
說到「集成式學習」,你可能知道這是使用二種或更多的機器學習演算法,組合出預測能力更好的模型。我們可以在不同的競賽上,看到利用「集成式學習」建立的模型都有十分出色的表現,這也讓它成為近期十分熱門的技術之一。不過,該技術雖然十分熱門,但實際上能善用的人並不多,甚至有些人對於訓練資料的使用部分有些誤解,例如,當我們想要集合幾個基學習器打造超學習器(Meta-learning)的時候,兩者所需要的資料集常常讓許多人會產生混淆。
我們知道,機器學習模型能有效運作,通常是假設訓練資料、驗證資料、測試資料的分佈相同。於是,當我們拿所有原始訓練資料集來訓練基學習器,並且輸出每個基學習器對原始訓練資料集的預測值,當做超學習器的訓練資料。我們也輸出每個基學習器對原始測試資料集的預測值,來做為超學習器的測試資料。
此時,就出現一個問題:超學習器的訓練資料來自於「基學習器已知標籤的情況下,所得到的預測值」,超學習器的測試資料來自於「基學習器不知標籤的情況下,得到的預測值」。由於基學習器產生訓練資料跟測試資料的預測值機制不同,等同於資料來自不同分佈,可能不適合再用來訓練同一個模型。為此,在打造超學習器前,讀者必須先掌握訓練資料集的基本概念,才能避免錯用進而影響模型效能的狀況發生。
《集成式學習:Python 實踐!整合全部技術,打造最強模型》一書,不僅介紹了實務上常見的集成式學習演算法,如硬投票、軟投票、堆疊法、自助聚合法、適應提升法、梯度提升法、隨機森林、極端隨機樹等,也提供了十分詳盡的觀念說明,幫助讀者快速掌握理論基礎,也能了解各種集成式學習技術的實作。以下為本書重點摘要:
失敗的訓練資料集
我們想要使用中繼資料來訓練超學習器,因此必須要有能夠用來預測標籤的中繼資料。直覺想法是拿所有原始訓練資料集來訓練基學習器,並且輸出每個基學習器對原始訓練資料集的預測值,最後拿這些基學習器的預測值以及原始訓練資料集的標籤來訓練超學習器。然而一般來說這種做法並不一定有效,因為超學習器只能看見基學習器已經發掘的原始資料集優缺點,所以超學習器可能只能加強這些已知的優缺點。如果我們想要得到比較有效的集成後效能,要避免上述的訓練方式。
小編補充:不同觀點來看失敗的訓練資料集
機器學習模型能有效運作,通常是假設訓練資料、驗證資料、測試資料的分佈相同。舉例來說,我們不會拿手寫數字辨識圖片訓練模型,然後用這個模型分類貓狗圖片,因為訓練資料跟測試資料根本不同。
回到失敗的訓練資料集,拿所有原始訓練資料集來訓練基學習器,並且輸出每個基學習器對原始訓練資料集的預測值,來做為超學習器的訓練資料。我們也輸出每個基學習器對原始測試資料集的預測值,來做為超學習器的測試資料。
因此就出現一個問題:超學習器的訓練資料來自於「基學習器已知標籤的情況下,所得到的預測值」,超學習器的測試資料來自於「基學習器不知標籤的情況下,得到的預測值」。基學習器產生訓練資料跟測試資料的預測值機制不同,等同於資料來自不同分佈,可能不適合再用來訓練同一個模型。
保留(Hold-out)資料
較好的方法是使用保留資料,做法如下。
- 步驟 1:將原始訓練資料集分為基學習器資料集和超學習器資料集。
- 步驟 2:只使用基學習器資料集來訓練每個基學習器。
- 步驟 3:使用訓練好的每個基學習器,預測超學習器資料集。
- 步驟 4:使用每個基學習器的輸出,搭配超學習器資料集中的標籤,訓練超學習器。
可以發現在步驟 3,我們使用基學習器預測超學習器資料集的時候,並不需要提供超學習器資料集的標籤,因此基學習器會在不知道標籤的情況下做預測,並且拿來當作超學習器的訓練資料。保留資料的缺點是基學習器資料集跟超學習器資料集,都比原始訓練資料集還要小。如果資料筆數夠多,這個方法也許還可行。資料太少並且又要堆疊很多層,將會造成資料不足因而模型的誤差過大。
另外,假設基學習器資料集有 N 筆,超學習器資料集有 M 筆,每一筆資料的特徵個數是 P 個,基學習器的個數是 Q 個。則基學習器資料集的size 為 N 列、P 欄的矩陣,超學習器資料集的 size 為 M 列、Q 欄的矩陣。
也就是說,對超學習器而言,每一筆資料的特徵個數,即為基學習器的個數。
K 折交叉驗證(K-fold Cross Validation)
另一個方法是利用 K 折交叉驗證,來產生超學習器的訓練資料集,作法如下。
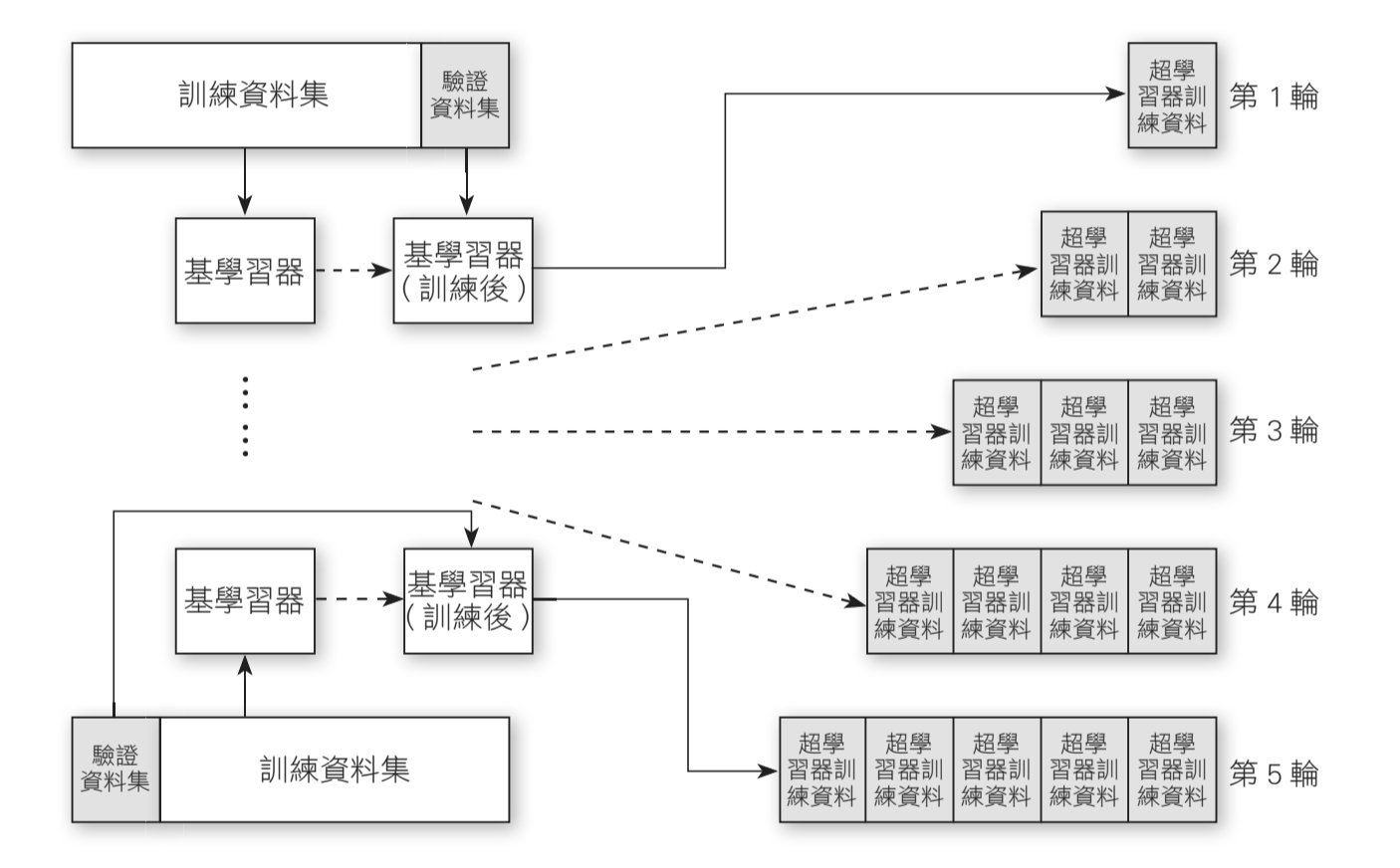
- 步驟 1:將訓練資料集分成 K 折(下頁圖中範例分成 5 折)。
- 步驟 2:拿 K-1 折的訓練資料集,訓練每個基學習器。
- 步驟 3:使用訓練好的每個基學習器,預測所保留的 1 折驗證資料集。
- 步驟 4:重複 K 次步驟 2 與步驟 3,並且讓每 1 折都輪流當過驗證資料集。
- 步驟 5:將步驟 4 所得的預測值,搭配原始訓練資料的標籤,訓練超學習器。
下圖的範例中,可以看到在第一輪的流程,我們拿 Fold1 到 Fold4 訓練每個基學習器,接著用每個基學習器預測 Fold5 的資料,得到 Fold5 的預測值。在第二輪中,我們拿 Fold1、Fold2、Fold3、Fold5 訓練每個基學習器,接著用每個基學習器預測 Fold4 的資料,得到 Fold4 的預測值。
因此,經過 2 輪,我們就獲得了 Fold4 跟 Fold5 的預測值。當我們完成 5輪,即可得到所有訓練資料的對應預測值,接著搭配所有訓練資料的標籤,即可拿來訓練超學習器。
本文節錄自《集成式學習:Python 實踐!整合全部技術,打造最強模型》,由旗標出版社授權轉載。




