
幾乎所有的語言分析應用場景的先決條件就是「數據量要大,愈大愈準」。但如果某個專業領域裡面只有寥寥數篇相關文件,例如新產品的行銷文案、專業技能的訓練課程講稿內容乃至候選人的政見發表或是辯論文字稿…等。我們有什麼辦法能讓「人工智慧」幫我們透過少量的數據,就做出像人的判斷呢?
語意分析在近年的大數據與機器學習乃至深度學習的潮流下,已成為人工智慧在自然語言處理以及輿情分析的標準應用。但由於工具原理的限制,語意分析的結果往往會用一個詞頻分佈圖、關鍵字的文字雲…等方式呈現。要讀懂究竟這張圖表的意義,還需要一個「分析師」像解盤股市表現一樣地說明各個指數的意義,才能讓人一窺目標市場不經間透過文字或語言留下的思緒痕跡或是情緒傾向。
這幾乎讓「語意分析」一詞聽起來就像是某種星座算命用的神秘詞彙。
另一個和星座算命類似的性質是,幾乎所有的語言分析應用場景的先決條件就是「數據量要大,愈大愈準」。但如果某個專業領域裡面只有寥寥數篇相關文件,例如新產品的行銷文案、專業技能的訓練課程講稿內容乃至候選人的政見發表或是辯論文字稿…等。
這些文件少則只有一篇,多也不過是在幾十篇而已,如何在最短的時間裡利用語意分析來評估文本內容的品質好壞,或是計算它的關鍵詞彙以便做延伸的搜尋或領域研究呢?數量不夠的話,是沒辦法採用大數據的人工智慧方法的。
但是相較於需要大數據的人工智慧,幾乎任何一個心智正常的經理人,都能只憑少少的幾篇文字,就做出準確的商業判斷「這個人是否言過其實?」、「這個報告是否用心製作?」、「這個伙伴的計劃是否值得信任?」那麼,問題來了…
為什麼我們不能讓「人工智慧」來幫我們透過少量的數據,就做出像人的判斷呢?
這是因為,大數據條件下的人工智慧運作的方式,和人類做邏輯判斷的方式不太一樣。人類的語言能力,能讓我們透過極少的資料,就感知到一個句子是屬於「有料」或是「沒料」。
以前幾年流行的「語言癌」為例。聯經出版社邀集了國內的語言學家精英,從語法、功能、歷史、結構…等等角度做出了四平八穩的結論,但就是忽略解釋了「一般人聽到:『做了一個擁抱的動作』時,那股冗贅的不適感從何而來呢?」
同樣的道理,在近年來部份心靈導師的訓練課程中或是一年多以來的總統選舉活動中,也有許多發言內容常讓人覺得「你的確講了很多話,但我總覺得只接收到很少的資訊」。
這種「資訊」和「收訊」之間的落差感,是否有個科學的解釋呢?
這個問題,致力於將「語言學」領域的先驗知識帶進語意分析以及其它自然語言處理任務的卓騰語言科技有解決方案。卓騰語言科技並不是世界上第一家將語言學知識引入語言分析任務,因而大幅縮小數據量需求的公司。在國外,幾乎和我們同時成立的 Bitext 也是一家利用語言學背景打造各種能大符提升機器學習模型正確率表現的的跨國企業。差別只在 Bitext 專精於歐美語系,而卓騰語言科技則主攻亞洲的語系。
以往在數據量大的時候,我們就能基於統計方法,先將一篇中文文章進行中文斷詞處理以後,計算這篇文章和其它文章最具代表性的「關鍵字」,或是計算每個詞條的出現的次數,以「詞頻」做為語意分析時的素材。
用料理做為類比,可能更好理解。民以食為天,您一定曾經有過明明點了一道名稱很長,好像用了許多食材,似乎很厲害的料理以後,嚐了一口卻只是平平淡淡的沒什麼滋味。這種「名稱很長」和「淡淡的沒什麼味道」之間的落差,該怎麼計算呢?
如果要採用機器學習的話,它會需要「許多菜單的樣本」以及「食用後的客戶意見」來建立「餐點名稱的長度或內含字彙」以及「客戶意見」之間的關係以後,在您看到一個新的菜色時,系統再依這道菜色的「名稱長度或內含字彙」來給您「它是味道豐富」或是「它可能平淡無味」的預測。
但如果這個問題交給一個「具有專業領域知識的廚師」的話,他根本不需要吃過多少菜,就可以依據他對每一道食材以及料理方式的知識,看著菜名,就告訴你「這道菜名字很長,但大概沒什麼味道,因為食材都是些小白菜、豆芽菜、豆腐…等東西,而且料理的方式也不容易入味」。
- 樣本多時,您可以採用機器學習的 AI 方法,
- 樣本少的時候,不妨利用廚師的專業知識。
我們提供的,就是基於「對語言的專業知識」而打造的演算法。以語言癌的句子「做了一個擁抱的動作」為例,其實它的意思就是「擁抱」。那麼我們能否「讓電腦計算」這個語言癌句子的「空洞感」從何而來呢?我們將句子送入卓騰語言科技的「Articut 斷詞引擎」以 lv1 計算,並代入「名詞、動詞的詞彙數量除以整個句子的詞彙數量」這個公式來計算兩個句子:
公式:(Noun + Verb) / All
- 做了一個擁抱的動作 =>
- 做(verb) 了(ASPECT) 一個(classifier) 擁抱(verb) 的(FUNC) 動作(nouny)
斷詞處理後共有 6 個詞 (做/了/一個/擁抱/的/動作),其中動詞有 2 個 (做/擁抱),而名詞有 1 個 (動作),依公式計算得:(2+1)/6 = 0.5
也就是說,整句「做了一個擁抱的動作」裡,只帶了 50% 的資訊。這麼一來,當然會讓聽者覺得有一種「餐點名稱很長很厲害,結果嚐起來沒什麼味道」的空洞感了。
這個公式並不是我們發明的,而是在歐美語系的語意分析工作中已經有悠久應用歷史以及為了不同的場景,也有許多不同版本的變體。但以往幾乎不曾在「中文語意分析」中看到這種方法,主要的原因還是在 Articut 斷詞引擎出現以前,常見的中文斷詞方案有的是詞性標記錯誤過多以致無法使用 (例如 Jieba 結巴斷詞),再不然就是詞性標記分類過細以致於操作複雜。
同樣公式,我們在本屆總統大選的第一次政見發表會中也加以應用 [註]。這是一個教科書式的完美應用場景。三位候選人的發表時間是一致的,我們不用擔心是否像對話一樣,每個人的句子有長有短讓公式中的分母差異過大。三個人的發言主要都是在單方向的「說明」而不是雙向或是多向的「對話」,如此一來可以更確定發言時所用的詞彙是自己的意思,而不是在重覆對方問題時說的話。
把三位候選人的政見內容,送入 Articut 進行斷詞處理後,計算詞彙總數,並另外計算了名詞和動詞的數量,依前述公式計算後得到以下的圖表分佈:
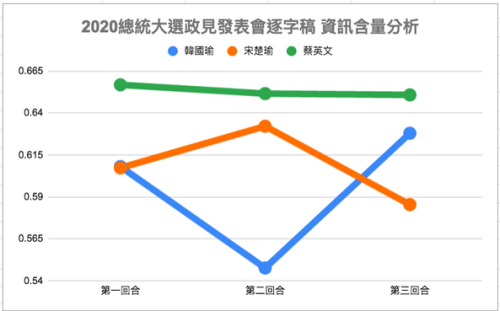
這個圖表的數字分佈,剛好符合了閱讀逐字稿以後網友的主流意見:「其中一位候選人似乎都在講空話」。現在我們有了 Articut 斷詞引擎的 POS 標記以後,終於能跟上歐美行之有年的語意分析技術水準,將「網友主觀的感覺」以「客觀量化數據」呈現。
透過小數據條件的語意分析技術,我們可在演講稿完成的同時,就進行計算;而不需要等到演講稿發佈以後,再從網路蒐集網友意見,進行後續的分析操作。
我們可以用同樣的公式,現場進行一個實驗。以下有兩段健身房的文案,一段比較沒有吸引力,另一段則充滿節奏。我們將文字透過 Articut 斷詞引擎處理後,再來看看您的感受:
文案一:25歲以後肌肉就會慢慢流失,只有透過不斷的訓練才能讓肌肉流失的速度變慢,並且在老了以後保有堅硬的骨骼。
文案二:25歲以後肌肉開始流失,唯有訓練才能減緩肌肉流失速度,同時保有堅硬的骨骼。
讀者可先自行判定,哪一個文案的文筆較佳。再往下看看,閱讀時的感受是否和計算出來的「資訊密度」表現一致?
文案一:
25歲(Noun) 以後(TIME) 肌肉(Noun) 就(FUNC) 會(MODAL) 慢慢(MODIFIER) 流失(verb),只有(MODIFIER) 透過(verb) 不斷(MODIFIER) 的(FUNC_inner) 訓練(Noun) 才能(MODAL) 讓(verb) 肌肉(Noun) 流失(verb) 的(FUNC) 速度(Noun) 變(verb) 慢(MODIFIER),並且(FUNC) 在(ASPECT) 老了(verb) 以後(TIME) 保有(verb) 堅硬(MODIFIER) 的(FUNC) 骨骼(Noun)
共 28 個詞,其中的名詞及動詞共 13 個 (標為淡黃色)。資訊密度為:13/28 = 0.46
文案二:
25歲(Noun) 以後(TIME) 肌肉(Noun) 開始(verb) 流失(verb),唯(MODIFIER) 有(verb) 訓練(Noun) 才能(MODAL) 減緩(verb) 肌肉(Noun) 流失(verb) 速度(Noun) 同時(TIME) 保有(verb) 堅硬(MODIFIER) 的(FUNC) 骨骼(Noun)
共 18 個詞,其中的名詞及動詞共 12 個 (標為淡黃色)。資訊密度為:12/18 = 0.67
透過這個計算公式,我們也能發現資訊密度高的文案,通常也避免了「誇張賣弄」、「行話」、「囉嗦」、「討論自己」、「過度興奮」或「主觀強烈」…等行銷文案的地雷。因為誇張賣弄、過度興奮或是主觀強烈多半是透過形容詞來呈現。但在這個公式裡的形容詞不計分;行話和囉嗦的詞彙容易被斷詞引擎處理錯誤而失分;此外,談論自己時用的代名詞一樣是不計分的。
利用 Articut 斷詞引擎的詞性標記,計算資訊密度最少最少只需要「一個句子」。從此以後,我們便能利用這個公式掌握了「小數據」條件下的語意分析能力。
小數據的語意分析可強化大數據的機器學習效果
這兩種技術在本質上並不衝突,因此您可以輕易地將兩者融合成為新的產品或是決策輔助工具。在突發事件或是可掌握的資料不多時,採用小數據的語意分析方式,在累積了足夠呈現統計意義的資料量後,再採用大數據的機器學習方法挖掘更多潛在的趨勢。或是再次結合小數據方法,從不同的面向觀察長時間的語意分析變化,掌握市場伏流的動向。
註:我們略過了第二次政見發表會的原因是第二次政見發表會在形式上是單方的發表會,但實際上三個回合已經形成了類似辯論的對話模式。這應該要採用其它的變體加以計算。
原文刊登於:卓騰語言科技 - 科普分享空間(小數據條件下的語意分析)




