不論是資料分析或是建模,往往需要針對資料進行諸多處理,在 python 中最常使用的工具非 Pandas 莫屬。相較資料庫更方便,不需要處理完後再導入;跟 Excel 比起來效能更好、更靈活多元。本篇將以 Kaggle 提供的 QS World University Rankings 2017–2022 資料集做技巧展示,就一起來看看 Pandas 中有哪些必會與實用的功能吧!
1. 建立 DataFrame
在開始之前,先將 Pandas 套件安裝並且匯入。
1.1 使用 dictionary 建立
dictionary 中的每一個 key 值皆變成欄位,value 值在該欄位下依序寫入。

1.2 載入資料
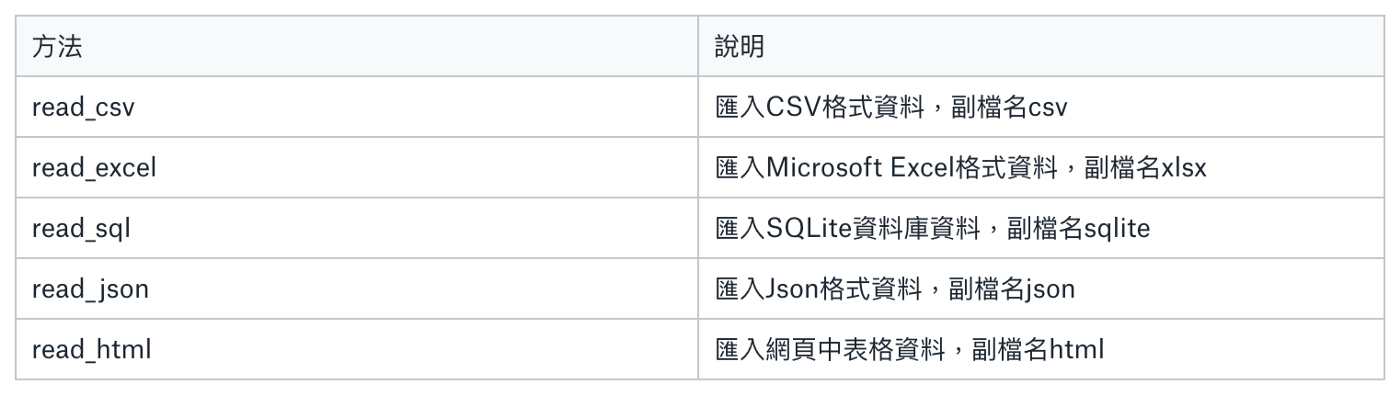
pandas 提供方法讀取各式資料:
載入示範的 qs-world-university-rankings-2017-to-2022-V2.csv 的 CSV 檔。
資料來源:https://www.kaggle.com/datasets/padhmam/qs-world-university-rankings-2017-2022


進階補充:遇到非常巨大的檔案,記憶體超載無法負荷時,可以透過 chunksize 參數來限制一次讀入的列數(rows)。本資料集未發生此狀況,這邊不多做介紹,有興趣的可以自己搜尋看看囉~
2. DataFrame 顯示 & 資訊
2.1 顯示部分 DataFrame
當我們想要查看資料樣貌,同時保持頁面整潔時:


進階補充:某些特殊情況下,我們想要展開整個 DataFrame 可以使用 pd.set_option(“display.max_columns”, None) 來達成~
2.2 DataFrame 的基本訊息
當我們拿到一份新資料,通常會使用 info() 來快速瀏覽這份資料的狀況,其中包含欄位數量、缺失值狀況、資料型態等資訊。


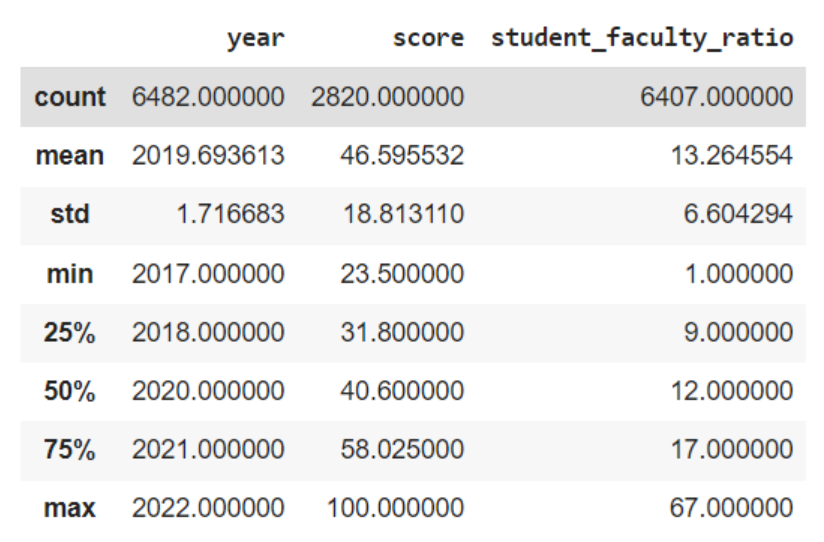
2.3 DataFrame 的基本統計
當我們想快速了解數值型變數的分布時,pandas 是有內建方法來計算基本的統計量的,不需要自己寫函式!

3. 取得想要關注的數據
不同分析需求,我們需要篩選出部分 DataFrame 資料,本節將展示幾個常用的技巧。
3.1 基本數據切割
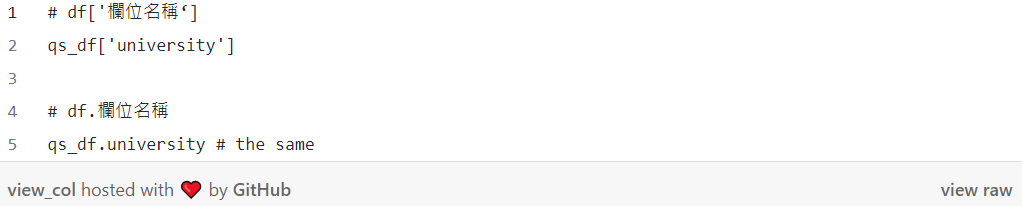
● 選取欄位
使用中括號或是物件選取方法取出目標欄位,返回一個 Series:

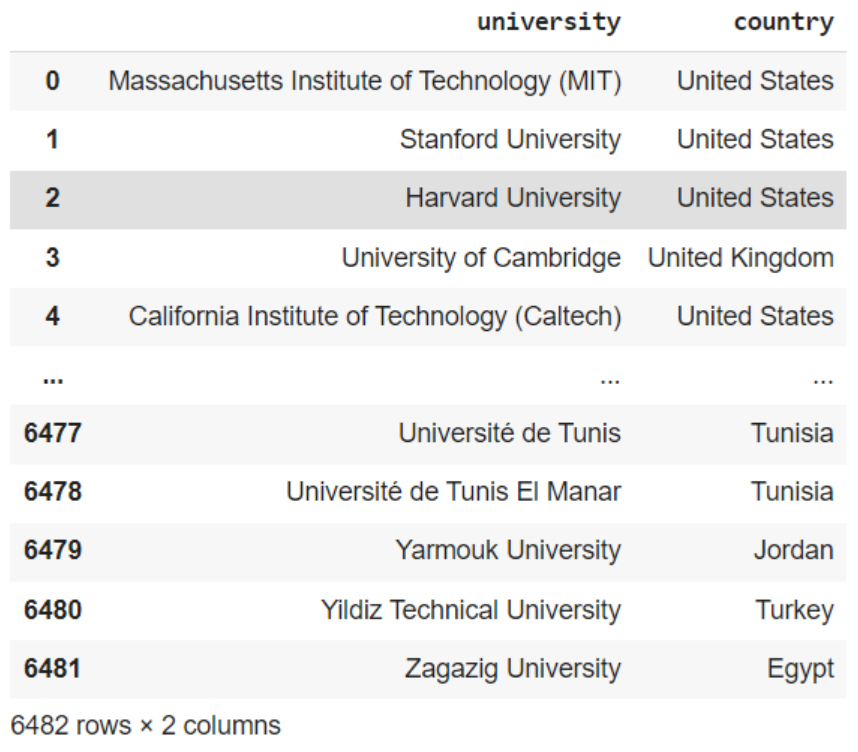
● 選取部分 DataFrame
使用兩層中括號選取複數欄位,返回一個 DataFrame:

進階補充:loc 與 iloc,基於行標籤和列標籤(x_label、y_label)進行索引,輕鬆定位 DataFrame 取出 item、row、column、part of DataFrame 的方法。
loc:pandas.DataFrame.loc — pandas 1.4.2 documentation (pydata.org)
iloc:pandas.DataFrame.iloc — pandas 1.4.2 documentation (pydata.org)
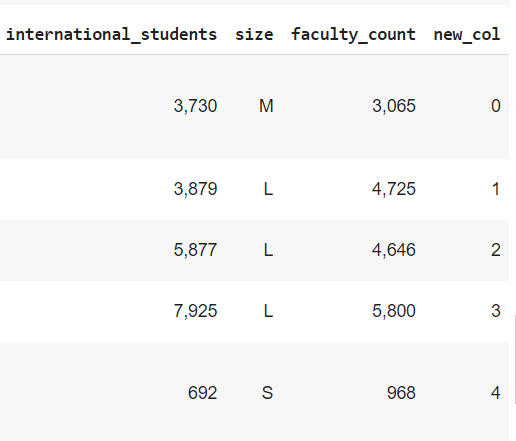
● 新增欄位
新增欄位時通常填入一個 list(注意長度需等於 DataFrame 列數),也可以為固定值等,方法如下:

進階補充:也可以透過 df.loc 函式指派:
— df.loc[rows, ’new_col_name'] = value
loc:pandas.DataFrame.loc — pandas 1.4.2 documentation (pydata.org)
● 刪除欄位
當我們想要移除用不到的欄位時,方法如下:
— df.drop(columns=[col_names_you_want_to_drop])
原有的 columns:



3.2 條件選取數據
pandas 中最實用的條件選取方式非 mask 莫屬,有點類似 excel 的篩選器,但更方便、更強大。用法如下:
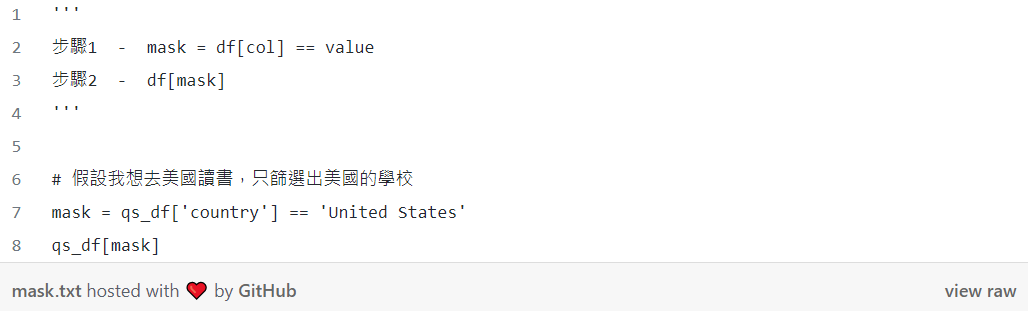
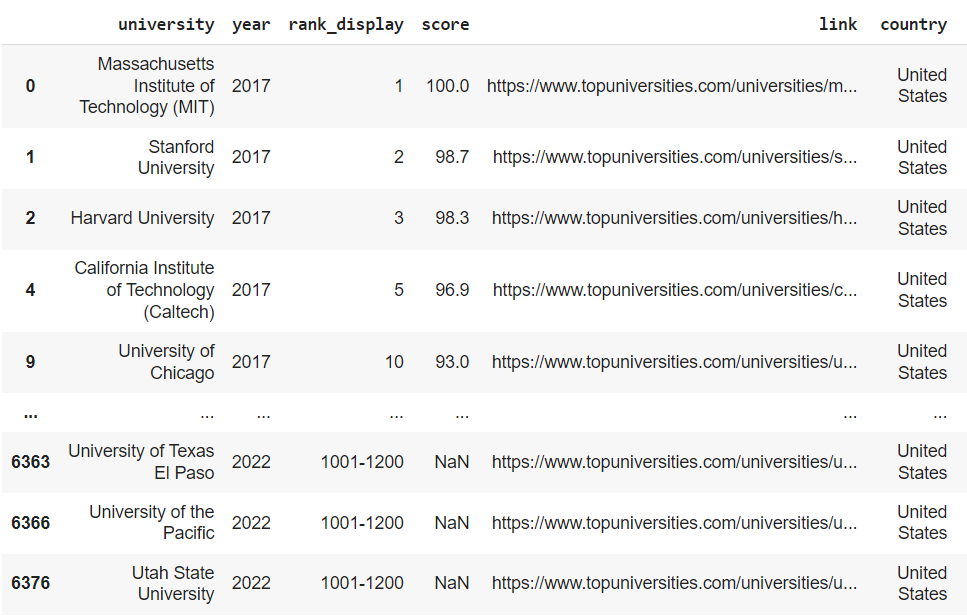
4. 基本數據處理與轉換
我們通常還會針對這些資料進行轉換、處理,本節將提供幾個常用的技巧。
4.1 空值處理
當我們發現資料缺失時,可以針對缺失值進行填補:
— df[col].fillna(fill_value)
目前 international_students 欄位缺失值總數為 164 人:



在填補欄位有非常大的學問,必須確定當前分析的情境下,將所有空值填補為該值是合理的。
4.2 重複值處理
當我們發現 DataFrame 中有重複值發生,想要移除時:
— df.drop_duplicates()
目前最後兩筆紀錄是一模一樣的:
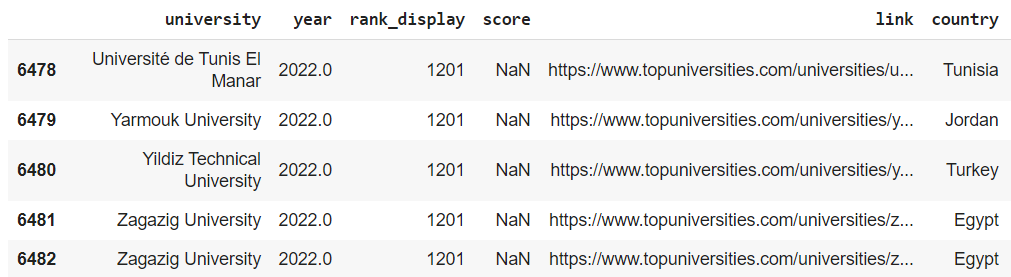

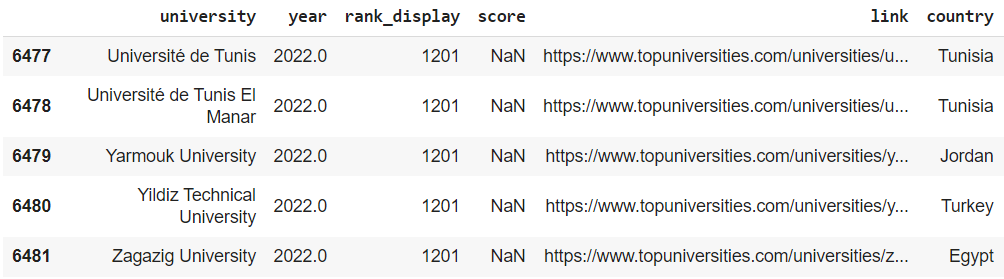
進階補充:drop_duplicates() 方法有 subset 參數可以調整,也可以選擇部分欄位一樣即捨棄呦~
4.3 欄位資料類別轉換
資料型態在分析時也是非常重要的,一旦格式錯誤,結果可能也錯了。因此當我們需要修改欄位型態時,可以使用:
— df['col_name'].dtype欄位資料型態
— df['col_name'].astype(new_type) 變更資料型態
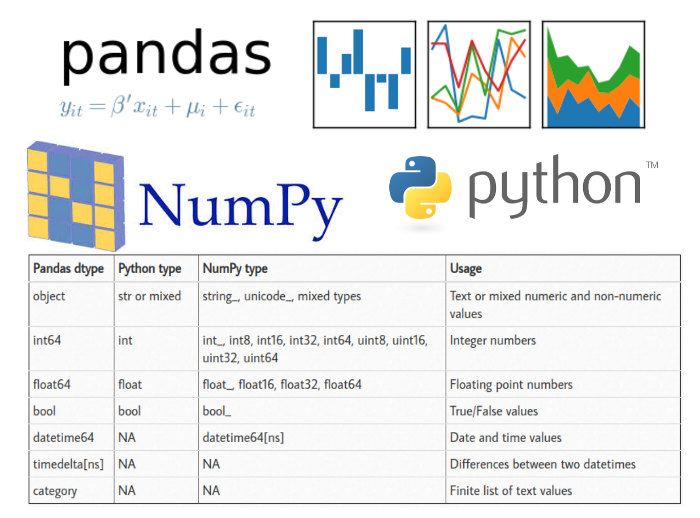
Pandas & Python 的資料型態對照:


4.4 針對整個欄位的每個值做轉換 or 計算
當我們想針對欄位中的每個值做一些更複雜的運算:
— apply() & def()
— apply() & lambda
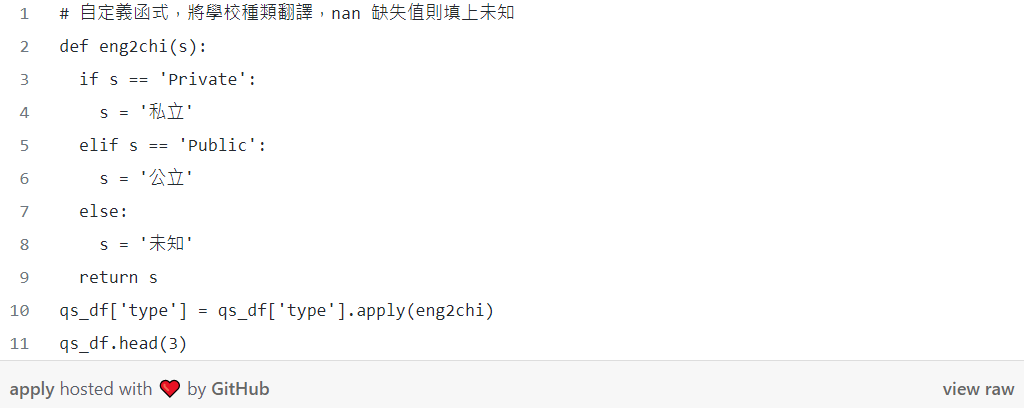
● apply() & def()
自訂義函式決定要對每個值做的操作,選取欄位後使用 apply 來套用:

● apply() & lambda
當只需要套用一次運算,可以選擇用 lambda 函式,就不用額外寫 def() 函式了!lambda 函式由 lambda 關鍵字、parameter_list(參數清單)、expression(運算式) 所構成:lambda parameter_list: expression。

進階補充:也可以使用 mask 來修改,與前面遮罩概念不一樣,是 pandas 提供的 pandas.Series.mask 方法。
4.5 連續數值型資料依照區間切分成類別資料
根據分析需求,有時我們會希望將數值型資料切成數等分,轉化為類別型資料進行分析:
— pd.cut(x=df['col_name'], bins=group_num, labels=labels)
pandas 提供的 cut() 函數可以輕鬆地將數值型資料切成數等分,bins 設置欲分組的組數,labels 為各組的標籤:

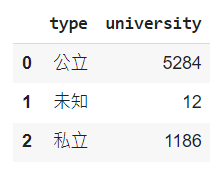
4.6 相同條件的資料群組化
有時我們也會需要將不同特徵的資料進行分組,可以運用:
— df.groupby([by_col]).count()[[col]].reset_index()

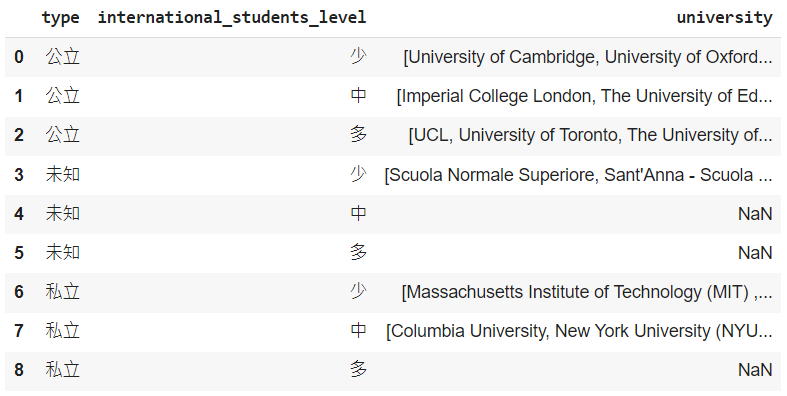
進階補充:結合 apply 方法依照條件將欄位值整合成一個清單:
5. DataFrame 的合併
當我們要把兩張 DataFrame 合併在一起時,有兩種常用的方法:
— pd.concat()
— df.merge()
5.1 pd.concat()
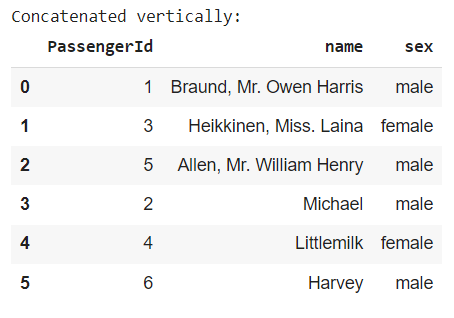
類似 NumPy 套件中的 np.concatenate(),利用 axis 參數可指定垂直或水平方向地合併兩個資料框,預設 axis=0 為垂直合併:
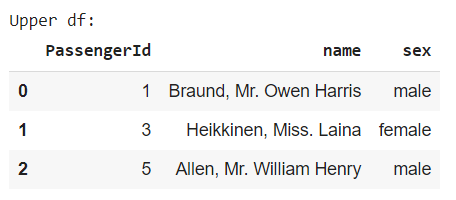
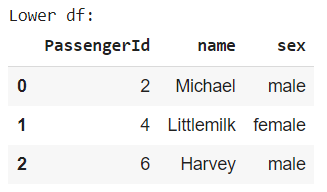
垂直合併時,會將相同欄位名稱的資料整合在一起
5.2 df.merge()
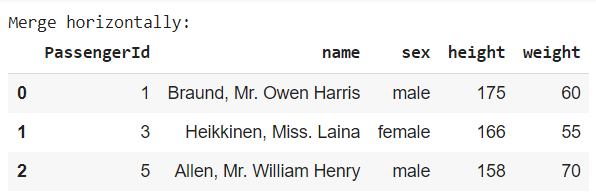
大多用於水平整合資料表,簡單示範一對一連結的合併:

透過 on 參數指定合併的依據(通常會選擇 id 唯一值欄位)

merge 方法還有其他參數可以調整不同的合併方式,如: inner join, right join, left join, outer join,有興趣的人可以到 pandas 官網看看囉!
merge: pandas.merge — pandas 1.4.2 documentation (pydata.org)
Pandas 的介紹就到這裡囉,本文挑選出的多是較常使用的技巧與方法,事實上還有非常多內容是還未提及的。值得開心的是你已經知道基礎的用法了,這類的工具套件只要多多練習、培養肌肉記憶,在練習的途中也會發現更多好用的方法。如果真的遇到難以解決的問題,Pandas 也提供了非常完整的 document 可以參考哦!
本文授權轉載自數據領航員 / 原文刊登於:數據分析基本工具-Pandas 實戰




