
自 ChatGPT 推出至今,不少企業也開始嘗試將生成式 AI 模型應用於改善工作效率或提供客戶服務。然而,這類大型語言模型的部署並不容易,隨著模型規模的增長,儲存和計算需求也相對提高。例如:以GPT-175模型需要約350GB的儲存空間(Floot16 precision),並且在推理和運算時,也需要同等大小的記憶體。若要有效運行模型,至少需要五個A100級別的GPU,其中每個GPU具有80GB的記憶體。顯示大型語言模型在部署時,面臨參數量大、速度慢且計算複雜度高等挑戰。此外,若需要在移動端或邊緣設備上進行多模型部署,更是增加了複雜度。
具有龐大參數量的大型語言模型該如何應用呢?在部署大型語言模型前,需先了解幾個常見的模型壓縮技術。
模型壓縮的精神:保持效果且減少儲存大小
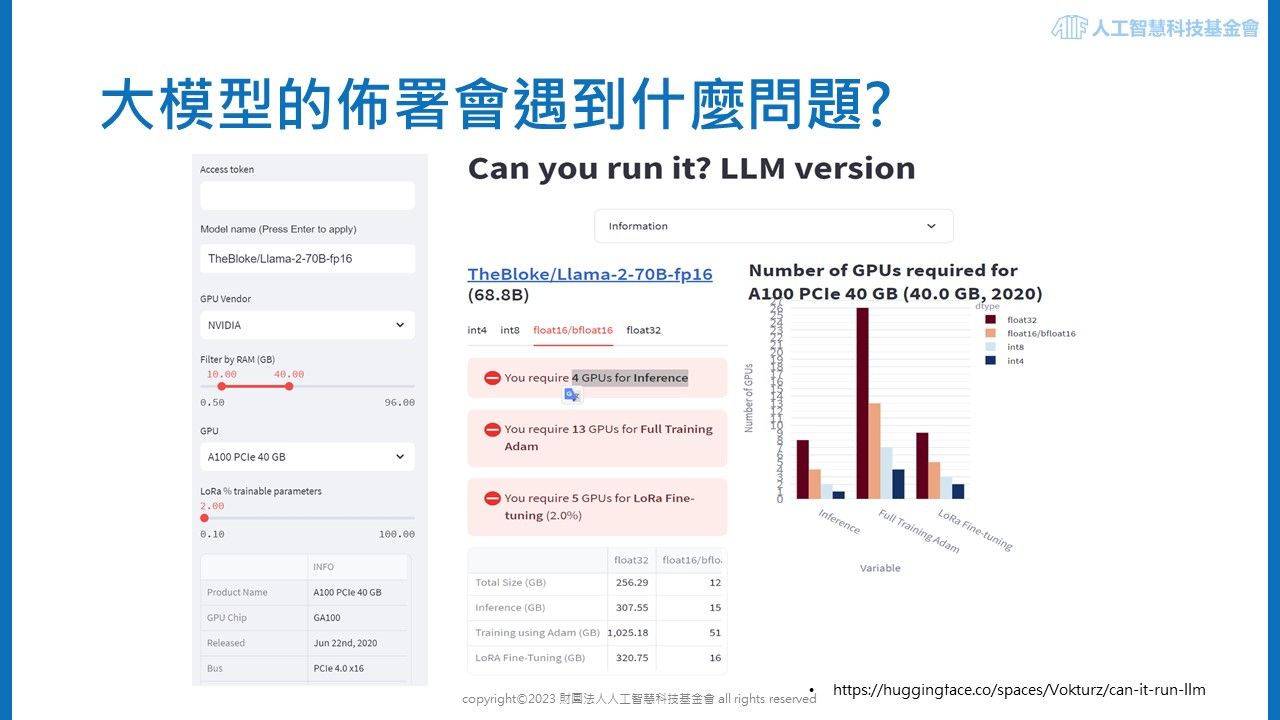
首先,我們需了解模型所需的儲存空間,預估方法有兩種,第一是利用簡易的公式估算,如每X Billion個參數大小的模型(Floot16 precision),約需要2*X GB的記憶體;第二個方法則是透過 Hugging Face 所提供的工具,預估運行特定大型語言模型所需的記憶體空間。如下圖所示,Llama2 為 70(Billion)大小的模型,若使用 Float16 精度,再選擇 A100 級別且 40GB 記憶體 GPU,可以推算需約 4 個 GPU 來進行模型推論,而這僅是部署後的應用,若需要訓練模型,會需要 13 個 GPU 才能完成一次完整的訓練。(因訓練模型所需精度較高所致)
由於大型語言模型龐大規模而衍生的問題,如模型部署的高成本和複雜性。因此,模型壓縮成為了解決這些問題的有效途徑。模型壓縮的精神在於,盡量保持效果的同時減少其儲存大小,使運算或移動效率更高且更加方便。不僅可以降低部署成本,還能為企業提供使用大型語言模型的可能與機會。
三種常見的模型壓縮作法
常見的方法分為以下三種:剪枝法(Parameter Pruning)、量化法(Quantization)、 蒸餾法(Knowledge Distillation)。上述方法多為獨立設計,而在實際應用中也常同時使用,讓模型達到更進一步的壓縮效果。
剪枝法(Parameter Pruning)
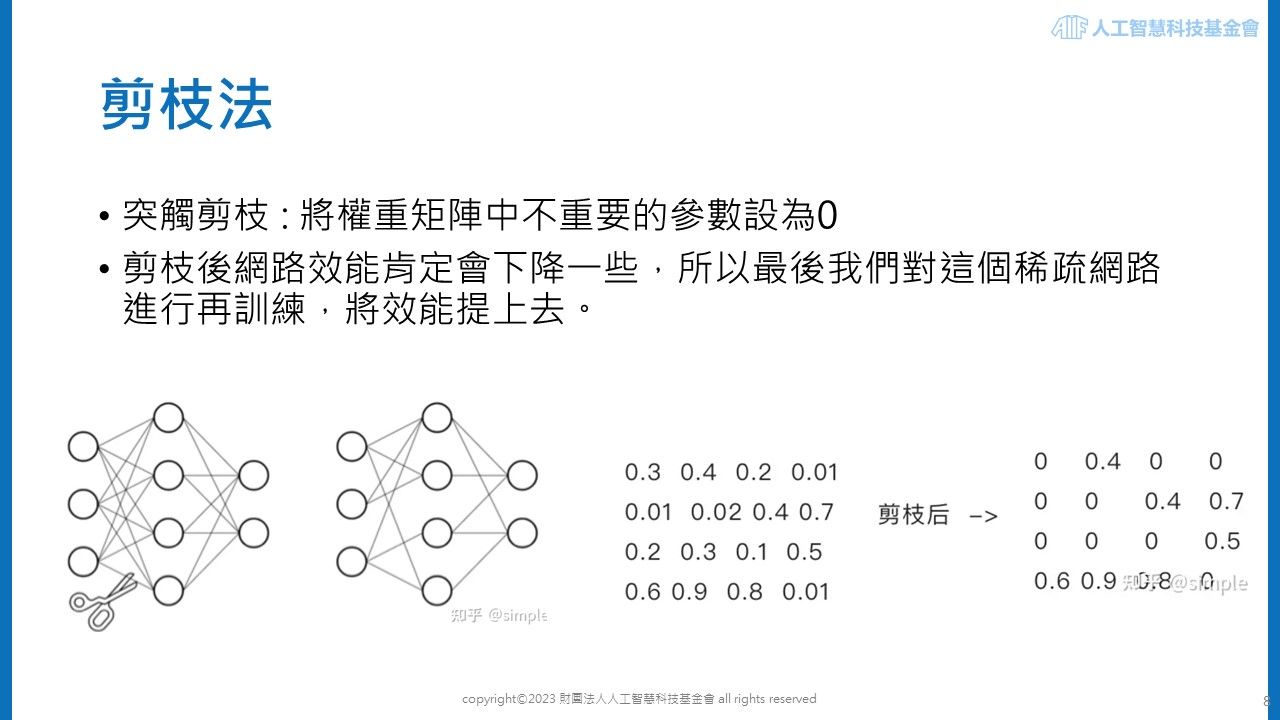
第一個方法為突觸剪枝,此方法能有效減少模型的大小和複雜度,同時保持或僅微幅降低模型的效能。剪枝法的作法是識別並移除神經網路中不必要或重要性較低的參數。透過突觸剪枝,可以將神經網路中權重較不重要的部分設為零。這種方法的關鍵在於判斷哪些權重是「不重要的」。在剪枝過程中,一些神經元的連結會被刪除,從而簡化網路結構。雖然這可能會導致網路效能略有下降,但透過後續的重新訓練,可以恢復或甚至提升模型的效能。
以下圖所示,從原始模型(左下)中對權重較小的參數進行剪枝,可以看到神經元之間的連結變得較少。在實際運算過程中,模型權重的矩陣會有相應的改變,即那些被剪枝的權重在矩陣中被設定為零。這不僅減輕了存儲和運算負擔,也使模型更加高效。
另一種剪枝方法是神經元剪枝,這涉及移除神經元,而不僅是單個權重的剪枝。此方法是將神經網路中某些神經元將被完全去除,相當於在權重矩陣中將對應的某一行和某一列設為零。此方法通常涉及對神經元的重要性進行排序,並剪除重要性最低的神經元。常見的做法是計算每個神經元的輸入權重和輸出權重的平方和的根,根據此指標對神經元進行排序,剪除重要性排名最低且一定比例的神經元。
這些剪枝方法對於部署大型語言模型至關重要,尤其是在資源受限的環境中。透過減少模型的大小和計算需求,使在小型硬件設備運行大型語言模型的應用範圍。
量化法(Quantization)
量化法是將表示模型參數的浮點數,轉換為整數或其他離散形式,以達成減低儲存空間的目標,意味著儲存單一權重所需的空間大幅減少,降低模型大小或複雜性。此方法將權重的數值,從大集合映射到較小集合的過程,目標是在轉換過程中將資訊量損失降到最低。雖然會導致一定程度的精度損失,但其重點在於盡可能在精度減小的情況下實現模型壓縮。
量化法已成為一種廣泛接受的技術,且實踐難度不高,運用套件或API即可以串接。傳統模型進行訓練時,是使用32位浮點數(Float32)來表示每個權重,而業界的趨勢已經朝向使用更低位數的模型進行推理,主流的作法是使用8位整數(Int8)參數模型。此外,也有研究探索到4位(4-bits)、3位(3-bits)、2位(2-bits)甚至1位(1-bits)的量化方法。這些更低位數的量化方法,對於資源有限的設備上進行模型部署和運算,提供了更大的靈活性。
知識蒸餾(Knowledge Distillation)
知識蒸餾是一種重要的模型優化技術,它使得我們能夠從一個大型且複雜的「老師模型」轉移知識到一個更小、更高效的「學生模型」中。這一技術的關鍵在於從老師模型提取的所謂「暗知識」(Dark Knowledge),這包括了模型的預測概率分佈以及其他不容易直接觀察到的模型行為特徵。透過知識蒸餾,學生模型在保持體積輕巧的同時,能夠學習到老師模型的核心能力和決策模式。
Google 在 2023 年提出的「逐步蒸餾法」是知識蒸餾領域的一個重要進展。此方法可以在使用更少的訓練數據的情況下,訓練出專門針對特定任務的小型模型。這對於資源有限的應用環境來說是一個極大優勢,因為它降低了模型訓練和部署的成本,同時保持模型效果。
當今的大型語言模型,如GPT和BERT等,雖然功能強大,但它們巨大的參數量,使儲存和運算帶來了不小的挑戰。隨著模型大小的增長速度超過摩爾定律,研究人員投入大量努力於模型壓縮技術的研究。剪枝、量化、知識蒸餾等技術發展,使得大型模型的部署變得更加實用。這些壓縮技術的應用不僅限於降低模型的儲存和運算需求,也為模型的應用帶來了新的可能性。尤其是在移動設備和邊緣計算設備上,使得大型模型也能夠在計算資源受限的環境下有效部署。
隨著技術的進步,可以預見將會開發更加精簡和高效的模型,不僅能夠媲美大型模型的效果,且能更廣泛的出現各式應用場景。這不僅代表技術的進步,也意味著AI將更加普及,為未來技術發展和創新應用開啟更多可能。
想了解更多模型壓縮技術,請參考【AI CAFÉ 線上聽】模型壓縮的量化方式簡介




