
在資料科學或是機器學習上,資料特徵的取得一直都是非常重要的議題, 若能選擇到好的特徵,即使是非常簡單的模型都可以有好的預測或分類效果。比如說在預測體脂肪率的過程中,選擇用「體重」當特徵來預測體脂 肪顯然會比選擇用「擁有的手機品牌」來預測體脂肪的準確度高。然而在收集原始數據 (raw data)時,往往會將有用和無用的資訊都收集進資料庫,這時候若採用到錯誤特徵或是不合適的特徵就可能造成模型效能不佳的問題出現。
上述範例用「擁有的手機品牌」來預測體脂肪就屬於錯誤特徵,而用「體 重」來預測體脂肪就非常合適,所以「體重」對於此任務就是高價值特徵,而「擁有的手機品牌」就是低價值特徵。但高價值的特徵有時候卻是不合適的特徵,本身雖然是高價值特徵,但卻非常難取得,例如水底測量法可以得到較合適的體脂肪估計特徵,但要將整個人泡到水裡量測水中和平地重量的差異,這個方式就非常難做到,因此用水底量測法得到的差異量當作體脂肪估計的特徵就非常不合適。
當我們假設資料是已經收集完成的狀況,不合適的資料通常只會發生在某些特徵資料遺失、收集不完全,這時候可以靠一些手法,例如用中位數取代或是眾數取代遺失的資料或是直接捨去此特徵。
從資料科學的觀點來說,資料科學著重在解釋特徵的選擇,為何這些特徵對於模型效能能有提升的幫助,好的特徵能夠幫助了解資料特性和結構,可以進一步分析背後的資料特性和特點。
而研究者最常採用的特徵選擇方式往往是採用主觀選擇,但主觀選擇的特徵也許並非模型的重要特徵。另外,原始數據的收集有時候會多達上千或是上萬個特徵,也很難由主觀的方式選擇重要的特徵,因此大數據資料驅動(data-driven approach)的精神,就是直接從數據中探索挖掘數據背後真正的寶藏。
特徵數過多的問題
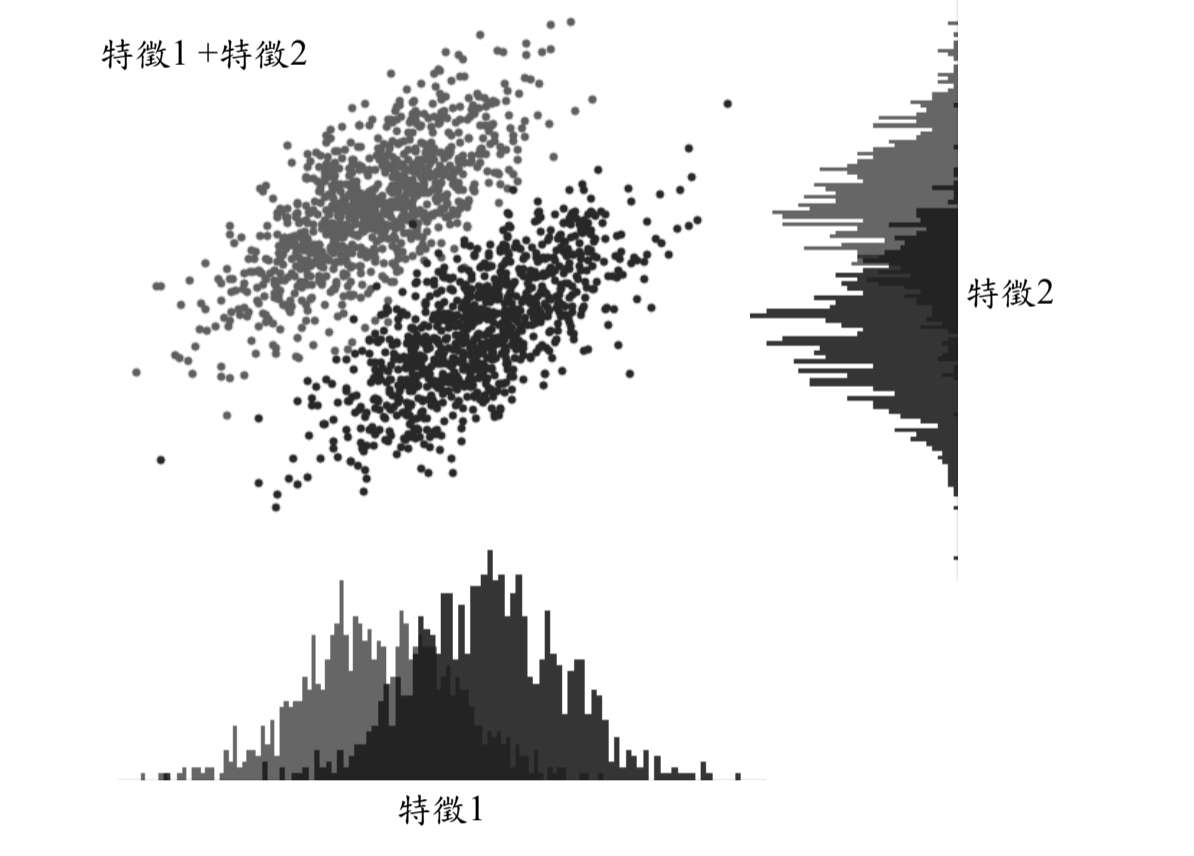
從機器學習觀點來說,模型採用的特徵數越多,進行分類問題時資料的分 散量就越好,對於模型的預測分類成效就越高,往往在單一特徵上無法有效分類為兩個不同類別(下圖特徵 1 和特徵 2 都無法單獨將分類任務做得很 好),但兩個特徵組合起來就能明顯區隔兩類別。
但特徵數也非無上限的去收集,因為在建立預測模型時,容易因為特徵數大於資料樣本數造成模型參數估計錯誤,導致模型無法有效進行預測,在機器學習稱此現象為「休斯現象(Hughes phenomenon)」,也稱為「維度詛咒(Curse of dimensionality)」,見下圖:
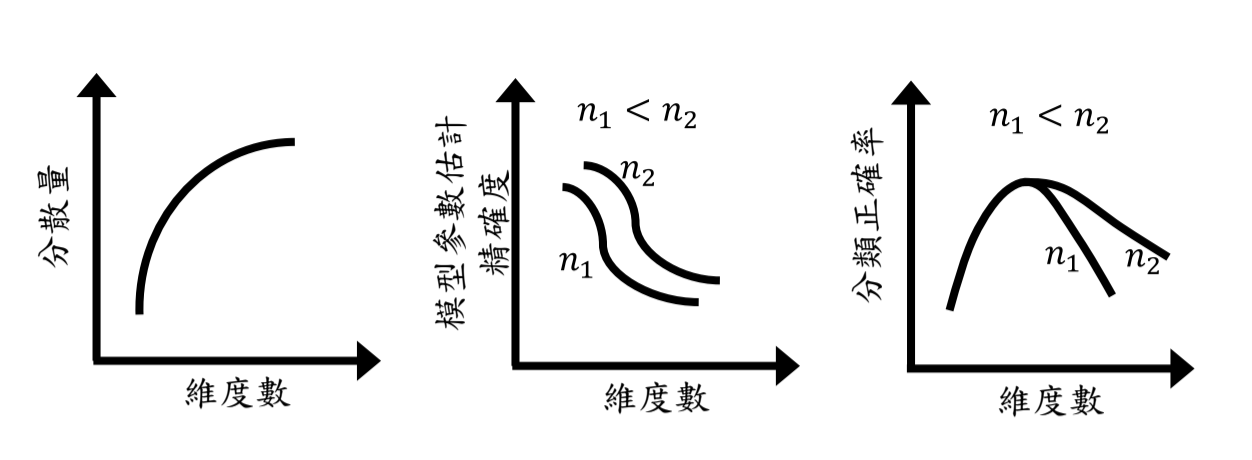
當樣本的特徵數越多,可採用的維度數就越高,理論上維度數越高則不同類別之間的分散量越高(上左圖),同時統計估計的準確率就會變差。相對的維度數越高,模型參數估計精確度就會隨著維度數上升慢慢下降(上中圖)。
當資料樣本數 (n2)越高則參數的估計精準度就會比樣本數少 (n1)來的準確。分類也會隨著維度提高而得到更好的分類正確率(上右圖的上升段), 但若達到最好的分類正確率後繼續提高維度,會因為參數估計的精準度變差,使得分類的正確率開始下滑(上右圖下降段),此問題會因為樣本數的增加慢慢被消弭。理論上 n 趨近無窮大時此問題可被忽略,但實務上 n 不可能趨近無窮大,所以需要一些特徵降維的手法。
由上面簡單的舉例,讀者應該比較有概念,在進行資料分析和統計建模分析第一件事情是至少樣本數要大於特徵數(維度數),若資料數無法大於特徵數,則需要進行本章後面要介紹的統計資料降維。統計資料降維方式可將屬性分成「特徵選取 (Feature Selection)」和「特徵萃取 (Feature extraction)」,以下我們會介紹這兩類常用來降維度的基本方法。
特徵選取法
特徵選取法(feature selection)的目的是希望從原有的特徵中挑選出最合適的特徵,使其預測率或是辨識率能夠達到最高,這些具有鑑別力的特徵資 料可以簡化建模過程的運算和參數量,也可以幫助我們探討資料特徵和任務之間的關聯。例如下圖我們有 6 種收集到的特徵資料,任務是進行性別分類(男生和女生的區隔),這時候特徵選取則是希望從這 6 個特徵選到最適合分類任務的特徵。
最理想的狀況是利用窮舉法(暴力法)把所有組合都考慮過一輪,然後建立出所有模型,從訓練資料和測試資料的結果來挑選最合適的特徵。此範例中包括 6 個特徵資料,則需要考慮到 6 2 1 64 1 63 −= −= 個特徵組合,然後比較訓練資料選出最合適的特徵組合。看起來也還好才 63 組,感覺電腦也是一下就處理結束,但當我們的特徵資料多達 100 個,這時候我們需要窮舉出 100 2 1 − 組特徵組合,因此不太可能採用窮舉的方式來處理,所以會有一些常用的特徵選取方法。
本文節錄自《機器學習的統計基礎:深度學習背後的核心技術》,由旗標科技授權轉載。




