
在近期的 AI Research,我們在弱人工智慧(Artificial Narrow Intelligence) 領域中,不斷推陳出新、突破天花板、創造新的演算法。我們針對任務收集相關知識下的資料,並訓練其模型。同時造就了各個領域及行業中的 AI 工程師,但你有沒有曾經想過,未來會有一個 AI 模型能夠分析所有任務,回答你所有問題,取代掉數個領域的 AI 模型呢?
2022年5月中,DeepMind 丟出了撼動AI圈子的震撼彈:「Gato」!相信大家對 DeepMind一定不陌生,從先前的 AlphaGo 、 AlphaStar 在圍棋及遊戲產業上大殺四方,以及 AlphaCode 於 Codeforces 競賽上領先54%的程式人員。而今年又以通才代理模型(A Generalist Agent)「Gato」,佔據 AI 產業的版面,其概念是希望能以一個模型在相同權重之下,能夠處理文本、圖片說明(image caption)、控制機器手臂,甚至是玩電子遊戲。
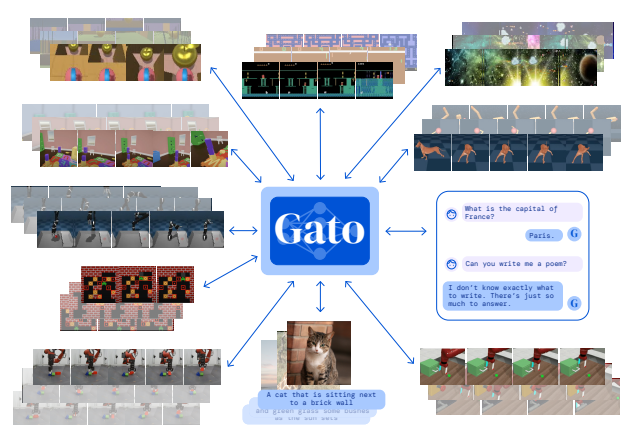
而訓練這種單一模型應用於多種任務上會有什麼好處呢?
- 以一擋百:
相信這是最直接明瞭的,我們能夠以一個模型來去通用多種任務,省去我們要針對各不同領域建立的模型。 - 增廣見聞:
在單一模型上,模型能夠擁有個多樣性的數據集,在不同的任務上也能夠參考不同資料。這也是筆者認為在成功的「Gato」上能得到很好的效益。
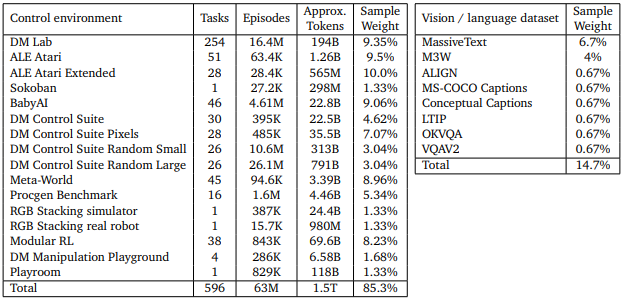
圖二為文中,Gato 所使用到的資料集,其中便有包括左表與控制相關(機器手臂、電子遊戲等相關資料)以及右表與影像及語言相關的資料集,而其中 Sample Weight 為該數據集在訓練批次中,所佔的平均比例。而以「Tokenization」的方式,主要就是將其龐大數據集針對不同型態的資料來去做預處理成序列的 tokens,接著將其序列以各種規範方式進行排序,最後再將其 Embedding 成模型能夠實際理解及訓練的數據,並以現今最熱門的Transformer (language model) 來去訓練模型,而對各個不同資料型態處理的方式有興趣,也能至論文中「Tokenization」去閱讀。
在這樣的資料集下以及通才人工智慧(Generalist AI)的概念下,可想而知在未來各式各樣領域的資料集也會逐漸比模型更為重要,正如2021年吳恩達教授 (Prof. Andrew Ng) 所舉辦的Data-Centric AI Competition,主要以資料及為主的競賽,在相同的模型下,我們要怎麼處理並整理這些資料,會是未來更為重要的課題。
然而 Gato 主要是以通才 (Generalist) 為首要目標,因此雖然能夠對應多個不同的任務,但實際的效果還是需要時間及比較來去印證,可惜的是目前沒有提供開源程式,讓大家能夠體驗。在各大社群網站也有眾多同好認為這是前往強人工智慧 (Artificial General Intelligence) 一大步,雖然作者們在論文中完全沒有提到,讀者們也能夠思考,這樣的技術是否能夠真正的應用在真實世界當中。也期待在不久的未來,也許能在工廠、電動車及社群媒體上再次看見 Gato 的身影。(撰稿工程師:孫培元)
1.Paper:https://arxiv.org/pdf/2205.06175.pdf
2.DeepMind 官方筆記:https://www.deepmind.com/publications/a-generalist-agent




