當你想打造一個「數據產品」時,僅有資料模型的解讀靜態報告是不夠的,一個更貼近使用者應用場景的解決方案是必須的。從資料科學模型到產品之間,還有哪些事情必須要顧慮?
從知識管理到資料科學
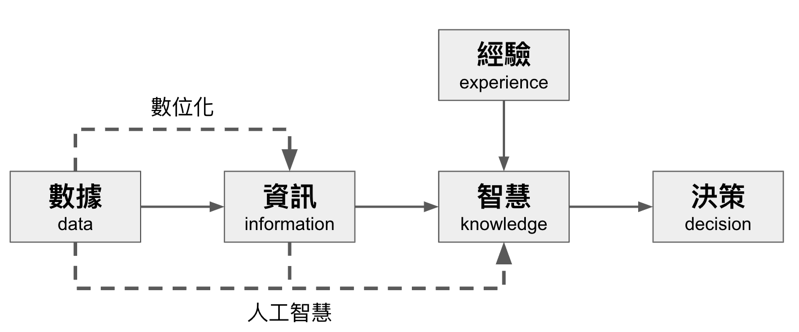
資料科學是一種從資料到決策過程的方法,探討用模型去解讀不同的資料與其意涵。在管理學院中有一門知識管理的課程,將利用原始資料產生知識的過程分成四個階段。根據維基百科的定義,知識管理(Knowledge Management,KM)包括一系列的定義、創建、傳播、採用新的知識和經驗的戰略和實踐,可以用於個人知識或組織中商業流程的實踐。知識管理的目標是幫助人類如何系統性地累積經驗、管理知識,成為一個更有智慧的人類,這其中「經驗」扮演重要的齒輪。從知識管理到資料科學,知識或決策的產生方式正在改變。如果可以利用機器的優勢來轉換知識,降低對經驗的依賴,那人們就得以更加專注於「決策」。換句話說,資料科學是一種利用數據幫助人進行決策的方法。
資料科學的的目的是從資料中找關係,具體來說可以分成幾個階段:「取得資料」→「資料前處理」→「資料轉換」→「資料分析」→「資料解釋」→『發現知識」的六個階段 。 就像以下這張圖來自 Fayyad 在 The KDD Process for Extracting Useful Knowledge from Volumes of Data 所提到的資料科學的處理流程。不過這個過程並看似單一的線性流程,不過實際上並非從左邊一步一步做到右邊就可以打完收工。這個過程其實是需要重複不斷的嘗試,一層一層探索,最終才得以找到真正具有價值的知識。
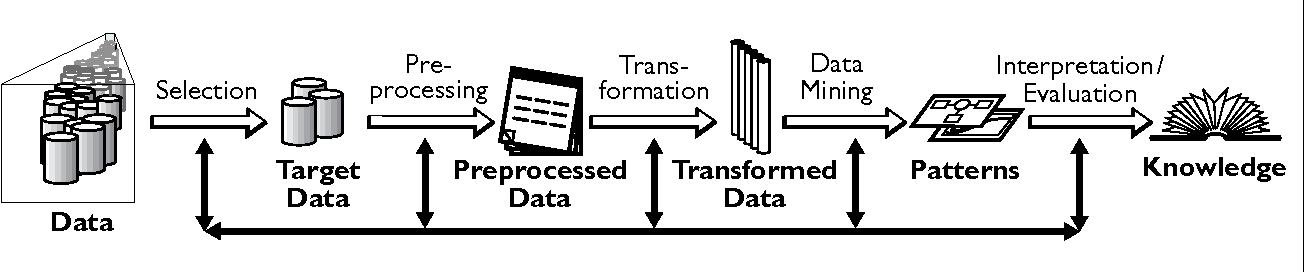
KDD(Knowledge Discovery in Database)是資料庫領域在資料探勘(Data Mining)前慣用的一種名稱(也有人說 Data mining 是 KDD 的一個環節),資料探勘領域中的知名的會議就叫做 SIGKDD。這邊用「Knowledge」這個字其實就是呼應知識管理中的「Knowledge」。
從資料模型到數據產品
傳統的資料科學模型通常只考慮到「產出模型」為止,著重的是如何訓練一個「好」的模型,產生交付的通常是一個模型。但有了一個好的模型之後,然後呢?
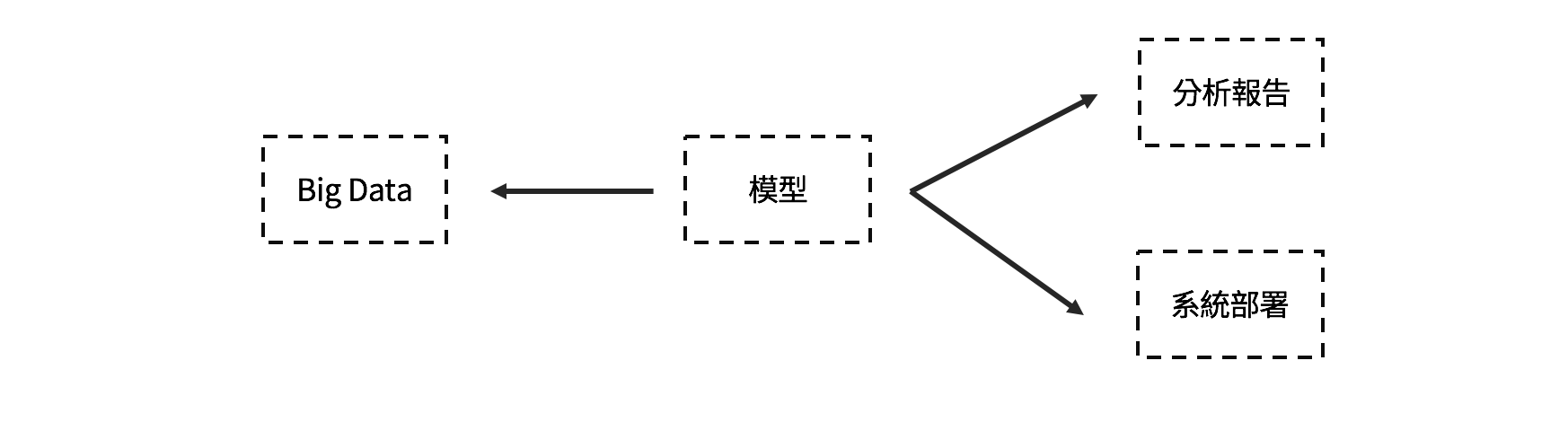
模型相對來說是抽象的數學公式或是程式演算法,其實不易直接讓面向使用者。大部分的情況是具有「資料素養」的專業工作者,例如資料分析師、資料科學家會將模型解讀成一般人可以理解的資訊。因此「產生一個分析報吿、說一個好故事」是許多資料科學工作者需要訓練的基礎能力,例如資料視覺化(Data Visualization)或說故事(Storytelling)的技能。
不過當你想要打造的是一個「數據產品」時,僅有資料模型的解讀靜態的報告是遠遠不足的。我們需要的是更貼近使用者應用場景的解決方案。所以一般來說,從資料模型到數據產品需要思考的是「如何將模型部署成一個可持續使用的線上系統」。除此之外,也必須思考如何將模型應用更真實、更大量的資料中。
從實驗資料到真實資料
在初期模型訓練過程中,可能會有「比較嚴謹」的分析過程。例如資料會經過標準的抽樣過程,資料也必須滿足一定的統計代表性。但隨著大數據(Big Data)的觀念跟方法逐漸成熟,比起嚴謹可能更重視「可用」與「有效」。在《Big Data》這本書中,告訴我們在資料量夠完整的情況下對於資料的誤差容忍性是比較強的。不過這不代表可以忽略資料搜集的量測誤差,建議對統計解讀有興趣的朋友可以參考 那些關於「大數據」的謬論:不要再說樣本即母體了! 和 大數據與偏差樣本 這兩篇文章。所以從實驗資料到真實資料的情境中,會有幾個現實需要面對:
- 收集到的資料可能更多、更快、更髒
- 產生的結果通常是比較模糊的
需要思考的是如何在有限的時間中,產生可以用的模型。
從模型到系統部署
模型跟報告是相對抽象跟靜態的,可能難以讓使用者直接有感。因此,從資料模型到數據產品的另外一個重點在於「如何將模型部署成一個可持續使用的線上系統」。例如像推薦系統或是圖形辨識系統之類的系統,就是以應用為目的,模型只是其中的部分而已。從這些角度來看,是否可以更早期就把最終的應用考慮進來,或是需不需要讓資料料工作者也具備系統部屬的產出能力都是打造數據產品時的重點。
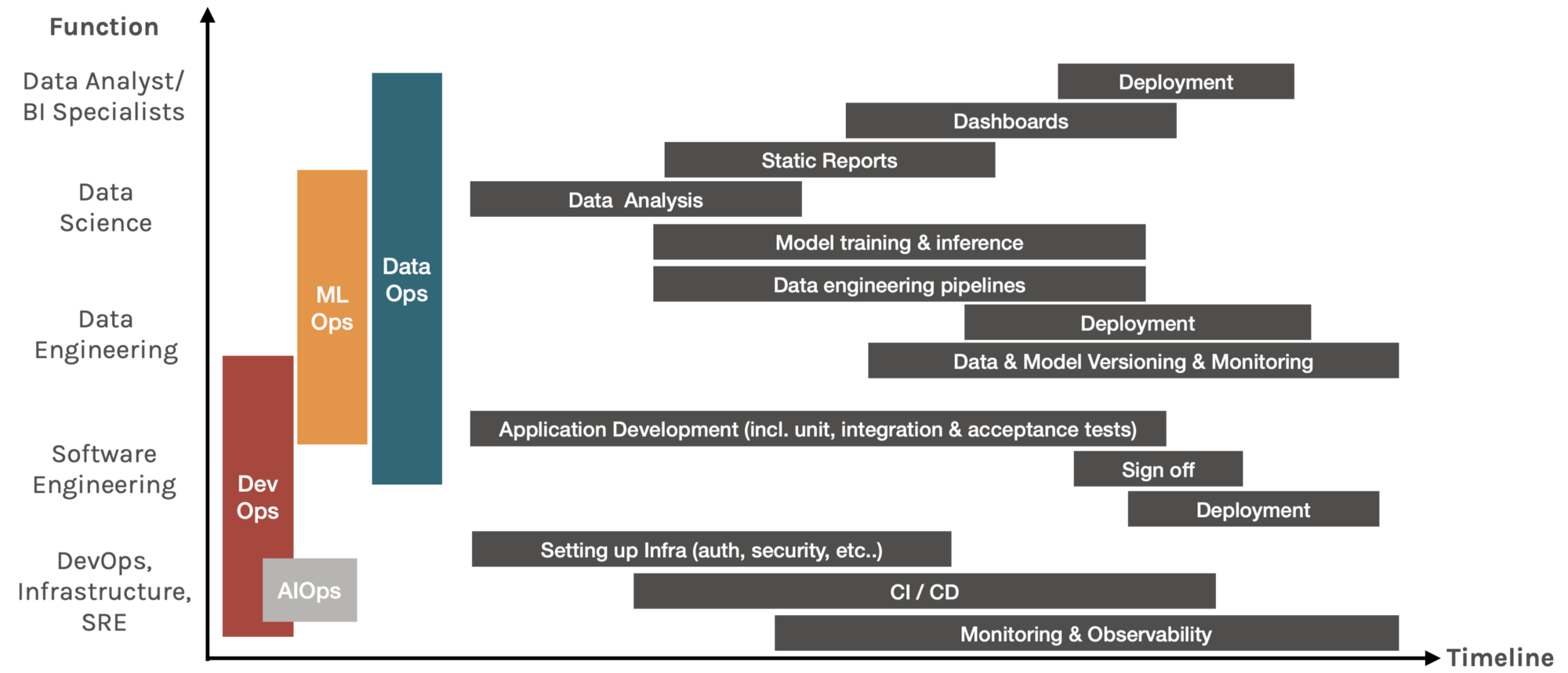
而最近流行的 DataOps、MLOps 和 AIOps 各種 Operation 方法,就是在探討如何導入敏捷開發的原則。讓資料開發的 Pipeline 可以有更好的分析、部署、迭代的過程,進而實踐自動化運行的目標。