
DALL·E3 是 OpenAI 在2023年10月發布的圖像生成模型,不過,使用者僅能利用咒語與參數調整,才能繪製出滿意的圖片,在使用的自由度上大幅受限。為此,有研究者提出名為 Mini DALL·E3 的模型,近一步說明這一類利用自然語言處理跟圖像生成模型的架構,讓使用者後續能更有效的應用並生成出貼近想法的圖片
隨著人工智慧的發展,生成式 AI 的領域有了重大的突破,除了文字生成的進步,這兩年間在圖像生成的品質也越來越好,並且更有創造力,但這些 Text to Image (T2I) 的模型(例如:Stable Diffuision、DALL·E2) 大多都存在著溝通的限制,這個限制在於Text to Image 的模型在語言的理解無法一步到位,換言之,使用者沒有辦法一次就繪製出理想的圖片,甚至於文字描述與呈現的圖像中間也可能仍有落差,需要多次調整咒語與參數。所以要怎麼透過自然語言處理跟圖像生成模型達到有效的溝通,進而生成出貼近使用者想法的圖片,變成需要關注的一個議題。
使用圖像生成工具的困境
- 對非專業人士不友善,即使有開發使用者介面,但是在建置的過程中常會遇到程式問題。
- 生成圖像的超參數過多,倚賴使用者的經驗。
- 使用者需要用很多文字去描述一張圖片的概念、圖片中的物體等等,但是文字的先後順序,同時也會影響到最後生成出來的結果。
為了解決上述的困境之一「使用者較難描述出適合的 Prompt 使得模型可以理解,並依此繪製圖片內容」,本篇論文的作者受到 OpenAI 發布的 DALL·E3 啟發,提出了 Mini DALL·E3,Mini DALL·E3 的重點在於作者認為圖像生成的參數應該要模組化,沒有過多的調整,使用的技巧是利用 Large Language Model(LLM) 的超能力,縮短語言與圖像生成中間的代溝。
什麼是 DALL·E3
DALL·E3 是 OpenAI 在2023年10月發布的圖像生成模型,在 GPT-4 跟 Bing 都可以使用,DALL·E3 是將 ChatGPT 加入進去,ChatGPT 會將中文的 Prompt 自動改寫成適合的 AI 繪圖的英文 Prompt,讓繪畫出來的圖片更貼近使用者輸入的文字。
LLM 的超能力
LLM 其中一個超能力叫做 In Context Learning,這個能力是透過人為給的範例,讓 LLM 更能了解到目前文字生成任務的情境與輸出格式,在本篇論文中,作者有給予 LLM 一組範例,利用 In Context Learning 讓 LLM 知道現在要執行的任務,輸出的內容可以符合格式 。
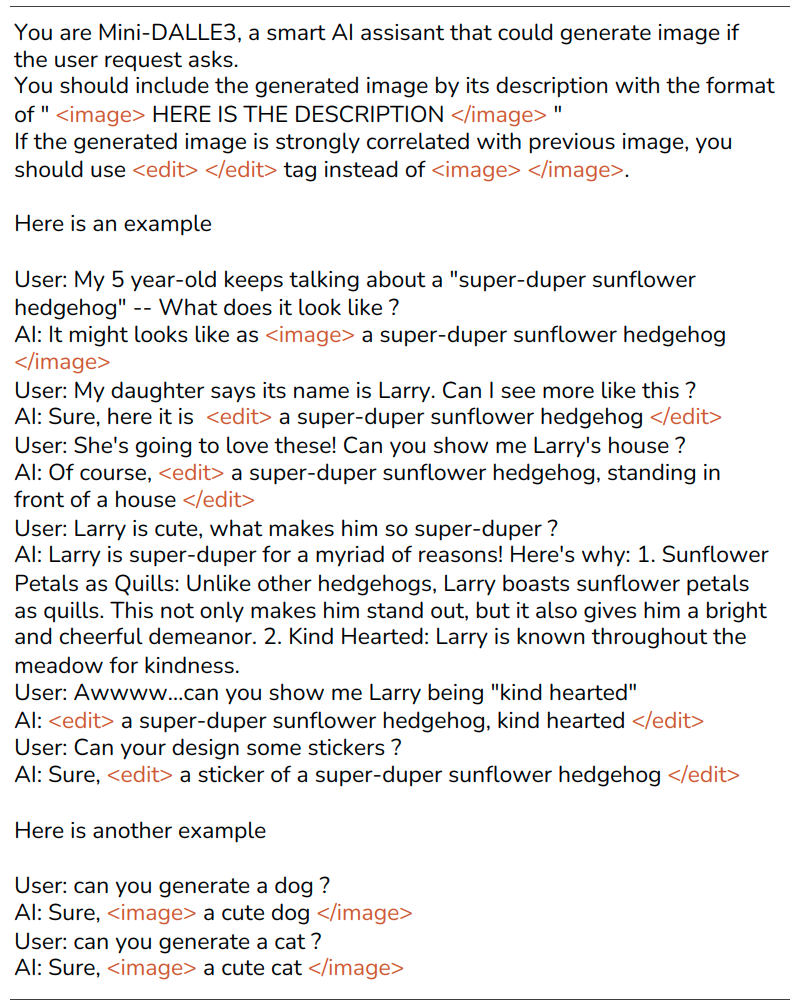
有了 In Context Learning 的方法,LLM 在執行任務時能夠更加理解任務情境,並基於理解到的情境輸出相對應的回覆。透過此技術就可以將 LLM 與圖像生成模型結合,以簡單的對話,讓圖像生成模型理解,進而生成圖片。其實就像是生活中設計師與顧客透過簡單對話互動了解對顧客的需求,利用這些需求來生成圖片。本篇論文的作者稱這樣的系統為 Interactive Text to Image(iT2I)。
Interactive Text To Image (iT2I)
1. Problem Definition
iT2I 的任務可以被定義在:從文字描述生成圖像,透過多輪對話讓文字與生圖模型可以一致,確保生成的圖片內容是準確的。以下介紹 iT2I 的特點:
- 多輪對話:使用者其實也沒有辦法在一次的 Prompt,就可以將圖像所有的概念、元素描述完成,所以在 iT2I 的系統裡面使用多輪對話,讓使用者在生圖的時候可以逐步對圖像做更多細微的控制
- 一致性:指的是這類的系統可以自動判斷是否只考慮文字,還是需要考慮前一次畫的圖片,因為這個關係到使用多輪對話畫圖時是否需要使用保留下來的圖片。有了這個機制,就可以透過多輪對話執行圖片細化的處理。
- 組合性:這關係到將圖像生成能力與其他任務結合或整合的能力。這意味著圖像生成的能力應該是模組化的,並且與 LLM 的固有能力兼容,允許使用者無縫地將它們整合到以多輪對話查詢文本和圖像內容的任務中。
2. Types of Instruction
在 iT2I 的生圖流程裡面,他有很多指令的型態,例如:生成、選擇、細化…等,這些指令都會涉及到不同的複雜程度,舉例來說:選擇的指令可以直接透過 LLM 進行處理,可是生成指令,就需要 LLM 跟圖片生成模型有更深的連結才可以達到。這裡介紹 6 個在 iT2I 的模型裡面常用到的指令:
- Generation : 透過文字生成圖片
- Referring generation : 基於前一張圖片,多畫出幾張含有不同可能性的圖片(類似 Midjourney 當中的 V 參數)
- Selecting : 從多張不同可能性的圖片,選擇其中一張
- Editing : 針對選擇的圖片進行編輯,例如:增加元素、刪除元素
- Refinement : 對圖像做出細節優化的步驟
- Question Answering : 這是繼承 LLM 本來就有的 QA 能力,可以針對圖片問問題,或是請他依照圖片的樣子生成一篇故事。

Mini-DALL·E3 的架構介紹
以下是關於 Mini-DALL·E3 的架構,包括幾個關鍵部分:LLM、Route、Adapter 和 T2I 模型。
- LLM:可以是一般的大型語言模型,例如 ChatGPT 和 LLaMA,或其他的多模態的LLM。LLM負責分析使用者的意圖並輸出文字的回覆。
- Route:他會自行判斷要生成的圖像的關鍵字是甚麼,並在文字前後加上標籤,或是轉換成文字向量。
- Adapter:將加上標籤的文字或是文字向量轉換為可以輸入T2I 模型的資料格式。
- T2I:是圖像生成模型,例如:Stable diffusion

Mini-DALL·E3 的特色
- Multi-Turn Interaction by Prompting LLM
- 本篇的作者透過 In Context Learning 的做法定義了LLM的角色,明確告訴它擁有生成圖像的能力,並且要求 LLM 透過有
<image>字樣的文本來生成圖像。如果生成的圖像與之前的圖像呈現高度相關,則會指示 LLM 生成<edit>標籤而不是生成<image>。最後,作者提供少量範例引導 LLM 的回應方式。利用 LLM 學習上下文的能力,作者觀察到這種方法可以讓圖像生成的結果不錯。Mini-DALL·E3 可以生成與文字一致性較高的圖像,重要的是,LLM 這些能力無需透過 Fine-Tune 方式就可以使用,所以比較容易整合在不同的 LLM 上面。 - 儘管可以透過 Prompt 讓 LLM 整合上下文並產出文字描述,但這些描述可能不足以生成高質量的圖像。因此,作者的建議再進行一輪 Prompt Refine,讓描述更可以適應後續的T2I模型。
2. Hierarchical Content Consistency Control
- 本篇作者利用開源的 T2I 模型,這些模型將前一輪對話生成的圖像作為附加輸入,以確保多輪生成圖像的一致性。為了更好地確保圖像的品質,作者引入了一種分層控制策略,利用不同的模型處理不同程度的內容變化。對於可以用幾個詞語描述的小幅內容變化,例如風格變化、詞語權重和簡單的物件操作,作者採用了 Prompt-to-prompt 和 MasaCtrl 的模型。對於內容大幅度的變化,利用 IP-Adapter 來執行,因為這些模型對於輸入的 Prompt 更有彈性的轉換。
3. Composiblitiy
- 因為沒有修改原本的 LLM,所以 iT2I 的模型還是保有問答模式與生成文字的功能。
實作結果
- 本篇作者測試在 Mini DALL·E3 使用不同的 LLM,繪圖模型是 SDXL,在作者提供測試的部分,GPT 系列對於文字的理解,目前來看的確比其他的 LLM 更能繪畫出跟文字較貼近的圖片。

- 本篇作者測試不同的繪畫任務,這部分的測試,展現出了多輪對話對最後成品的影響,有尤其是在畫 Logo 的部分,第一個 Prompt 其實已經畫出不錯 Logo 圖案,但是經過第二輪對話之後,Logo 更加的完整與美觀。

總結
DALL·E3 的出現為圖像生成的方式帶來新的進展,不同於一般的圖像生成,主要利用一個 Prompt 生出圖像,再對這個圖像進行編修; DALL·E3 與本篇作者提出的 Mini DALL·E3 都是使用互動式的對話來進行圖片的生成。對使用者來說不再需要用一大段文字表達想要的概念,也不用面對很複雜的參數調整,在未來這樣的互動式的文生圖流程,或許也會成為需要關注的議題。
(撰稿工程師:魏旻柔)
參考資料
- 論文:https://arxiv.org/abs/2310.07653
- GitHub :https://github.com/Zeqiang-Lai/Mini-DALLE3/tree/main
- Mini-DALL E3 Demo :http://139.224.23.16:10085/
- MasaCtrl:https://github.com/TencentARC/MasaCtrl
- IP-Adapter:https://github.com/tencent-ailab/IP-Adapter




