
2021 年 11 月 Samsung AI Center 提出一篇做圖像修復 (Inpainting) 的論文,這裡的圖像修復指的是重建圖像中丟失或損壞的部分,讓我們先來看看模型驚人的效果。
下面左圖藍色遮罩 (Mask) 是想要去除並重建的地方,右圖是模型修復後的結果,第一排將人物與地上的物件遮住並修復,修復後的車庫門看不出任何瑕疵;第二排將部分建築物, 路樹以及車輛遮住並修復,修復後的圖片看起來非常自然。(除了建築物入口處有一點變形)

模型架構
模型 Large Mask Inpainting (LaMa) 整體架構如下圖:

首先我們搞清楚模型的輸入與輸出:
- 模型的輸入為一張圖片 x′ ,產生公式為 x′ = stack(x ⊙ m, m)
- x: 原圖, m: 遮罩, ⊙: element-wise multiplication
stack: 將原圖與遮罩疊在一起 channel 為 4 (RGB+1),其中遮罩由 Mask Generator 產生,這裡作者強調要使用超過一半以上 (p>=50%) 的遮罩訓練出來的模型效果比較好,也就是下圖中的 Large masks wide 以及 Large masks box。

通過模型 Inpainting Network f_θ 後,輸出為修復後的圖片 \hat{x}。
Inpainting Network
由三個模塊組成: Downscale, Fast Fourier Conv Residual Block 以及 Upscale。
以下三個模塊名稱對應官方 Github 上的程式碼,有興趣的讀者可以點進去對照。
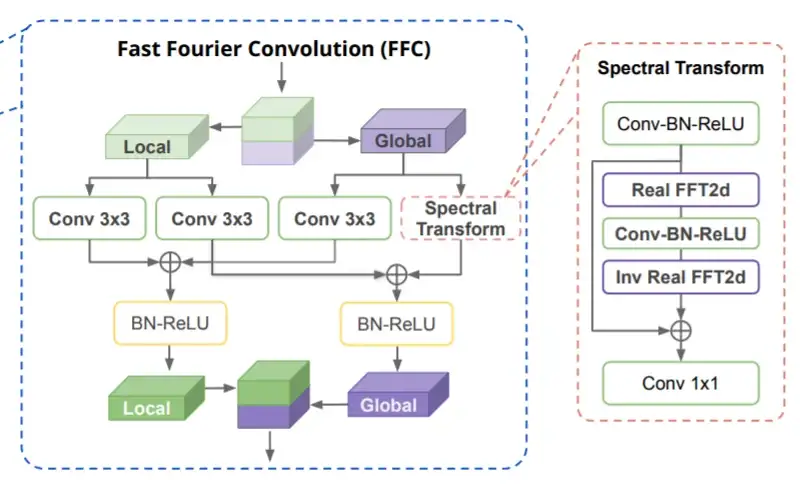
Local X^l 以及 Global X^g 接下來會透過下式將局部特徵與全局特徵組合再一起,這邊的加法對應上圖 4 中的⊕符號,f_l, f_{l → g} 以及 f_{g → l} 對應圖 4 中由左至右三個 Conv 3×3,f_g 對應 Spectral Transform,Spectral Transform 中首先使用了 FFT2d (傅立葉卷積) 萃取特徵圖中的高低頻譜圖,接著對高低頻譜圖進行卷積,接著再接 Inv FFT2d 返回原始維度。

許多讀者可能會疑問,傅立葉轉換結果含有虛部該如何處理,這邊常見的做法會將實部與虛部的數字部分拆開來組成新的維度,例如一複數 a+bi 維度為 (1,),數字部分拿出來重組變成 [a,b],維度為 (2, ),接著只對 [a,b] 進行卷積即可。這也是這篇論文的做法。在論文中有提供 Spectral Transform 中每一層的維度變化,幫助讀者了解操作順序,以下四個步驟其實就是 Fast Fourier Conv Residual Block (FFC) 的做法:
【步驟一】
Spectral Transform 輸入為特徵圖 ℝ∈H×W×C,經過 FFT2d 後輸出為 ℂ∈H×W/2×C,W 會變成 W/2 的原因在於 FFT2d,傅立葉轉換具有共軛對稱的性質,所以只保留前半部分的複數即可。透過這個操作一次萃取出特徵圖中的高低頻頻譜 (Spectrum)。

【步驟二】
因為複數無法進行 Conv2d 卷積,所以這裡將實部與虛部的數字部分拆開來重組。從 ℂ∈H×W/2×C 重組成 ℝ∈H×W/2×2C。

【步驟三】
有了圖 7. 輸出後,就能夠在頻譜上進行卷積 Conv2d,卷積後得到一樣維度的輸出。

【步驟四】
卷積後將 2C 維度重組回複數型態 (RealToComplex),接著再使用 Inverse Real FFT2d 進行還原。
最後再將 Y^l 與 Y^g 各自通過 BN+ReLU,再 CONCAT 在一起即可。
Loss function
這篇論文使用的損失函數公式如下,由最終 𝔏_final 由四種 Loss 組成:

- 𝔏_Adv: 這是標準的 Adversarial loss,又由兩個部分組成: 𝔏_Adv=𝔏_D+𝔏_G,𝔏_D 為 Discriminator Loss,負責判斷 Generator 產生的圖片是否為真 (即 LaMa 產生的圖片),所以這邊作者又另外使用一個網路來判斷 LaMa 產生的圖片是否為真;𝔏_G 為 Generator Loss,就是 LaMa 模型本身,負責產生逼真的圖片騙過 Discriminator。
- 𝔏_HRFPL: 稱為 High Receptive Field Perceptual loss,針對這個 Loss 作者有如下說明。我認為作者的意思在於不用過於強求模型要生成跟原圖一模一樣的圖片,因為有時候遮住的部分不管要怎麼修復其實都是假的,只要夠逼真即可,所以這個 Loss 在追求的是圖片整體的協調感。𝔏_HRFPL 公式如圖11.,其中 ϕ_HRF 可以是任意的卷積層,將原圖 x 與預測圖 \hat{x} 通過 ϕ_HRF 得到各自的特徵圖,然後再相減取平均 𝔪 即可。

However, the visible parts of the image often do not contain enough information for the exact reconstruction of the masked part. Therefore, using naive supervision leads to blurry results due to the averaging of multiple plausible modes of the inpainted content.It does not require an exact reconstruction, allowing for variations in the reconstructed image.
- 𝔏_DiscPL: 這個 Loss 源自於 High-resolution image synthesis and semantic manipulation with conditional gans ,作者提到這個 Loss 對於穩定訓練過程起到很大的作用。
- R₁: Gradient penalty 公式如圖12.,我認為主要是防止 Discriminator 太過嚴格,因為當遮罩面積太大時,生成的圖片不可能跟原圖一模一樣。

Evaluation
接下來看看模型圖像修復的表現,下圖左一為原圖,藍區塊是遮罩,LaMa-Regular 是不使用 FFC,LaMa-Fourier 是使用 FFC,CoModGAN 以及 MADF 分別是過去兩種模型。第一排大樓部分 LaMa-Fourier 有很好地將大樓窗戶還原;第二排將人物去除,LaMa-Fourier 同時將長椅以及鐵絲網都很好地還原回來,尤其是鐵絲網這種非常細節的部份也能修復的如此完美。

接下來比較不同 Resolution 的修復效果,當 Resolution 較低為 640×512 時,所有模型的修復效果都沒有太大的差異,當 Resolution 提高至 1920×1536 時差異就出來了,依然是 LaMa-Fourier 表現最好,將模型餐數量從 27M 提高至 51M 後效果變得更好!

Demo
論文作者也提供線上Demo供大家測試效果,操作方式如下動畫,上傳一張圖片,並塗上想要修復的區域就會開始修復!下方展示將人群從圖片中去除並修復,可以看到 LaMa 的效果強大無比。
References:
論文連結:https://arxiv.org/abs/2109.07161
Github:https://reurl.cc/33WlYM
本文授權轉載自宇見智能 / 原文刊登於:LaMa:Resolution-robust Large Mask Inpainting with Fourier Convolutions




