在這個機器學習或AI蓬勃崛起的年代,各個領域都能運用到相關技術,金融市場正是其中一個熱門領域,每個人都想預測市場上各個商品的高點、低點,或是上漲或下跌的趨勢,更期待能應用於股市行情的預測上。
你將會學到:
- 如何從最基礎的原始資料開始加入特徵,製作要預測的目標,以及建立一個基礎的深度學習模型並預測答案。
你需要先知道:
- 基礎的金融交易知識,例如K棒的定義,分別是開高低收的組合。
- 建議具備基本的機器學習知識,並能理解從資料處理到模型建構的流程。
一、題目背景
這次我們將示範如何以Transformer預測台灣指數期貨上漲與下跌波段,選定的商品標的為台灣指數期貨,這是追蹤台灣加權指數的衍生金融品,當我們在大盤低點買進多單,上漲時就會賺錢;反之,在高點時買進空單,下跌時就會賺錢,如果相反操作的話就會賠錢。
因此,我們可以藉由預測下一個時間點的點數高或低,選擇要買進多單或空單,並等到下一時間點賣以賺取差額。
二、題目定義
這個範例中,我們不去預測「某時間點」的「點數位置」,而是利用AI模型去預測何時會有大波動發生,且這個波動是連續上漲或是連續下跌的情況,也就是説,透過預測連續的紅K棒或連續的綠K棒出現的時機點,讓我們可以在發生前佈好單,等待發生時賺取一大段價差。
三、資料準備與前處理
範例中原始資料使用了2022/3/1 - 2022/10/31 的台指期貨資料,其中每筆為每天開盤時日盤8:45 ~ 13:45每筆每分鐘的資料,意即每筆都是一分K的資料,欄位資料為每個一分K的開高收低及交易量,共五個欄位。
在前處理我們預計做到:
- 波段資料,並把它標記為Y,以便後續模型預測
- 加入更多特徵,這邊希望使用各種技術指標
- 資料標準化,因為後續模型希望用到神經網路模型
3-1. 處理波段資料
在以下程式範例中,首先我們先將資料從1分k轉為3分k,當然也可以換成別種長度的k棒,因為怕時間太短造成的大震盪,不容易反應出趨勢,所以這邊不用1分k。
接著將「連續5根紅K棒」以及「連續五根綠K棒」的資料抓出來,並分別標記為1和-1,其餘的情況都標注為0,這種情況如果一根k棒代表3分鐘,那麼連續5根就代表連續15分鐘都同時向上或向下跑,也就是一段趨勢的發生。
(圖一)、被抓出時段的內容
接著製作Y的label,這邊將連續紅K標示為1,連續黑K標記為-1,平常的情況就是0。
在這邊Y的比例為 正常資料 : 紅K : 黑K = 37160 : 6139 : 7401 約為 0.73 : 0.12 : 0.14 ,稍微的類別不平衡。
3-2. 加入特徵
資料中的特徵品質會直接決定到AI模型預測結果的好壞,在期貨交易中交易者有著不同的派別,無論是看籌碼分析,或是看技術指標下單的都各有支持者,為了能快速demo,所以我選擇將ta-lib 這個技術指標的函式庫內的技術指標都加入到資料中,以便後續的模型學習。這樣無腦的亂加並不一定會幫助模型去學習到有用資訊,建議讀者可以自行增加覺得有用的特徵讓模型學習。
3-3. 資料標準化
因為後續要使用神經網路為基底的模型,所以我們先將資料做標準化。
將Y製作成 one-hot encoding的方式來讓模型訓練。
四、模型處理
這份資料是時序型的資料,可以使用像是RNN的作法,我們打算使用Transformer的模型架構來做實做示範大家看,之後讀者可以自行將模型做修改,使模型效果更好。
這裡的範例使用最基礎的一層Transformer Encoder並加上Positional Embedding,在訓練方面也少了一些CallBacks Function的使用,也沒有使用到驗證集,上述所提的這些都是讀者們後續可以自行加入的。
4-2. 模型表現
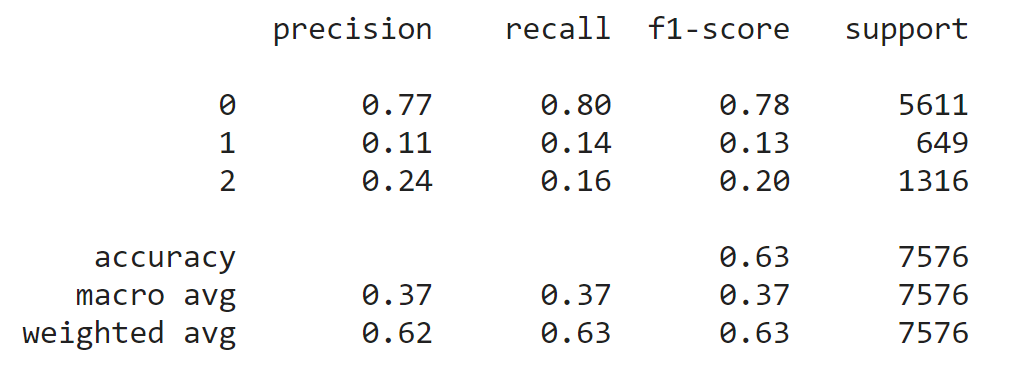
模型表現上其實能預期到表現得不是太好,除了模型很基本之外,類別的不平衡也還沒有處理。可以看到整體模型的表現如下圖:
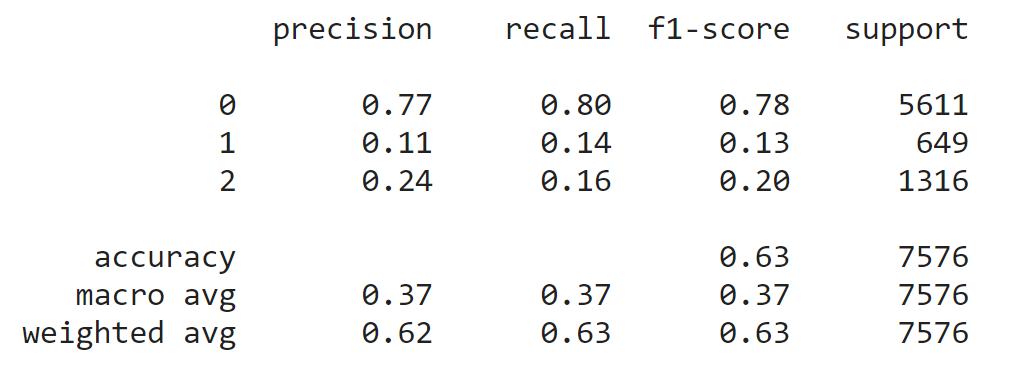
(圖二)、模型表現
因為這份資料的特性,在現實生活中我們更在乎1或2類別的precision,也就是模型一旦預測到1或2類別時,希望現實發生的機會也越大,我們就更能掌握這段行情。
五、結論
模型成效方面,因為資料裡面的類別屬於極大的不平衡,所以在模型跑出來成效並不理想,但其實還有一些後處理可以做,使模型效果表現再提升,例如整段的上升或下降的資料中,模型應該要連續去預測出相同的類別,我們可以利用這個特性去將沒有連續出現的預測資料去除。又或是去觀察整段連續被預測為波段的資料中,機率是否都大於某個數值,加入這些複合的條件來讓預測出來的條件更嚴苛,讓precision更漂亮。
在未來後續能做的事情還有很多,列點如下:
- 目前模型預測幾乎會偏向預測0的那一方,未來可使用一些處理資料不平衡的手段,讓模型訓練成效更好。
- 模型也能自行更換,可以使用RNN或是將Transormer的架構修改。
- 除了現在加入技術指標的方法,可以使用Domain的方式加入有用的指標,刪除較為無用的指標,甚至將指標做些處理,例如常見的黃金交叉、死亡交叉等,讓指標更有意義。
- 可以加入籌碼面的資訊,利用網路爬蟲或是期交所的資料,加入更多元的特徵。
- 目前只用了八個月的資料,可以嘗試將過去的資料都加進模型裡,應當會有不錯的效果。
- 要預測的Y是連續嚴格上升或嚴格下降的K線型態,讀者也可以改為想預測的目標。
- 除了台指期商品外,這個範例也適用於所有的時間序列資料,包含了常見的金融商品,如股票,亦或是工業上一些訊號的資料都可以使用。
完整的程式碼如下,讀者們有任何問題歡迎來信討論,敬請期待下一集的文章。
https://github.com/MagicUmom/EK-futures_wave_predict/blob/main/FINAL_prediction.ipynb




