Back-propagation(BP)是目前深度學習大多數NN(Neural Network)模型更新梯度的方式,在本文中,會從NN的Forward、Backword逐一介紹推導。
你想得到的模型基本上都是用BP的方式在更新梯度,基本原理是一樣的,只是隨著模型設計上的不同,導致梯度會往不同的方向前進,本文只介紹DNN的更新方式,之後再來寫RNN的更新方式。
先回想一下NN中forward方式:
輸入向量,經過NN模型輸出預測值,接著預測值與Label計算Loss,這個Loss表達的是模型與真實之間的距離,我們當然希望這個Loss愈小愈好,可以搭配下面Notation中的圖來理解。
Input Vector → NN → Prediction ↔ Label
可以想像成NN中的權重得到這個Loss,現在我們想知道這些權重對於Loss的影響程度,也就是Gradient,參數與Gradient影響著Loss的大小,BP的核心理念就是產生這個Gradient方式與更新方式。
Notation
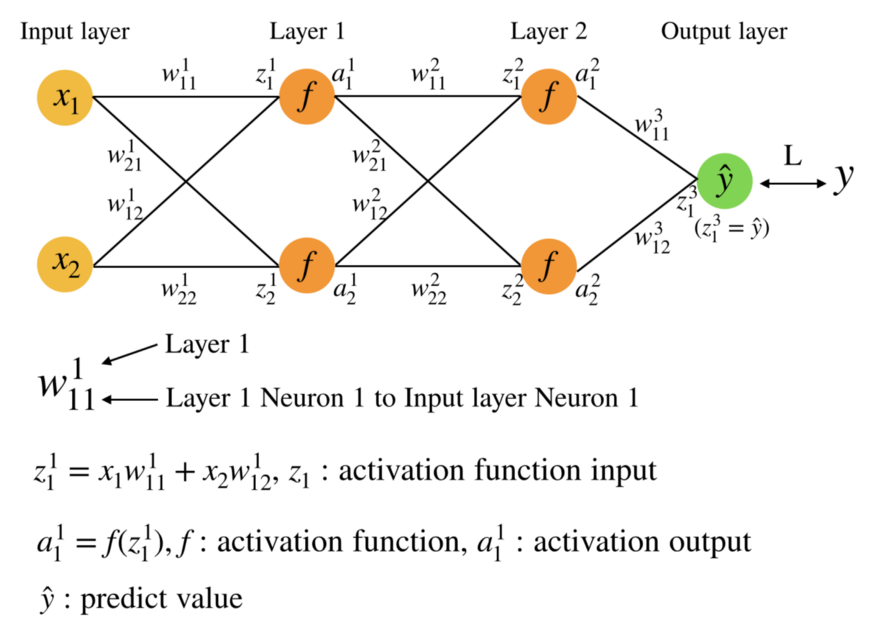
在開始之前,先來介紹一下推導中會使用到的數學符號,這裡以3層NN為例子:
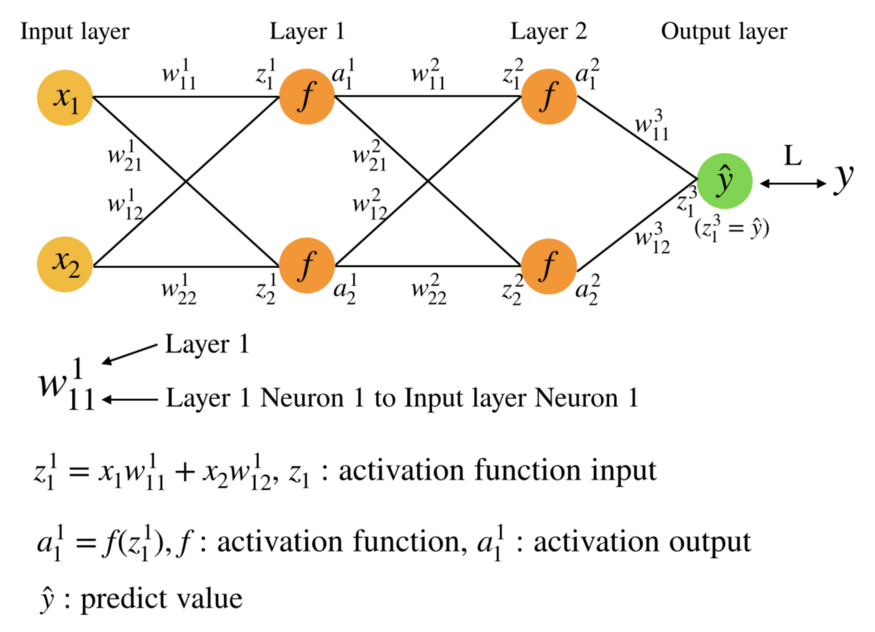
Fig.1
因為Medium的限制,顯示上無法把上標和下標擺在同一個位置。
- W¹₁₁:Fig.1以3層NN(Layer1, Layer2, Output layer)為例,W₁₁¹中上標w¹表示Layer1,下標W₁₁表示Layer1的第一個Neuron連結到Input layer的第一個Input。
- z¹₁:上標z¹表示Layer1,下標z₁表示Layer1的第一個Neuron,z¹₁表示第一層activation function的輸入(z¹₁=x₁w¹₁₁+x₂w¹₁₂)。
- a¹₁:上下標意義與z¹₁同義,差別這個是activation function的輸出(a¹₁=f(z¹₁))。
以上是3層NN的運作方式,若是更深且更多Neuron的NN模型想當然爾也容易想像。
Operation
接下來介紹BP中會使用到的原理與公式:

Fig.2
- Chain rule:中文又稱連鎖率,可以說是BP的核心,主要是在探討複合函數𝑔○𝑓(𝑥)、𝑓(𝑔(𝑡),h(𝑡))中,透過微分,了解變數對於輸出的影響程度。
- Loss function:量測模型預測與標籤之間的距離公式,為了後面推導方便,這裡使用最簡單的MSE,其中分母多乘上2的目的是為了微分方便。
- Sigmoid function:這是其中一種常用的activation function。
- Derivative:這裡以sigmoid的微分為例子,這也是為了後面推導方便。
Back-Propagation
這裡一樣以3層迴歸NN為例子,這邊用w¹₁₁的梯度下降為範例,其餘參數的更新方式依樣畫葫蘆,只是乘多乘少而已,順序關係可以歸納為以下:
𝑥 → 𝑧→ 𝑎→ 𝑧 → 𝑎 → …
𝑥與𝑧之間的關係是權重,𝑧與𝑎之間的關係是activation function的輸入與輸出。
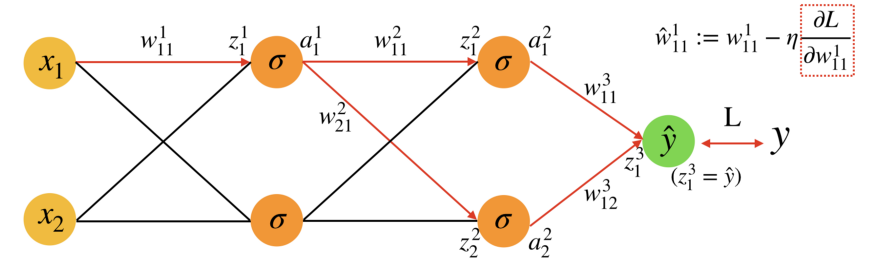
Fig.3
以Fig.3而言,我們現在想要知道w¹₁₁的Gradient(上圖右上紅虛框),然後使用這個Gradient搭配Learning rate進行Gradient Descent(整個式子),而在NN中,紅色箭頭表示w¹₁₁之後會影響到的路徑,這些路徑給了我們一點方向,w¹₁₁只能透過這些路徑影響Loss,也就是說,Loss也只能透過這些路徑影響w¹₁₁,我們有了這個想法後,使用chain rule來把這些路徑展開。
Fig.4
Fig.4是計算w¹₁₁的Gradient,這裡將式子分成3個部分(1., 2., 3.)討論, 1~3的順序關係可以想成從output layer慢慢往Input layer移動:
- 對於z³₁的微分:因為是迴歸問題,所以z³₁就是輸出值,而對MSE中的輸出值進行微分得到上式。
- 這個部分會看到∑這個符號,這是因為w¹₁₁會影響到兩條路徑,可以搭配Fig.3來看,分別影響到Layer2的第一個Neuron和第二個Neuron,而這裡以上面的Neuron a²₁為例子進行微分,微分後發現其實就是Layer3的權重w³₁₁。
- 接下來是對z²₁進行微分,z與a之間的關係就是activation function,對z微分就是對activation function進行微分。
介紹到這裡,以上面的規則,相信讀者已經可以套用到其餘所有的權重w,這裡作者將其餘的推導結果全部列出來:
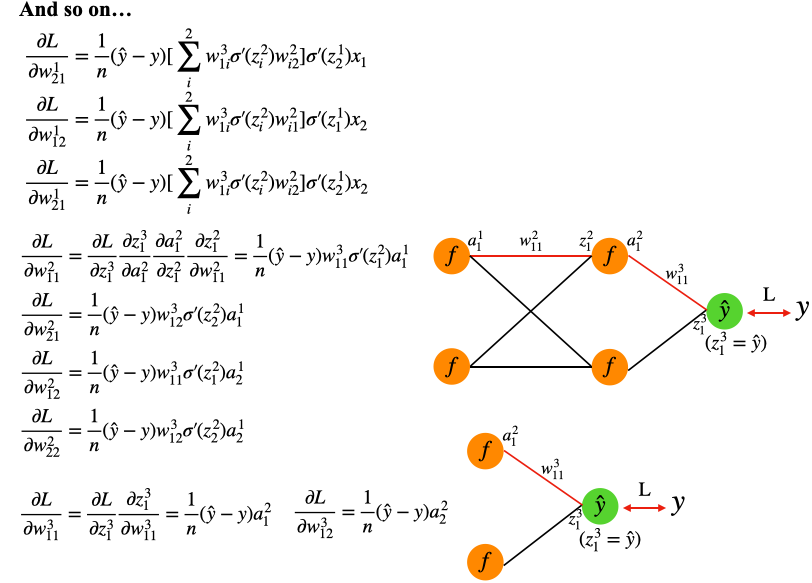
Fig.5
相信各位一定會觀察到這些權重的Gradient展開式有不少重複計算的地方 ,以Fig.6為例,同時連結到Layer1的第一個Neuron的權重有兩個,而這兩個的Gradient就有87%相似的地方,不同只有最後的x₁與x₂,我們可以利用這個關係,歸納之後計算Gradient的規則:

Fig.6
Gradient Problem
我們有了Gradient的公式後,接下來探討NN中常見的問題,Gradient Vanishing與Exploding:

Fig.7
拿w¹₁₁來討論影響Gradient的因素,分成3個部分:
- (Prediction-Label):預測值減掉標籤值,基本上這一項對於Gradient不會有太大的影響,他只會出現在第一項,之後就不會再出現了。
- w:即網路權重,這個取決於你的初始化權重,常見的初始化策略例如:Normal、Uniform、Truncated_norm等等,有許多論文在探討初始化方式,這時的w是由上一次更新後的w所決定,所以只要在初始化時設定的妥當,就不會有什麼問題,而且之後若正常更新,這個w是可以自由變化的,不會受限於最大最小值。
- σ’(z):即activation function的微分,這項是為什麼會發生Gradient Vanishing的原因,若activation function是sigmoid,則微分後如Fig.7右下圖,微分後的上限只有0.25,以這3層NN而言,對於w¹₁₁的Gradient我就需要乘上2個σ’(z)(0.2⁵²=0.0625),整個Gradient就被強制減少將近9成5的值,何況是動輒多層的NN,那計算後的Gradient一定更小,這也是為什麼會使用Sigmoid function發生Gradient vanishing的原因。
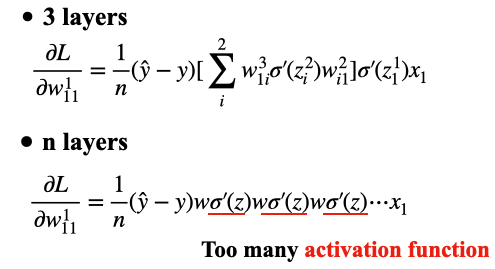
Fig.8
到這裡,相信各位已經理解梯度消失的原因,而目前梯度消失解決方式有幾個:
- Activation function改用Relu (微分後只有0,1,不容易發生梯度消失)
- 搭配ResNet和Batch normalization(BN)服用
- NN不要那麼深
- 試試看其餘機器學習方法(視任務而定)
在2019/1有發表一篇論文探討透過特殊的初始化策略可以建立一個超深的NN模型,捨棄傳統的NN在中間穿插BN的方式,透過名為`Fixup`的初始化方式來達成,有興趣的可以看看。
到這裡,我們了解到Gradient Vanishing發生的原因,那Gradient Exploding呢? 在DNN中,Gradient Exploding會發生的原因通常是初始化權重w設置的不好,這會導致越靠近Input layer的權重變化越大,進而發生Gradient Exploding的現象,目前鮮少有人討論Gradient Exploding,因為這個問題可以用比較粗暴的方式來解決,如下:
tf.clip_by_value(gradient, 1, -1)
上式用白話來講,若gradient大於1,就令為1,若小於-1,就令為-1,透過這簡單的想法防止梯度爆炸。
Conclusion
在本文中主要介紹NN的BP的原理,以這個方向延伸出許多研究如何使梯度更自然的更新,盡量讓梯度不受到函數的限制。當然DNN是所有NN中最基礎的模型,之後還有RNN、CNN的延伸,之後會找時間來寫BPTT。
本文授權轉載自 MetAI / 原文刊登於:Back-propagation




