深度學習的任務總類非常多,但是依據資料類型分成以下幾種:如果是影像相關的資料,我們會使用基於CNN的模型;而序列型的資料,則會使用LSTM或Transformer;至於剩下的問題,通常會使用一般的NN。
什麼是圖神經網路(Graph Neural Networks)?
大部分的深度學習任務,都可以分成上述三種,但是,這次我們要介紹的是一種特別的任務類型,也就是處理圖(graph)類型的資料。這裡的圖類型資料並不是「圖片」類型,而是由節點(Node),與邊(Edge)組合而成的關係圖。
例如,下圖可能就是圖類型的資料會處理到的任務:
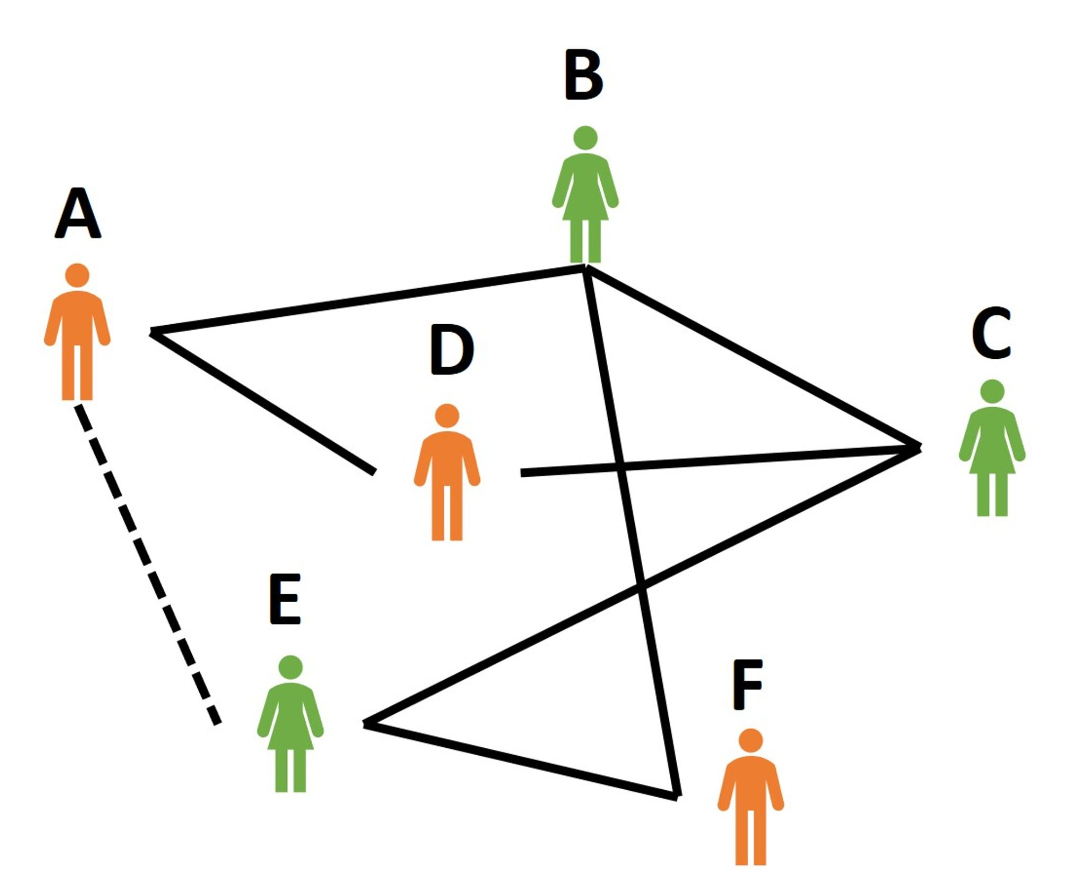
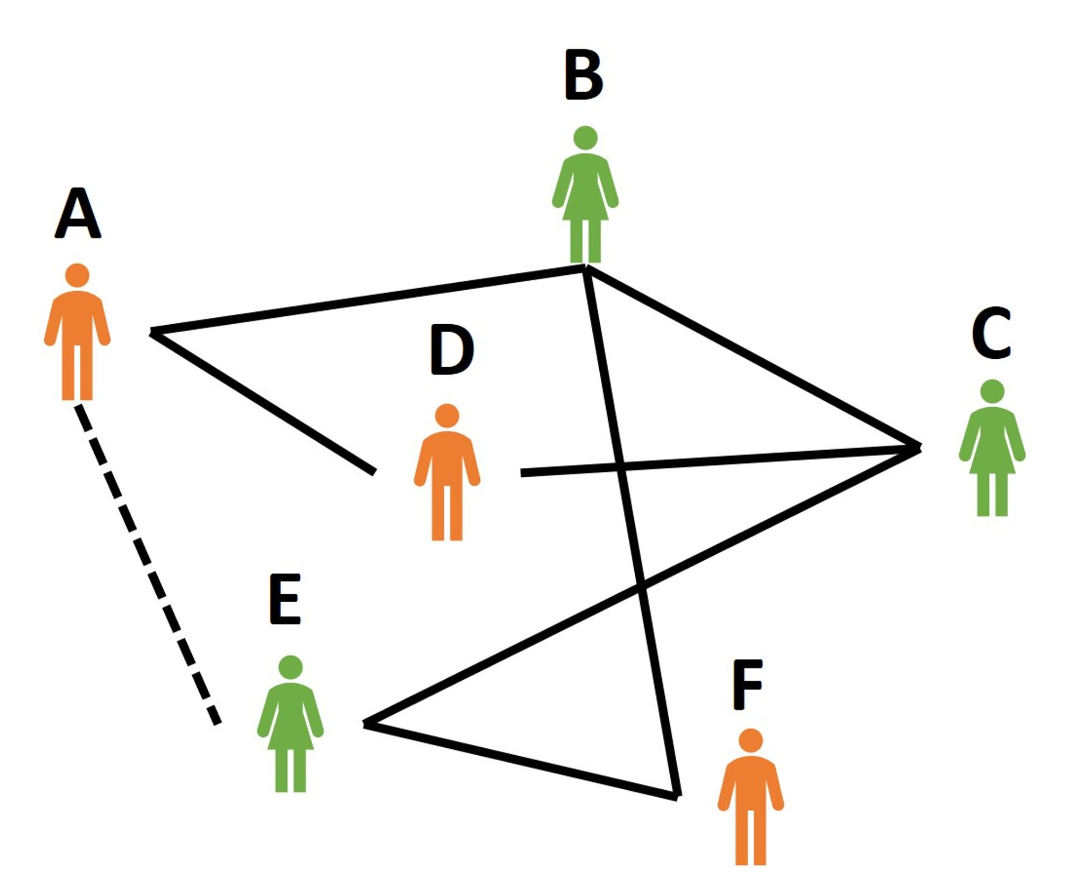
這張圖是一張人際關係網路,圖中的人就是所謂的節點,而人與人間的線就是邊,其中,實線表示被連線的雙方是已知的朋友關係,而虛線就是我們的預測目標。我們希望模型能透過學習已知的人際關係,來推論出A跟E是否是朋友關係。也就是預測節點A跟節點E之間是否存在連線?
在資料的分類上,圖被歸類為非結構化資料,也就是指資料形式自由,且不遵循標準格式規範的資料。而圖的資料類型在傳統的深度學習模型上非常難處理,主要原因是圖的拓撲結構很複雜,且大小不固定。
為了處理像圖這樣的非結構化資料,許多新的神經網路模型被設計出來。最早可以追朔到GCN,其靈感來自於CNN,但與CNN不同的是,該模型可以被泛化到任意結構的圖上。而在GCN之後,各式各樣的圖神經網路被提出來,其中包括下列實作中會使用的GAT。GAT的靈感來自於attention,與GCN不同的地方在於,GAT可以考量到圖中邊上的特徵資訊,而GCN只能考量到節點上的特徵資訊。
下面就透過一個簡單的實作例子快速上手GNN!
資料與前處理
先介紹這次實作用的資料集: soc-sign-epinions
該資料集來自購物網站Epinions,網站上紀錄了用戶間的信任評級。當用戶購物時,會依據用戶對其他的評級,決定哪些用戶的評論會被顯示出來,類似的評級系統還可以在Youtube或Steam上看到。
我們的目標是基於已知的評級去預測未知的評級,例如當我們知道,用戶1跟用戶2都信任用戶3,而用戶4則信任用戶1和用戶2,雖然我們沒有用戶4對用戶3的評級資料,但我們可以猜測用戶4,極有可能信任用戶3。
下載資料集後,可以在資料集所在的資料夾中透過下面指令解壓:
gunzip soc-sign-epinions.txt.gz
打開解壓後的txt檔,可以看到前4行是資料的一些簡單說明,從第5行開始就是資料本體了。
每一行表示每則信任評級是由誰打給誰的,且可看出是信任還是不信任,分別用1跟-1表示。所以可以把這樣的人際關係網路看成是一張圖,節點就是用戶,邊就表示單向的信任或不信任關係。如下圖:
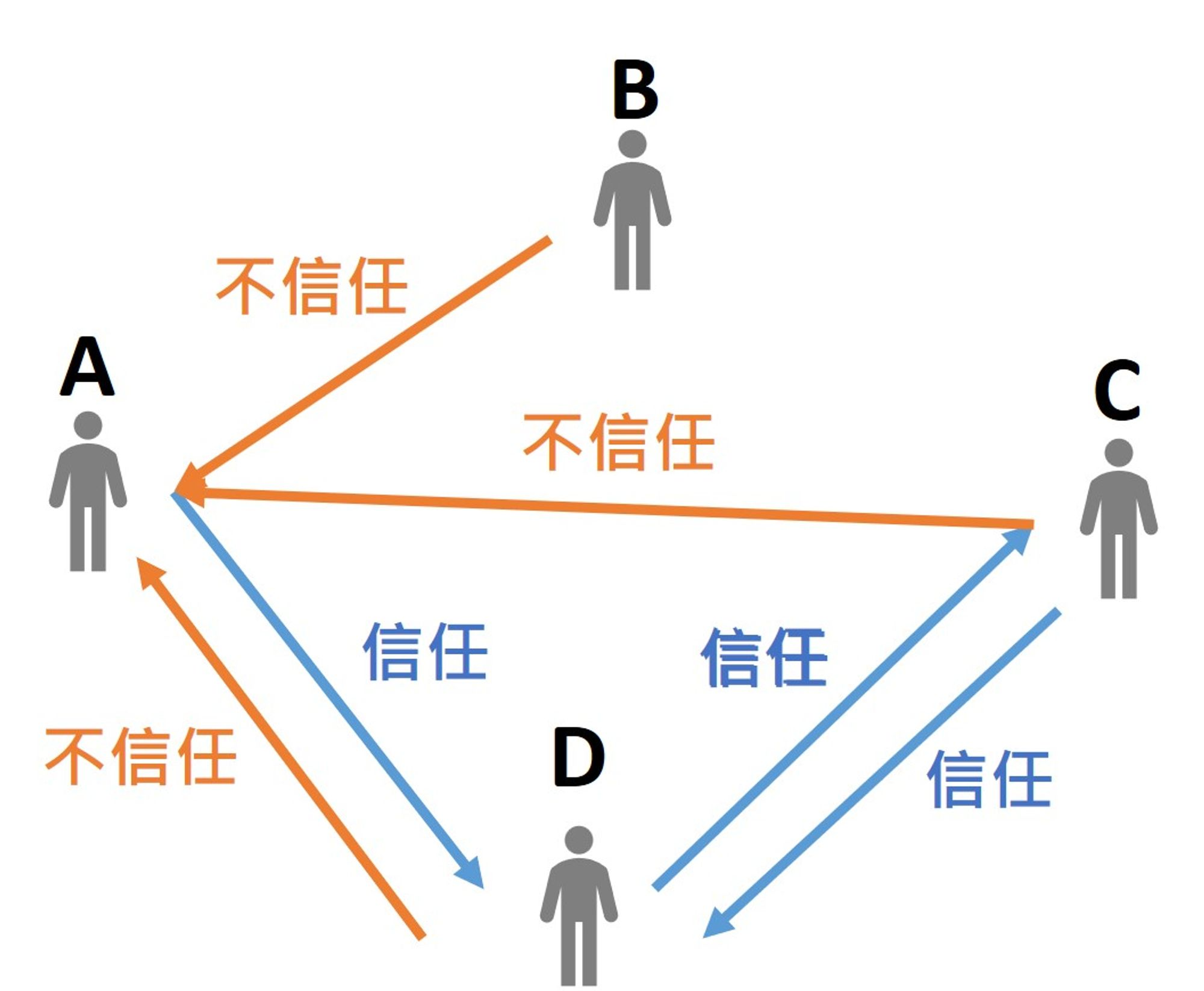
每則信任評級的第一筆資料為打分的用戶編號(FromNodeId),第二筆資料則是被打分的用戶編號(ToNodeId),第三筆為打分(Sign)。
所以我們可以讀檔並保存成DataFrame的資料形式:
import pandas as pd
data_path = "./soc-sign-epinions.txt"
with open(data_path, "r") as f:
# 每筆資料以\\n分隔
all_txt_str = f.read().split("\\n")
# 前4行不要
# 每筆資料內用\\t分隔: FromNodeId, ToNodeId, Sign
txt_list = [txt_str.split("\\t") for txt_str in all_txt_str[4:]]
edge_df = pd.DataFrame(txt_list, columns=["FromNodeId","ToNodeId","Sign"])
# 去除遺失值
edge_df = edge_df.dropna()
接著,做一些簡單的前處理:將用戶編號轉成整數型態,並將分數由1和-1轉成1和0,也就是把預測問題看成是一個分類問題,總共兩類:1和0。
edge_df["FromNodeId"] = edge_df["FromNodeId"].apply(int)
edge_df["ToNodeId"] = edge_df["ToNodeId"].apply(int)
edge_df["Sign"] = edge_df["Sign"].map({"1":1, "-1":0})
看看資料是否存在不平衡資料(Imbalanced Data)的狀況:
choose_df["Sign"].mean() # 0.8529722881198804
結果差不多是0.8530,大部分是Sign=1的資料,所以透過下採樣(UnderSampling)的方式來解決:
# 選出與Sign=0相關的資料
Sign0_df = edge_df[edge_df["Sign"]==0]
node_set = set(Sign0_df["ToNodeId"])|set(Sign0_df["FromNodeId"])
choose_df = edge_df[edge_df["FromNodeId"].isin(node_set)&edge_df["ToNodeId"].isin(node_set)]
# 重新以 1.5:1 的比例製作資料
ChooseSign0_df = choose_df[choose_df["Sign"]==0]
ChooseSign1_df = choose_df[choose_df["Sign"]==1]
ChooseSign1_df = ChooseSign1_df.sample(int(len(ChooseSign0_df)*1.5))
choose_df = pd.concat([ChooseSign0_df, ChooseSign1_df]).sample(frac=1)
製作圖(graph)
下面我們需要將資料由DataFrame轉換成圖資料,也就是節點與邊的形式。
接著需要用到pytorch,並將用戶編號重新編碼,可以先寫一個叫IdEncoder的class記錄並轉換兩者的用戶舊編碼(NodeName)和新編碼(Id)):
import torch as th
class IdEncoder:
def __init__(self, NodeName_set):
self.NodeId_dict = {
NodeName: idx for idx, NodeName in enumerate(sorted(NodeName_set))
}
def __len__(self):
return len(self.NodeId_dict)
@property
def NodeName_set(self):
return set(self.NodeId_dict.keys())
@property
def max_id(self):
return max(self.NodeId_dict.values())
@property
def IdNode_dict(self):
return {idx:NodeName for NodeName, idx in self.NodeId_dict.items()}
def node_to_id(self, node):
return self.NodeId_dict.get(node)
def id_to_node(self, id):
for NodeName, idx in self.NodeId_dict.items():
if idx==id: return NodeName
return None
轉換編碼並製作圖所需的3個tensor:
- 節點特徵:順序依Id位置存放(這邊因為沒有用戶特徵所以就全放1),型態為float。
- 邊連結方式:形狀為(2, E),E是邊的數量,型態為long。放的是邊連結的兩個節點Id。
- 邊特徵:形狀為(E, F),F是邊的特徵數量,型態為float。順序需與邊連結方式對應。
# 轉換編碼
encode = IdEncoder(node_set)
rom_list = choose_df["FromNodeId"].map(encode.NodeId_dict).tolist()
to_list = choose_df["ToNodeId"].map(encode.NodeId_dict).tolist()
sign_list = choose_df["Sign"].tolist()
# 將圖資料所需的: 節點特徵(node_attr_ts), 邊連結方式(edge_index_ts), 邊特徵(edge_label_ts)
# 製作成tensor方便後續導入到圖中
node_attr_ts = th.ones(len(encode)).float().reshape(-1, 1)
edge_index_ts = th.tensor([from_list, to_list]).long()
edge_label_ts = th.tensor(sign_list).float().reshape(-1, 1)
製作graph時,會需要使用torch_geometric套件,讀者可以在
官網
查看安裝方式:pytorch-geometric
由tensor轉成圖資料只需要簡單的一行:
from torch_geometric.data import Data
data = Data(x=node_attr_ts, edge_index=edge_index_ts, edge_attr=edge_label_ts, edge_label=edge_label_ts)
我們需要設定:
- 節點特徵(x)
- 邊連結方式(edge_index)
- 邊特徵(edge_attr)
- 邊標籤(edge_label)
設定後,就可以查看圖的相關資訊了。透過顯示data以查看剛剛輸入的相關資訊,方便我們檢查是否輸入正確。
分割資料集
在其他深度學習的訓練流程中,會將原本的資料集分割成:訓練資料集、驗證資料集及測試資料集。在圖資料中也一樣,不過與一般資料不同的是,圖資料的邊會再被分成兩類,一類會被用於模型的輸入資訊,也就是一般所說的特徵(feature),另一類則是被當成模型的訓練標籤(label)。我們會將第一種用於輸入資訊的邊稱為message edges,而被用於預測答案的邊稱之為 supervision edges。
要分割圖資料的邊可以使用torch_geometri內建的RandomLinkSplit幫忙分割:
from torch_geometric.transforms import RandomLinkSplit
train_data, val_data, test_data = RandomLinkSplit(
num_val=0.1,
num_test=0.1,
is_undirected=False,
neg_sampling_ratio=0.0,
disjoint_train_ratio=0.2,
)(data)
這樣就可以簡單分割出多個資料集了。以下解釋各參數的意思:
- num_val: 驗證資料集的比例
- num_test: 測試資料集的比例
- is_undirected: 我們的邊是否是無向的,因為我們的邊是有方向性的,所以選False。
- neg_sampling_ratio: 添加負邊的比例,這在預測兩節點間是否有連線的任務才會用到。
- disjoint_train_ratio: 這邊可以設定message edges與supervision edges的比例。
簡單解釋一下負邊(negative edges)的意思,就是圖上沒有的邊。如果設定了抽取負邊,則會幫我們在預測的資料中,加入一定量不存在的邊,看模型能不能正確預測出,這兩個節點間其實是沒有連線的。
這次的任務並不是要讓模型學會預測兩節點間有沒有連線,事實上我們假設了任意兩節點間都可以連線,要預測的是連線上的標籤屬於信任還是不信任?
每個分割出的資料集都有4個重要的屬性,這些屬性在下面的模型中會用到。
- x: 節點特徵
- edge_index: message edges的連接
- edge_attr: message edges的特徵
- edge_label: supervision edges的連接
- edge_label_index: supervision edges的特徵
建立模型
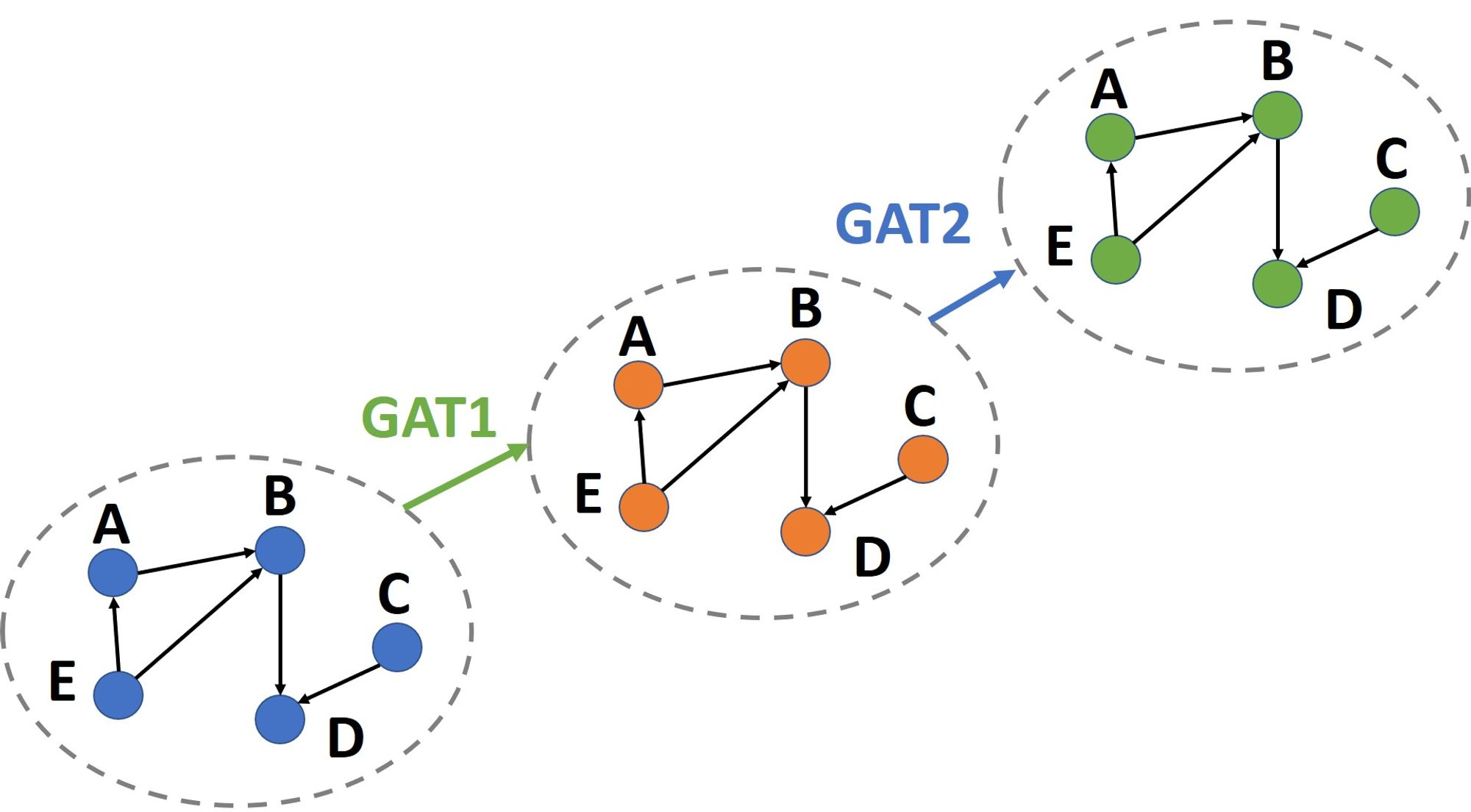
建立模型前先簡單介紹一下GAT的作用,GAT會從每個節點開始輸入,周圍傳遞資訊節點的特徵,與該邊的特徵到模型中。模型輸出是當前節點的嵌入(embedding),然後重複這個過程直到將所有節點都做過一次,最後就能得到所有節點的嵌入,這個過程就是做了一層的GAT。這個過程相當於透過GAT的運算,得到了一張新的圖。圖的結構沒變,改變的是每個節點的嵌入。
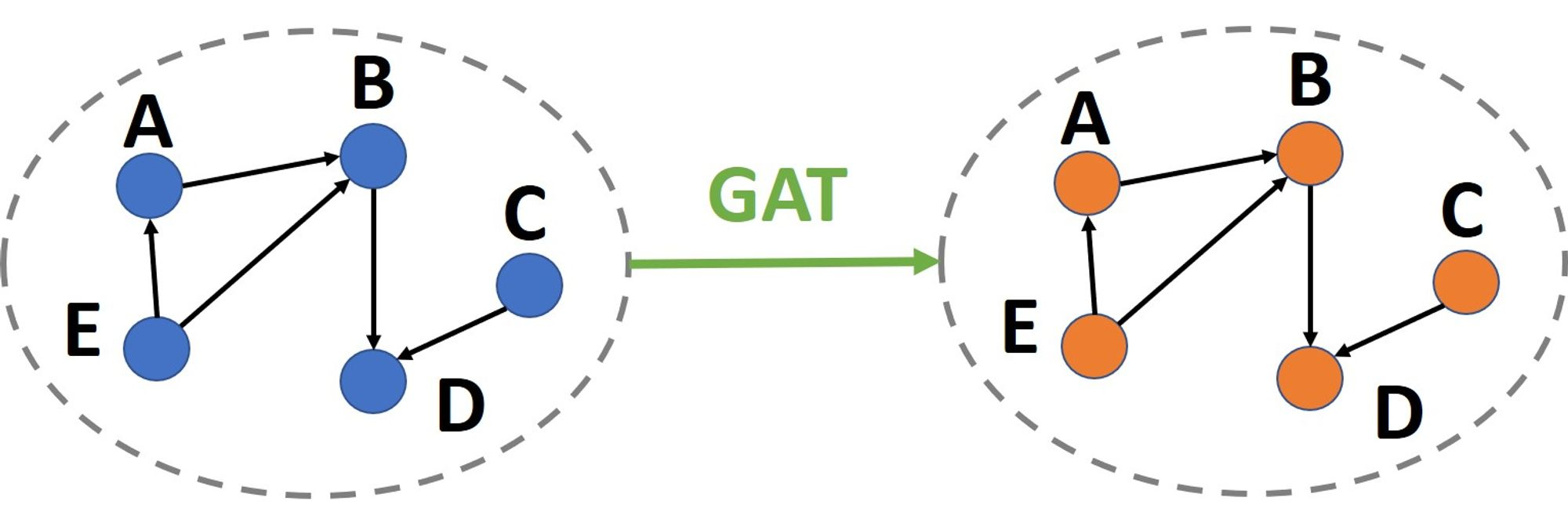
如果我們要做多層的GAT,就是在前一層GAT的結果上再做一次GAT。
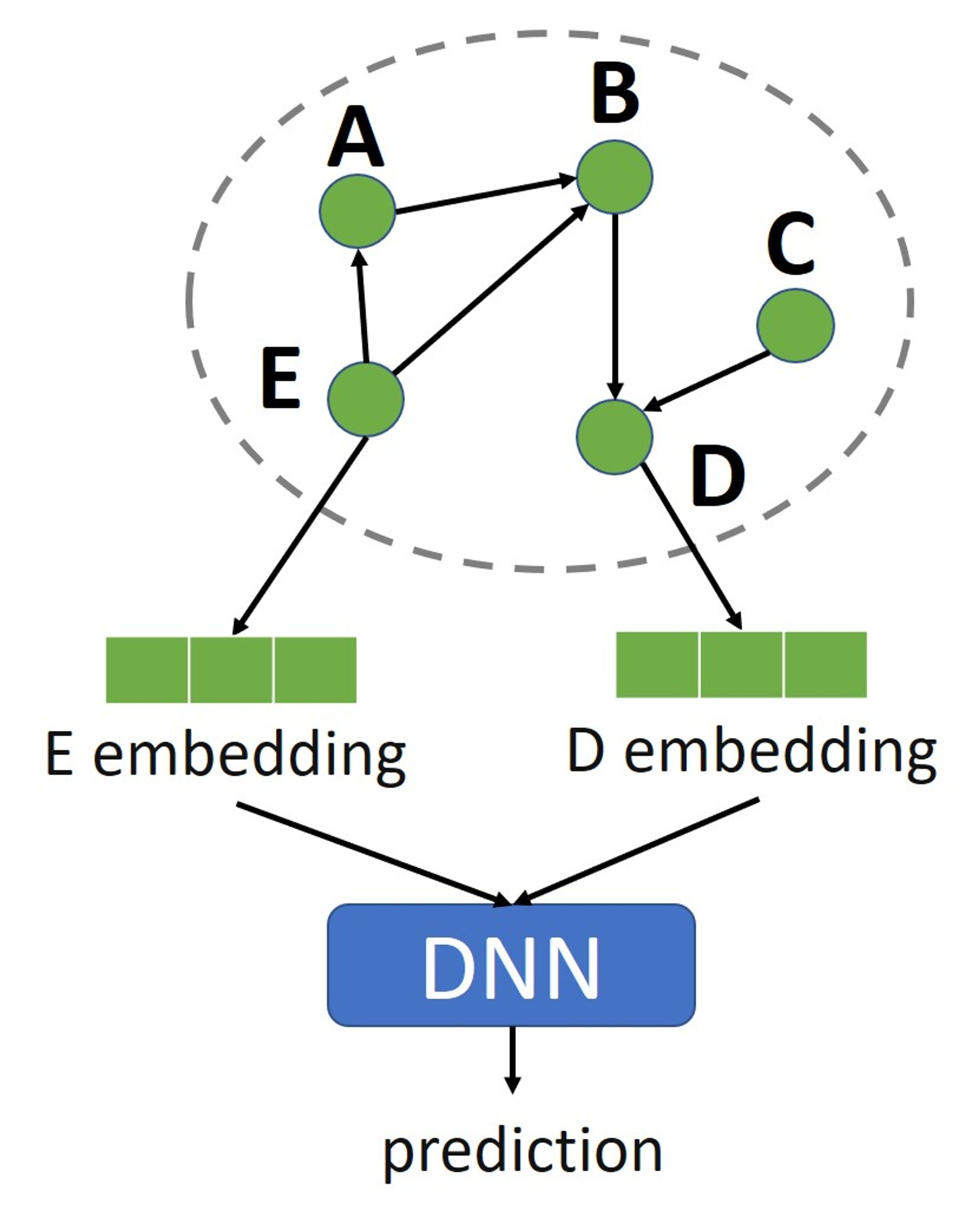
如果要預測兩節點間的邊的類型,就拿與該邊相鄰的節點的嵌入出來,輸入到一個簡單的神經網路中做預測即可。
下面附上實作的程式:
from torch_geometric.nn import GATv2Conv
from torch_geometric.nn.dense import Linear
class GATEncoder(th.nn.Module):
def __init__(self, encoder_size):
super().__init__()
hidden_channels, out_channels = encoder_size
self.conv1 = GATv2Conv(
(-1, -1), hidden_channels, edge_dim=1, add_self_loops=False
)
self.lin1 = Linear(-1, hidden_channels)
self.conv2 = GATv2Conv(
(-1, -1), out_channels, edge_dim=1, add_self_loops=False
)
self.lin2 = Linear(-1, out_channels)
self.conv3 = GATv2Conv(
(-1, -1), out_channels, edge_dim=1, add_self_loops=False
)
self.lin3 = Linear(-1, out_channels)
self.conv4 = GATv2Conv(
(-1, -1), out_channels, edge_dim=1, add_self_loops=False
)
self.lin4 = Linear(-1, out_channels)
def forward(self, x, edge_index, edge_attr):
x = self.conv1(x, edge_index, edge_attr) + self.lin1(x)
x = x.relu()
x = self.conv2(x, edge_index, edge_attr) + self.lin2(x)
x = x.relu()
x = self.conv3(x, edge_index, edge_attr) + self.lin3(x)
x = x.relu()
x = self.conv4(x, edge_index, edge_attr) + self.lin4(x)
x = x.relu()
return x
class EdgeDecoder(th.nn.Module):
def __init__(self, decoder_size):
super().__init__()
hidden_channels = decoder_size
self.lin1 = Linear(-1, hidden_channels)
self.lin2 = Linear(-1, 1)
def forward(self, NodeConvH_ts, edge_label_index):
from_ts, to_ts = edge_label_index
NodeH_ts = th.cat([NodeConvH_ts[from_ts], NodeConvH_ts[to_ts]], dim=-1)
x = self.lin1(NodeH_ts).relu()
x = self.lin2(x).sigmoid()
return x
class GNN(th.nn.Module):
def __init__(self, encoder_size, decoder_size):
super().__init__()
self.encoder = GATEncoder(encoder_size)
self.decoder = EdgeDecoder(decoder_size)
def forward(self, x, edge_index, edge_attr, edge_label_index):
NodeConvH_ts = self.encoder(x, edge_index, edge_attr)
return self.decoder(NodeConvH_ts, edge_label_index)
在GNN內分別實作了encoder與decoder,encoder負責使用4層GAT提取圖中節點的嵌入,decoder負責將節點的嵌入轉換成對指定邊的預測結果。
訓練
就與一般模型的訓練流程相同,不過這邊使用了一個開源的項目來幫助我們來完成early-stopping的功能。
from pytorchtools import EarlyStopping
import matplotlib.pyplot as plt
def get_pred(data, model):
return model(
x=data.x,
edge_index=data.edge_index,
edge_attr=data.edge_attr,
edge_label_index=data.edge_label_index
)
@th.no_grad()
def get_pred_no_grad(data, model):
return model(
x=data.x,
edge_index=data.edge_index,
edge_attr=data.edge_attr,
edge_label_index=data.edge_label_index
)
@th.no_grad()
def get_loss_in_eval(data, model):
model.eval()
pred = get_pred_no_grad(data, model)
target = data.edge_label.reshape(-1, 1)
loss = F.binary_cross_entropy(pred, target)
return loss
def get_loss(data, model):
pred = get_pred(data, model)
target = data.edge_label.reshape(-1, 1)
loss = F.binary_cross_entropy(pred, target)
return loss
model = GNN((4, 6), 12)
optimizer = th.optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-3)
scheduler = th.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
early_stopping = EarlyStopping(patience=30, verbose=False)
trainLoss_list = []
valLoss_list = []
for epoch in range(0, 2000):
model.train()
optimizer.zero_grad()
train_loss = get_loss(train_data, model)
train_loss.backward()
optimizer.step()
scheduler.step(train_loss)
val_loss = get_loss_in_eval(val_data, model)
trainLoss_list.append(train_loss.detach().numpy())
valLoss_list.append(val_loss.detach().numpy())
early_stopping(val_loss, model)
if early_stopping.early_stop:
print("Early stopping")
break
print(f'Epoch: {epoch:03d}, Loss: {train_loss:.4f}, val_Loss: {val_loss:.4f}')
plt.plot(trainLoss_list, label='train')
plt.plot(valLoss_list, label='val')
plt.legend()
plt.show()
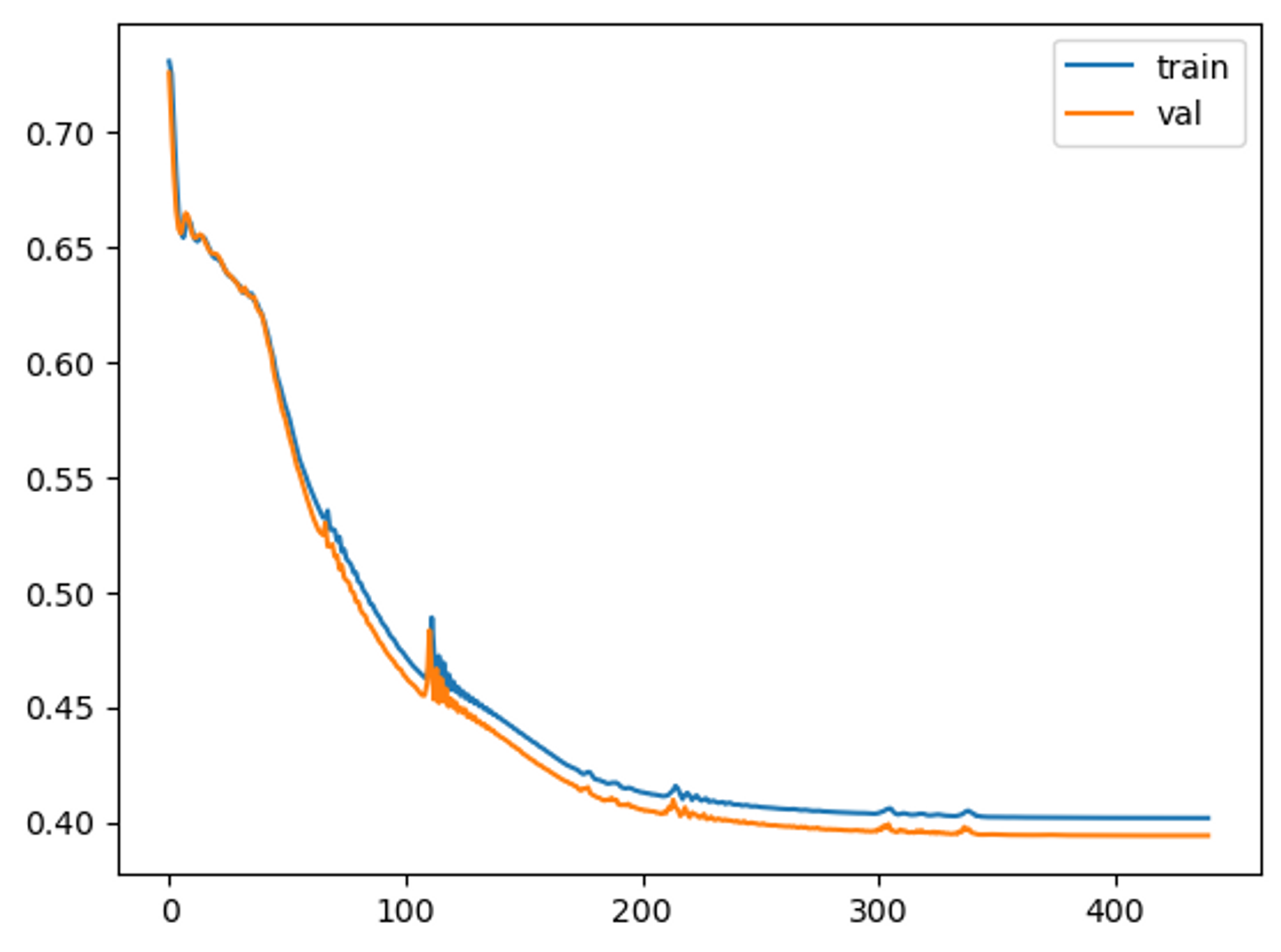
最後我們會得到一個訓練過程的曲線圖:
測試
最後我們來看看模型在測試資料集上的表現,我們先讀取early_stopping幫我們保存的最佳模型,預設的保存路徑是./checkpoint.pt,然後就可以計算測試資料集上的預測結果和誤差了:
model = th.load("checkpoint.pt")
model.eval()
test_pred = get_pred_no_grad(test_data, model)
test_label = test_data.edge_label.reshape(-1, 1)
test_loss = get_loss_in_eval(test_data, model)
最後你也可以繪製confusion matrix來看看預測狀況:
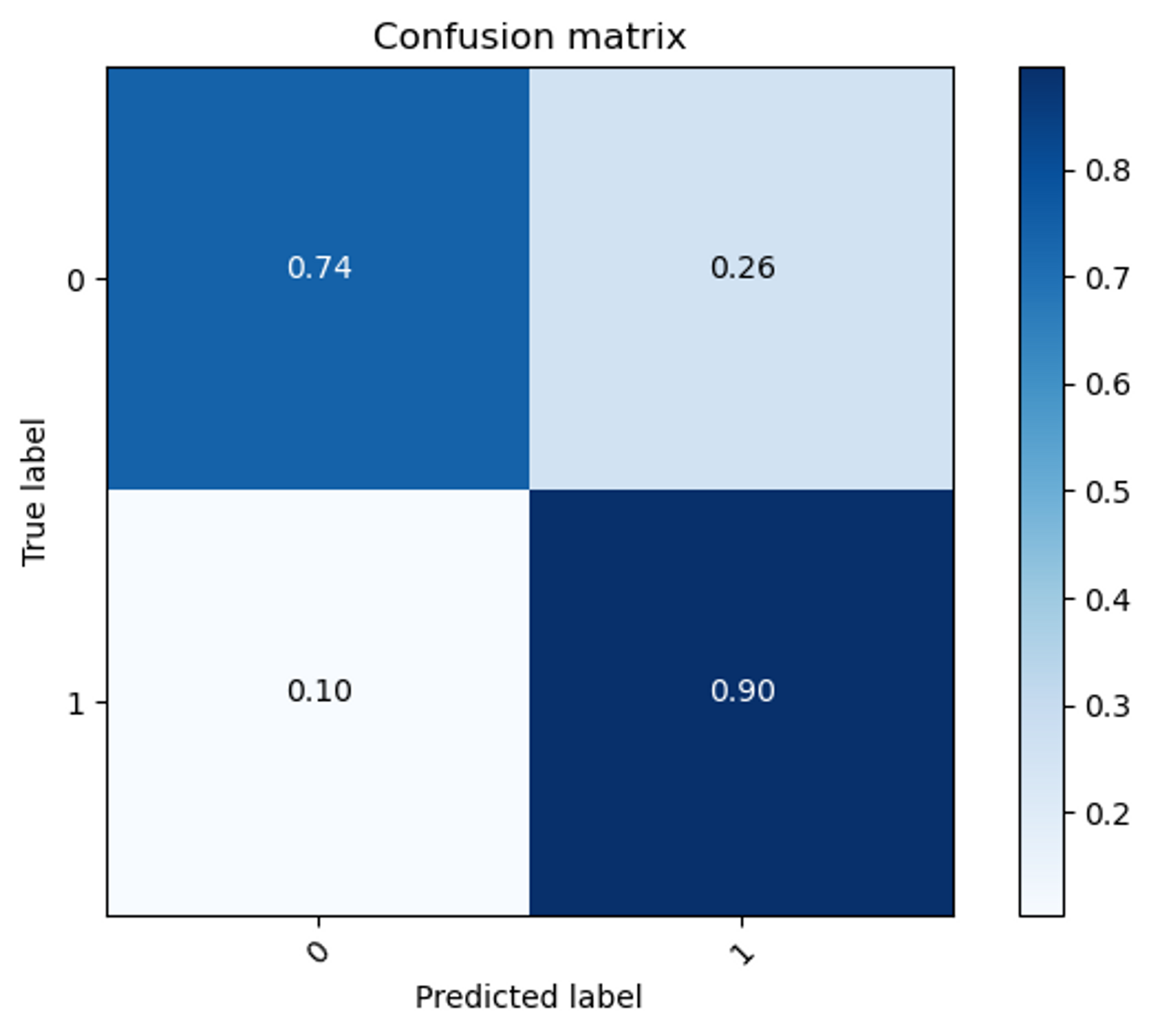
我們可以看到對於標籤是1的資料,模型可以猜對九成。而對於標籤是0的資料,模型可以猜對七成。各位也可以自己試試看能不能通過調整模型的設計,跑出比這個更好的結果。
總結
本篇透過實作方式,帶領讀者認識圖神經網路的運作流程。隨著深度學習的發展,圖這種非結構化資料的任務也越來越受到關注,主要原因是,生活中存在許多非結構化的資料,這些資料都很適合以圖的形式來表達結構。事實上,所有常見的資料類型,如聲音序列,或是影像,其實都可以看成是一種圖,並用圖的形式來表示。所以圖神經網路其實蘊含了無限可能性,等待大家來發掘!
本篇的程式碼可以在我的github
中找到。
最後希望這篇文章有幫助到你,我們下次再見。
參考
https://web.stanford.edu/class/cs224w/
https://pytorch-geometric.readthedocs.io/en/latest/modules/transforms.html
Github
https://github.com/jimmyzzzz/GNN-example.git
(撰稿工程師:朱柏丞)




