
當黃仁勳在 GTC 2025 的 Keynote 結束後,對於絕大多數並非每天緊盯 AI 進展的觀眾而言,可能心中都會有一個疑問:「他到底說了什麼?」
確實,這場 Keynote 充滿各類的專有名詞:從 CUDA、NumPy、KooPy Numeric、cuLitho、到 NVLink,彷彿每句話都是一連串無止盡的技術術語。
然而,相比媒體標題上的幾大亮點一次看、各種懶人包,我們可能更需要問的是:「假設只能解釋一件事,這場演講真正的核心是什麼?」答案可能令人意外:不是晶片效能提升,也不是矽光子或人形機器人的進展,而是黃仁勳所提出的一個觀點——「Token 是 AI 的基石」(This is how intelligence is made, a new kind of factory generator of tokens, the building blocks of AI)。
我們都知道 Token 很重要,但為什麼黃仁勳在演講中還要反覆強調 Token?因為人們至今仍然低估了 AI 對「token」的需求。
為什麼我們需要重新理解 Scaling Law?
從 Generative AI、Agentic AI 到 Physical AI 的演進,每個階段都涉及三個基本面向:數據問題(Data Problem)、訓練問題(Training Problem)、擴展定律(Scaling Law)[1]。在過去一年裡,AI 產業一度瀰漫著一種焦慮:「模型越大、效果越好」的定律似乎碰到瓶頸,Scaling Law 似乎失效了?
黃仁勳演講中指出,過去一年人們對於 Scaling Law 的觀點都錯了。從 AI 對算力的需求來看,Scaling Law 實際上不但穩定,甚至還加速了(hyper accelerated)。
雖然他沒有明說,但在黃仁勳背後秀出的那張簡報,已經揭露了他真實的想法:「Scaling Law 已經從一個變成三個:Pre-training Scaling、Post-training Scaling 與 Test-time Scaling。」
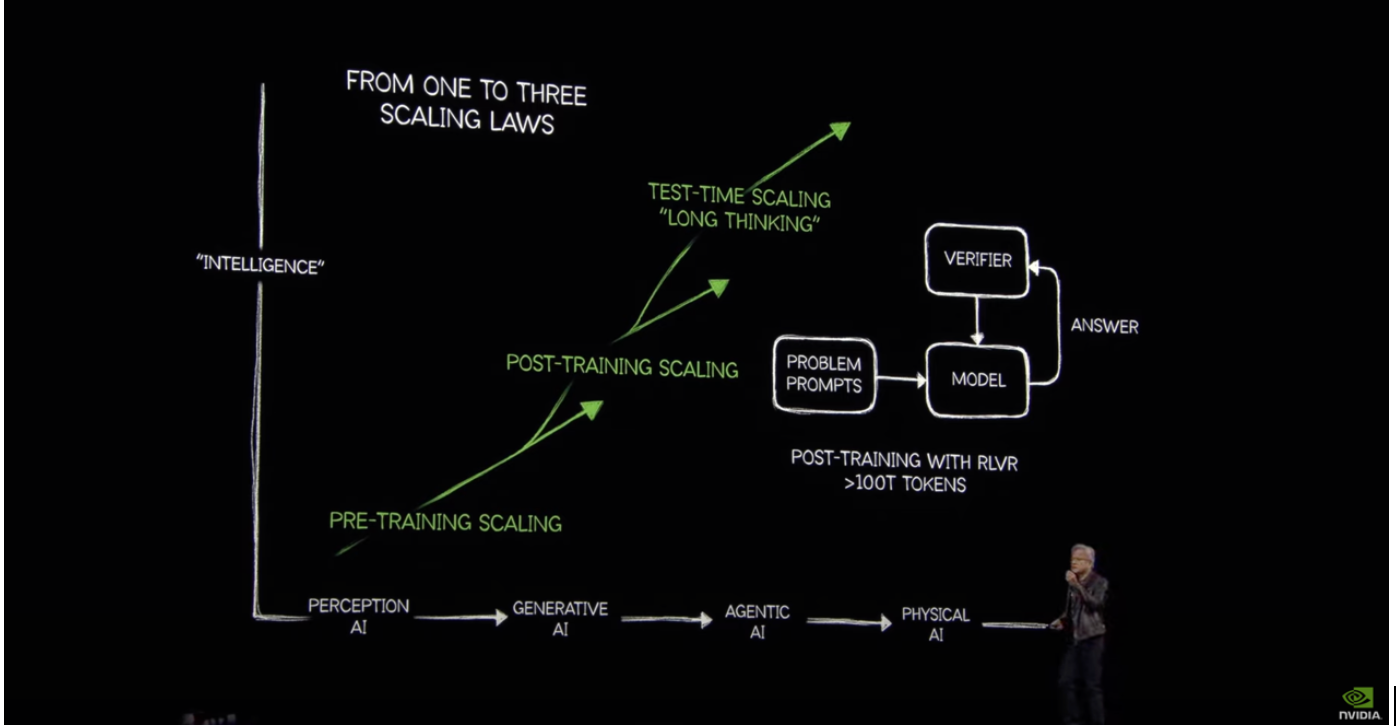
1. Pre-training Scaling Law:讓 AI 模型從海量資料中吸收基礎知識。
所謂的 Pre-training Scaling,就是 AI 最初的基礎能力建構階段。它的運作方式就像是接龍遊戲:根據大量資料預測下一個最有可能出現的詞或 token。
因此,越大的資料量、越久的訓練時間,就可以得到更精準的模型。
2. Post-training Scaling Law:讓 AI 學會用人類能接受且熟悉的方式表達。
光靠「接龍遊戲」的方式訓練出的 AI,往往無法符合人類的語言風格或價值觀。這時候,「Post-training Scaling」登場,透過 Supervised Fine-Tuning(監督式微調)與人類偏好學習(如 RLHF),讓 AI 學習人類溝通模式、價值判斷與互動邏輯。
例如 OpenAI 的 ChatGPT 就是透過大量人類回饋,調整模型如何表達與回應,讓模型從單純的語言預測器,進化為具備「人性化溝通能力」的 AI 助理。
這階段雖然所需資料量通常小於預訓練,但其對模型行為的改變非常深遠,對 token 的處理需求也趨於精緻與持續。
3. Test-time Scaling Law:讓 AI 像人類一樣進行深度思考與邏輯推理。
Test-time scaling 不再是訓練階段的產物,而是在 AI 實際上線推論任務時,進行多步驟、推導式的思考。這種方式常見於解數學題、邏輯謎題或複雜問題,透過將問題拆解為步驟,逐一推理,反覆驗證。
最常見的例子,就是 GPT 系列模型使用的「chain-of-thought」(思維鏈)提示工程,或「Let’s think step by step」這類提示語。
這類推論會拉長 token 使用長度,也提升了單次任務的複雜度。像 DeepSeek 就專注在這類推理任務的強化訓練,展現出更長鏈式任務的處理能力。隨著模型推理深度加深,token 的消耗自然也持續上升。
我們該如何衡量 AI 的能力?
過去,人們常以模型參數量或資料量作為衡量指標。但近年發現,即使投入資源與資料暴增,AI 在 benchmark 上的進步似乎逐漸趨緩。Scaling Law 是否失效,引發不少質疑。
然而,AI Alignment 組織 METR 近期提出一項新研究:以「AI 能完成多長的任務」作為衡量標準。根據他們追蹤近 6 年的數據,AI 的任務完成能力每約 7 個月就會翻倍——這可視為AI agent的摩爾定律!不只是模型變大,而是AI 實際可執行的任務變得更長、更複雜、更結構化
[2]。
這顯示出 test-time scaling 不僅仍然有效,而且成為 AI 是否真正發揮能力的關鍵依據。
而針對衡量AI晶片的能力上,在 GTC 大會上,黃仁勳也提到將AI晶片進步的指標,從電晶體數量轉移到電源效率。輝達的新晶片在相同的電源耗損下,AI 效能可提升 25 倍,並承諾在 2027 年前提升 900 倍。
啟示:Token 才是王道
回到 Keynote,黃仁勳想要傳達的訊息非常清晰:AI 未來只會需要越來越多的 token。
當我們理解了 AI 從 Generative AI、Agentic AI 到 Physical AI 的演進,就能更深刻體會這個觀點。AI 的表現不再只是依靠模型變大,而是每個階段都需要更大量的 token 處理能力——從知識學習、溝通對齊到推理行為,都離不開 token。
這也正是 NVIDIA 不斷推出更強大晶片與架構的真正原因:不是為了追求效能數據,而是為了更快速、更有效率地產出、處理與傳遞 token。Token 成為 AI 新的基本單位。每個公司不再只是成為資料中心,只注重儲存多少資料,而是成爲AI 工廠,在意每秒能產出多少 token,以推動業務成功。
甚至連商業模式都將轉向以「每百萬 token」計價——從硬體架構到底層邏輯再到營收方式,整個生態都將圍繞 token 這個新核心展開。
在GTC上,黃仁勳提到AI的階段實際上為四階段:Perception AI、Generative AI、Agentic AI、Physical AI。然而Perception AI 雖然屬於發展初期的重要階段,但主要處理非語言資料,與 token 的關聯較弱。 ↩︎
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/ ↩︎




