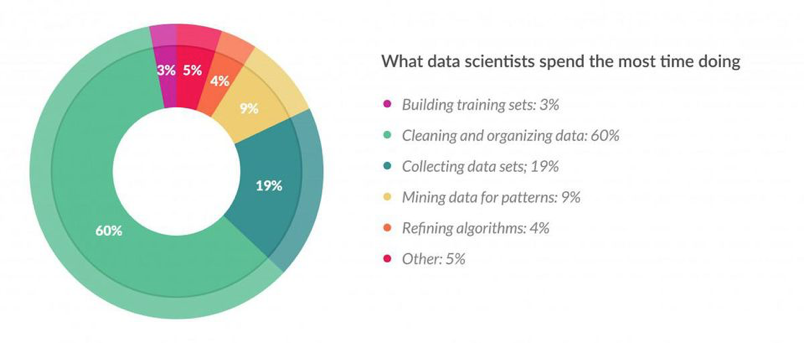
我自己會把「資料清理」跟「型態調整」稱為是整個分析過程中一定要操作的部分,因為若沒有經由正確的處理方法會造成模型無法存取的狀況。另外根據CrowdFlower Survey Results調查的結果,在資料分析的階段 60% 的時間其實是在進行資料清理的。
最後,你以為你是在做的是資料分析的工作,實際上其實是個資料黑手。
原文刊登於: 資料科學家的工作日常(原文:資料前處理必須要做的事 - 資料清理與型態調整)




