在數據分析的領域中,我們常使用到的工具包含SQL、SPSS、Python等程式語言,而接下來的整個系列裡,數據領航員會以Python的角度帶大家切入主題作探討。
Python是個非常易理解與學習的語言(不過本主題不會做太多的介紹…),其中很大的一個優點是有非常多的第三方套件,可幫助開發者提升專案開發效率(可參考:https://pypi.org/)。
至於在資料科學的專案中,我們時常使用到的套件模組是Seaborn、Pandas、Matplotlib等,往後的文章中也會陸續再向讀者做介紹,本篇文章會將重點鎖定於Numpy!使用到的程式碼也會放在Github上,歡迎取用~
介紹NumPy
NumPy(Numerical Python),是高性能計算和資料分析的基本套件,包含6大特色:提供高效能的N維度陣列運算、具備全面的數學運算功能、許多的硬體和運算平台皆可搭配使用、入門門檻低且操作直觀、可與其他程式語言做整合(EX:C、C++等)、為Open Source可公開開發和維護的。(可參考:https://numpy.org/)
證明NumPy具有高效能?
以下段落帶大家了解list及ndarray的資料型態差別。
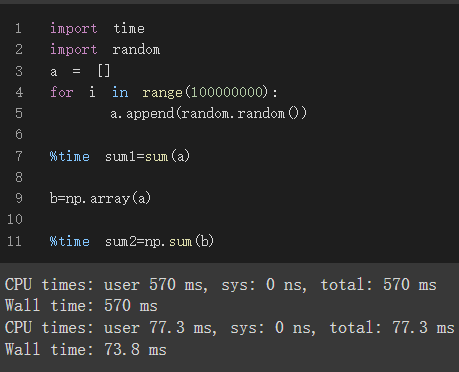
首先,是運算效能上的差異。上方的程式碼圖片是將list(a)資料型態及ndarray(b)的資料型態同做相同的運算(先創建資料長度為100000000的list及ndarray,並各自將資料內容加總),可發現list的運算效率遠為ndarray的將近八倍,list所花費的時間約為570ms,而ndarray只花了約為74ms的時間。
機器學習或是深度學習最大的特點就是會進行複雜且大量的運算,因此不論資料的大小及維度,ndarray都可以為我們省去許多不必要的等待時間或是機器上的效能問題。
另外,ndarray 除了運算效能比 list 快上很多之外,其實是有一個限制的,而這也是 list 的優勢。就是儲存在同一個 ndarray 裡的資料都要是同樣的資料型別。反之,list則不需要。
語法說明
安裝套件

引入套件

查看資訊
參考自 http://taewan.kim/post/numpy_cheat_sheet/

建立陣列

以下圖表為ndarray所支持的所有資料型態整理表。

參考自https://medium.com/python4u/hello-numpy-b5ebe67a1ada
陣列的索引、維度轉換及排序

陣列的合併

運算及統計

💡因 np.dot() 的用法筆者認為較為特殊,特別拉出來和大家做介紹~
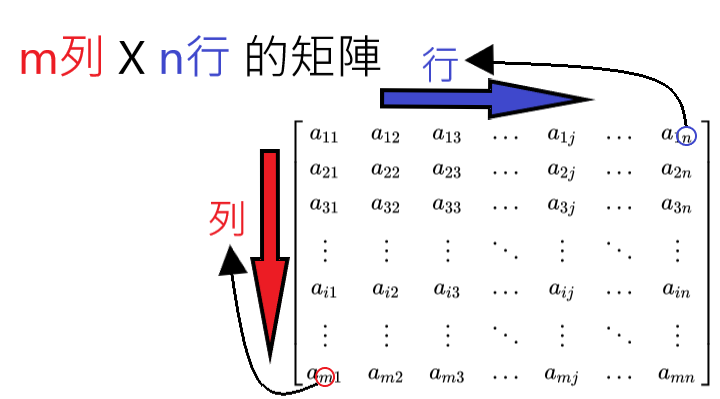
矩陣運算方式
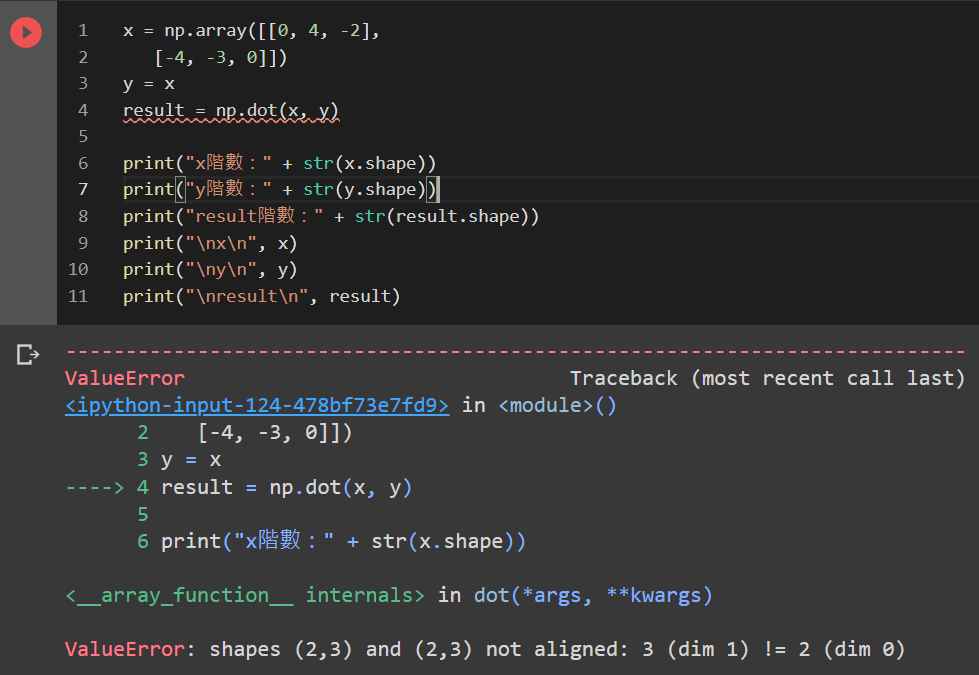
若兩矩陣(x, y)需進行內積運算,x為m×n階矩陣,y就必須為n×p階矩陣,算出的結果則會為m×p階矩陣,不符合此規定的話則無法運算。
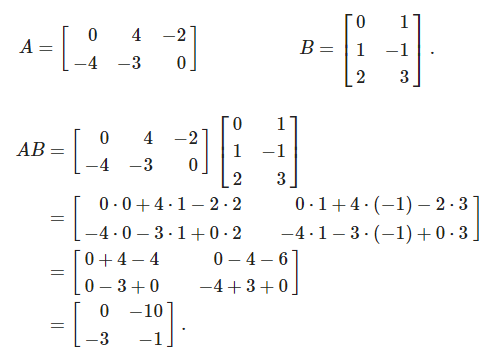
參考自https://mathinsight.org/matrix_vector_multiplication
如上圖所示,A矩陣為2×3階矩陣,B為3×2階矩陣,因此算出的結果為2×2階矩陣。
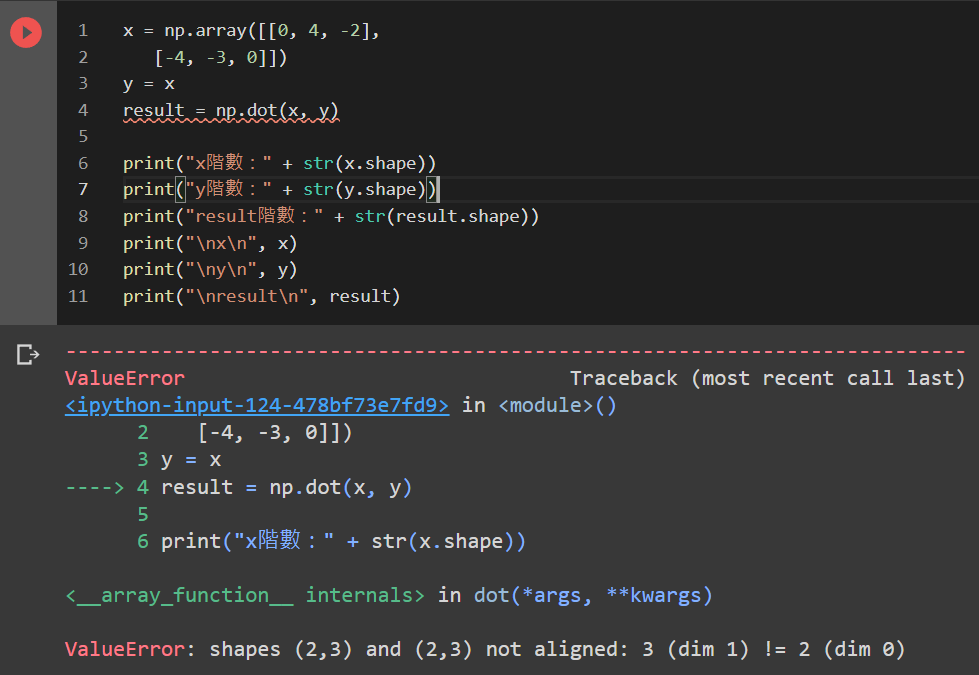
上圖的程式碼中,x與y矩陣同樣都為2×3階矩陣,因此不符合規定,無法做運算則報錯。
特殊情況
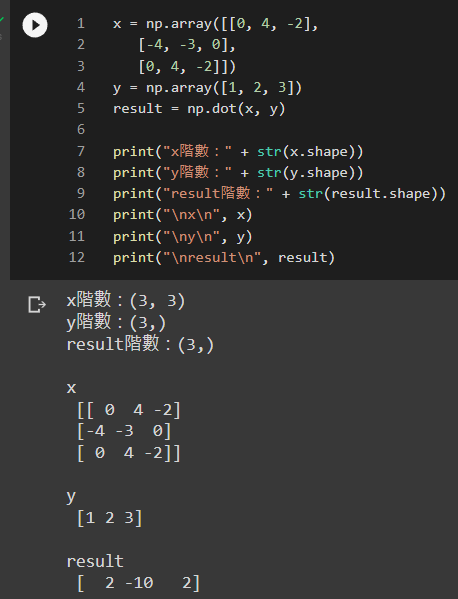
array([1, 2, 3]) 看似是1×3階的矩陣,但其實他的shape卻是(3, ) 。
因此若x矩陣為3×3階矩陣,y為3×?階矩陣,是可以做運算的。
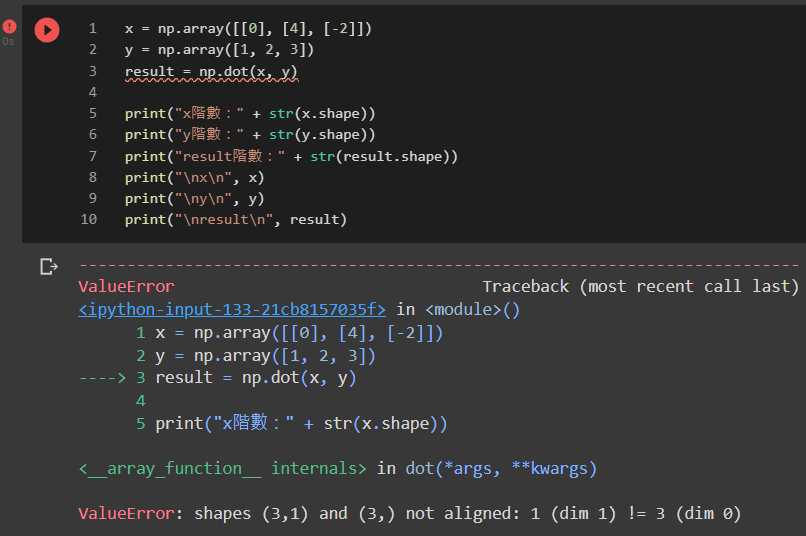
反之,若x矩陣為3×1階矩陣,y為3×?階矩陣,也一樣會報錯無法做運算。
根據上述所論,若讀者想要的shape是1×3矩陣的話,比較安全的打法會是
array([[1, 2, 3]])

不過,若將上述的情況顛倒過來,np.dot()又會自動先轉置後再做運算。例如:x為3×?階矩陣,y矩陣為3×1階矩陣。直觀想法應該要報錯,但np.dot()先將x矩陣轉換了,可以想像成x是?×3階而y仍然是3×1階,因此還是可以做運算。
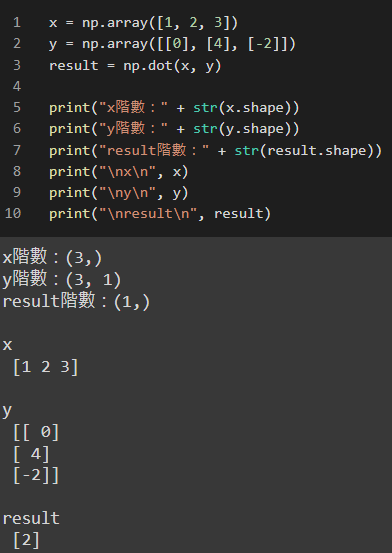
以上為np.dot() 中較容易搞混的內容,透過補充的方式帶大家釐清。
總結
NumPy是非常強大的Python套件,也具有非常多的功能,筆者在此只是簡單的敘述幾個基本且較常用的功能,還是希望可以幫助到大家~
參考資料

本文授權轉載自數據領航員 / 原文刊登於:數據分析基本工具-NumPy




