
近期十分熱門的AI繪圖模型,除了Midjourney外,另一個同樣受到討論的就是Stable Diffusion了,除了知道如何應用它生成所需的圖片之外,本篇文章將深入說明從文字生成圖片的過程中,需要經過哪些步驟以及當中一些有趣的模型。我們將使用Pytorch框架及hugging face上訓練好的模型,實際進行Stable Diffusion的流程。
先簡單的介紹Stable Diffusion,它的主要功能就是根據人所給出的文字,並畫出相對應的圖片出來。(如下圖所示)。不過Stable Diffusion並不是一個單一模型,而是由多個模型所組成。
在訓練模型時,會將訓練的圖片加入雜訊(noise),以預測latent space中的雜訊。加入雜訊的目的是,希望模型具備反推能力,也就是在生成圖片時能將圖中的雜訊去除,並還原成沒有雜訊的圖片。
這裡主要由幾個模型組合而成,包含提取文字特徵的tokenizer與text encoder;為了整合圖與文字,表現出不錯的latent representation,就需要U-Net;最後則是將上述資訊轉為圖片的VAE。接著,就依序讓大家認識每個模型的細節用途,及Stable Diffusion生成的整個流程。

下圖就是Stable Diffusion生成出一張圖片的流程圖,接著依序說明每個步驟的任務:

第一步(資料輸入):我們需要輸入兩個資料,分別是一段文字及一個雜訊。文字是為了產出圖片的文字提示;而雜訊就是初始化圖片的樣子。這個由一串隨機數字組成的雜訊並不複雜,透過這一串數字及文字提示產生出最終的成果圖片。
下圖使用Pytorch作為範例,「prompt」為預計讓模型生成的圖片,也就是文字生成圖片的輸入。而上述提及的雜訊,其實就是輸入隨機的數字;而大小是固定的,會根據後面的U-Net 模型決定雜訊大小。就目前的U-Net而言,所需的大小就是[batch_size, 4, 想要生成的長度//8, 想要生成的寬度//8]。

第二步(文字處理):將文字輸入轉為能讓模型理解文字含義的Embedding,轉換Embedding需要兩個小模組。第一個是Tokenizer,主要是讓一段文字分割成各個小Token,如:「I am a boy」會轉換成「I」、「am」、「a」、「boy」。但電腦無法理解這些文字,因此,會需要使用CLIP、BERT等語言模型,讓這些Token轉換成Embedding。Embedding能讓一串被模型訓練過的數字,轉成電腦能理解的語言形式。如:「I」變成[1,0,0,0]、「am」變成[0,1,0,0]、「a」轉變成[0,0,1,0]、「boy」則變成[0,0,0,1]。圖二寫的將文字轉換成[77, 768]所代表的意思就是總共有77個字,每個字都會有768個數字代表它。
程式碼中要先載入transformers上的語言模型:CLIPTextModel及CLIPTokenizer。CLIPTokenizer主要是將文字切成小Token,而CLIPTextModel就是將小Token轉換成文字Embedding。

接下來,為文字轉換成embedding的步驟:

這裡是比較有趣的部分,在Stable Diffusion的生成中,classifier-free guidance是個要特別注意的概念。因為,如果我們都以文字控制生成圖片的樣式,可能會太過侷限。因此,我們會期待這些生成的圖片具有變化性,例如背景能帶點自己的想法或是具設計感的汽車造型,而這些就需要輸入無指涉的文字,例如將空白字符當成文字,這樣就不會有文字意義了。

最後是將原本有條件輸入的text Embedding,以及無條件輸入的空白Embedding合併,也就是將原本維度都是[1, 77, 768]的兩個Embedding併成 [2, 77, 768]。

第三步(latent representation的生成):將雜訊及前一步驟所整理好的text embedding作為U-Net的輸入,以生成出理解文字含義,並跟著文字含義所出現的latent representation。U-Net基本上是由一個Encoder和Decoder組成,兩個模組都是以ResNet為基底為設計。圖3就是一個U-Net的模型架構。
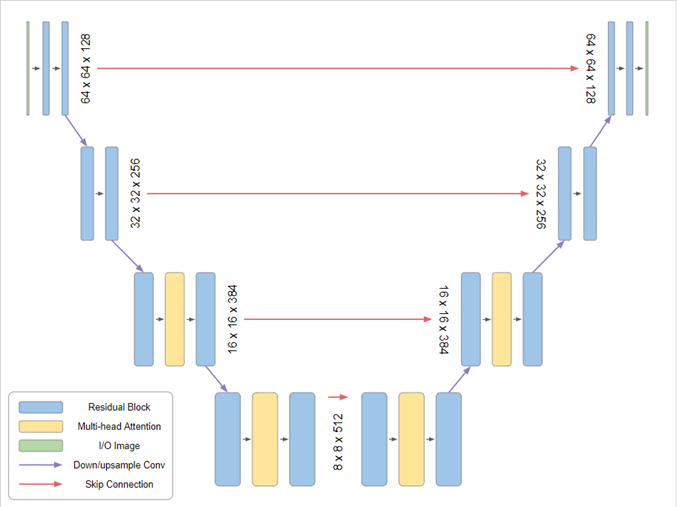
U-Net的Encoder主要先針對圖像提取特徵,並隨著深度增加變成一組小圖片的特徵,最小圖的特徵會保留最全域的圖片特徵,例如物件的輪廓。接下來的Decoder則是將小圖片的特徵轉回原本的圖片大小。為了防止因為深度增加,而失去局部的細節特徵,在Encoder的downsampling與Decoder的upsampling的過程中,都會加入skip connection以保護特徵。這邊的U-Net,訓練中會使用雜訊,在forward pass的時候都會在圖中加入雜訊,以作為latent space中的雜訊預測訓練。在生成圖片時,則會將雜訊去除,藉由沒有雜訊的圖片,讓U-Net模型找到文字與圖像之間的latent representation的關係。
圖中是將訓練好的U-Net模型,及同時在做Denoise雜訊使用到的Scheduler演算法載入,Scheduler的演算法有許多種,這裡以LMSDiscreteScheduler為例。

這邊會定義兩個超參數,分別是「num_inference_steps」及「guidance_scale」。
num_inference_steps:一般來說,使用的step越多,結果越好,但是step越多,所需的生成時間就越長。 由於Stable Diffusion 在step相對少的情況下效果很好,通常建議使用預設的數值為50。想要更快的結果,可以使用較小的step;想要更高品質的結果,可以使用更大的數字。
guidance_scale:Guidance Scale是生成圖片與輸入提示的緊密程度,及輸入的多樣性間的平衡,它的典型值在7.5左右。增加的比例越多,圖片的質量就越高,但是得到的多樣性就越低。
下一步就是迴圈的內容,這個timesteps就是steps的次數,裡面會將文字的text_embedding及噪音的latent_model_input當成輸入,放進U-Net模型中,然後將每次帶有雜訊的圖片去預測裡面的雜訊,再將預測出來的雜訊透過Denoise演算法去除雜訊,並保留生成的圖片。持續這個步驟timesteps幾次,就可以得到我們想要的latent representation。
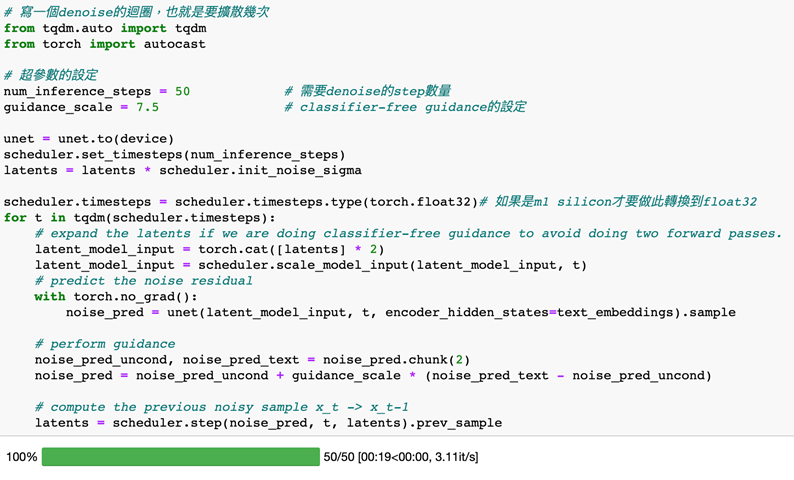
第四步(還原成圖片):基本上到這一步已經算是把整個Stable Diffusion的演算法都完成了。但是,還有最後一件事情要做,由於我們生成出來的latent representation並不是一張肉眼看得懂的圖片,所以需要一個VAE模型將latent representation還原成一般人看得懂的圖片,到了這一步,才算完整做完整個Stable Diffusion。
這裡一樣,從hugging face中拿出訓練好的AutoEncoder模型。

將上個步驟還原出來的 latent representation放入vae裡面,並使用vae的decoder來還原成圖片。最後,推導出來的圖片被存放在gpu中,我們需要將它移到cpu,且顯示出來。

結論:
Stable Diffusion雖然在訓練,及模型設計上相當複雜,但在推論實作上相對好理解。從本文中能得知一個Stable Diffusion需要有哪些模型,並理解整個文字轉圖片的過程,也能體驗到在不同的text encoder模型下,文字的理解會會對生成圖片造成哪些不一樣的生成結果。最後,建議如果要使用此程式碼體驗的話,應使用有GPU的環境,否則生成時間會非常的久。
Reference:
https://arxiv.org/abs/2112.10752
https://github.com/huggingface/diffusers
https://huggingface.co/CompVis/stable-diffusion
https://huggingface.co/docs/diffusers/optimization/mps
(撰稿工程師:廖柏瑜)




