
市面上專攻模型實驗平台的套件有非常多,之前曾介紹了如何上傳模型實驗任務,以及快速部署 MLDE 在單一電腦上。本文透過介紹MLDE的系統架構、事前準備、使用 CLI 部署及移除節點,讓讀者可以快速部署客製化的模型實驗平台在 Docker 環境中。
市面上專攻模型實驗平台的套件有非常多,例如系列文(一)介紹的HPE Machine Learning Development Environment (MLDE),該套件主要具有模型實驗紀錄追蹤、分散式訓練加速架構、自動超參數搜索、支援多種模型開發庫(包含TensorFlow、Pytorch、Keras、Hugging Face、MMDetection)的特色,是較為成熟的模型實驗平台套件。
在系列文(一)中介紹了如何上傳模型實驗任務,以及快速部署 MLDE 在單一電腦上。這一次我將手把手帶領大家從頭到尾部署一個客製化的 MLDE 服務在 單/多台電腦的 Docker 環境上,並透過命令列介面(Command-Line Interface,CLI),也就是透過命令提示字元/終端機的指令進行操作。我將分別針對 MLDE 的系統架構、事前準備、使用 CLI 部署節點、使用 CLI 移除節點做介紹,讓讀者可以快速了解 MLDE 的系統組成,並依照自己的需求快速部署、移除自己的模型實驗平台。
系統架構
MLDE的系統架構主要分成兩種節點(Node):Master Node、Agent Node(s)(如圖一),可以部署在Docker、AWS、GCP、Kubernetes等多種環境當中。
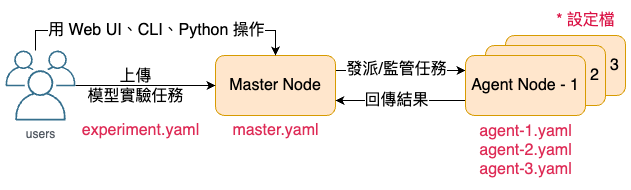
Master Node 負責實驗任務的接收、檢視、發派、控管。使用者們可以將實驗丟給 Master Node,Master Node 會將實驗發派給 Agent Node(s) 運行,並將運行結果整合紀錄。同時,Master Node 具有圖形化介面(Web UI),使用者可以直接使用 Web UI 做操作,抑或是直接透過 CLI、Python 程式碼操作。而如果要部署 Master Node,可以透過一個 yaml 檔進行(如圖一 master.yaml)設定並部署。
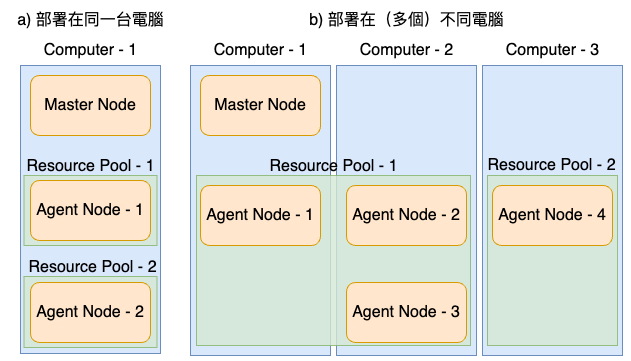
Agent Node(s) 負責實驗任務的執行,主要接受來自 Master Node 發派的實驗任務,可以有多個 Agent Node(s) 負責執行不同的實驗任務。 Agent Nodes 的部署同樣可以透過 yaml 檔(如圖一 agent-1.yaml 、 agent-2.yaml 、 agent-3.yaml)設定各自的 Agent Node,之後在各自進行部署。 Agent Node 的部署位置可以與 Master Node 運行在相同電腦(如圖二 a),也可以在不同電腦(如圖二 b)。
最後還有一個重要的觀念 — 資源池(Resource Pool), Resource Pool 為 Agent Node(s) 的集中池,是一個模型實驗任務可以運用的最大運算資源。Agent Node(s) 在部署時需要指定綁定到哪一個 Resource Pool,將來在上傳模型實驗任務時也需要指定使用哪一個 Resource Pool 的運算資源執行實驗。需要注意的是,Resource Pool 之間的運算資源並不互通,所以分配 Agent Node(s) 到 Resource Pool(s) 時可以利用這個特性做資源的區隔。舉例來說:圖二 a 的 Computer-1 有 兩個 GPU,分別設定成 Agent Node-1 、 Agent Node-2 ,而我因為希望兩個 GPU 各自負責獨立的模型實驗任務,所以分別將兩個 Agent Nodes 指定到不同的 Resource Pool,如此便能避免兩個模型同時在執行模型實驗任務時,互相搶資源導致效能變差。當然實際配置還是要根據團隊的實際需求做考量。
事前準備
MLDE 主要以 Python 編寫,而本文主要部署在 Docker 環境,因此 Docker 、 Python 特定版本都是必備的。除此之外,若需要使用 GPU 的讀者,安裝 CUDA 、 CUDA Driver 、 NVIDIA Container Toolkit 也是必須事前準備好的。更多細節、安裝方式請參考 MLDE 系統要求及套件安裝,並檢查 Docker 是否運行中:
# 在終端機運行
docker ps
# 正常運行時,將至少出現以下內容
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES本文為 Linux 環境,使用的套件版本:Docker==24.0.5、Python==3.10.12、CUDA==12.2、CUDA Driver==535.86.10、NVIDIA Container Toolkit==1.14.0-rc.2
使用 CLI 部署節點
步驟 1 — 若要使用 MLDE CLI ,必須在 Master Node、所有 Agent Node(s) 的電腦上(如圖二 a、圖二 b 中的 computer-1、computer-2、computer-3)先安裝 MLDE 套件:
# 在終端機運行
# 本文的 determined 版本為 0.25.0
pip install determined
步驟 2 — 設定 Master Node,請先建立 master.yaml 如下:
# master.yaml
# 設定運行模型實驗任務的預設 image ,可以被 experiment.yaml 覆蓋
# image 主要包含 pytorch 和 Tensorflow,如需客製模型實驗任務環境,請參考 步驟 2 附註
task_container_defaults:
image:
cpu: determinedai/environments:py-3.8-pytorch-1.12-tf-2.11-cpu-0.24.0
cuda: determinedai/environments:cuda-11.3-pytorch-1.12-tf-2.11-gpu-0.24.0
rocm: determinedai/environments:rocm-5.0-pytorch-1.10-tf-2.7-rocm-0.24.0
# 設定資料庫連線,將儲存呈現在 Master Node 上的訊息
db:
user: postgres
host: determined-db
port: 5432
name: determined
# 設定取得運算資源的方式
resource_manager:
type: agent # 從 Agent Node 取得運算資源(預設值)
scheduler: # 分配工作到同 Resource Pool 下,不同 Agent Nodes 的方式
type: fair_share # 分配方式:根據工作所需資源做分配(預設值)
fitting_policy: best # 分配策略:用最少的 Agent 執行工作(預設值)
default_aux_resource_pool: default # 對於不需要專用運算資源、輔助或系統任務的任務,要使用的默認 Resource Pool:default(預設值)
default_compute_resource_pool: default # 對於需要運算資源(如GPU/專用CPU)的任務,要使用的默認 Resource Pool:default(預設值)
# 針對各個 resource pool 做設定
resource_pools:
- pool_name: default # Resource Pool 名稱
scheduler: # 同 resource_manager,未設定將沿用 resource_manager 設定
type: fair_share
fitting_policy: best
- pool_name: pool1
scheduler:
type: fair_share
fitting_policy: best更多關於 master.yaml 的設定
客製模型實驗任務環境
步驟 3 — 啟動 Master Node:
# 在終端機運行
# 請將 ./master.yaml 換成自己的檔案路徑
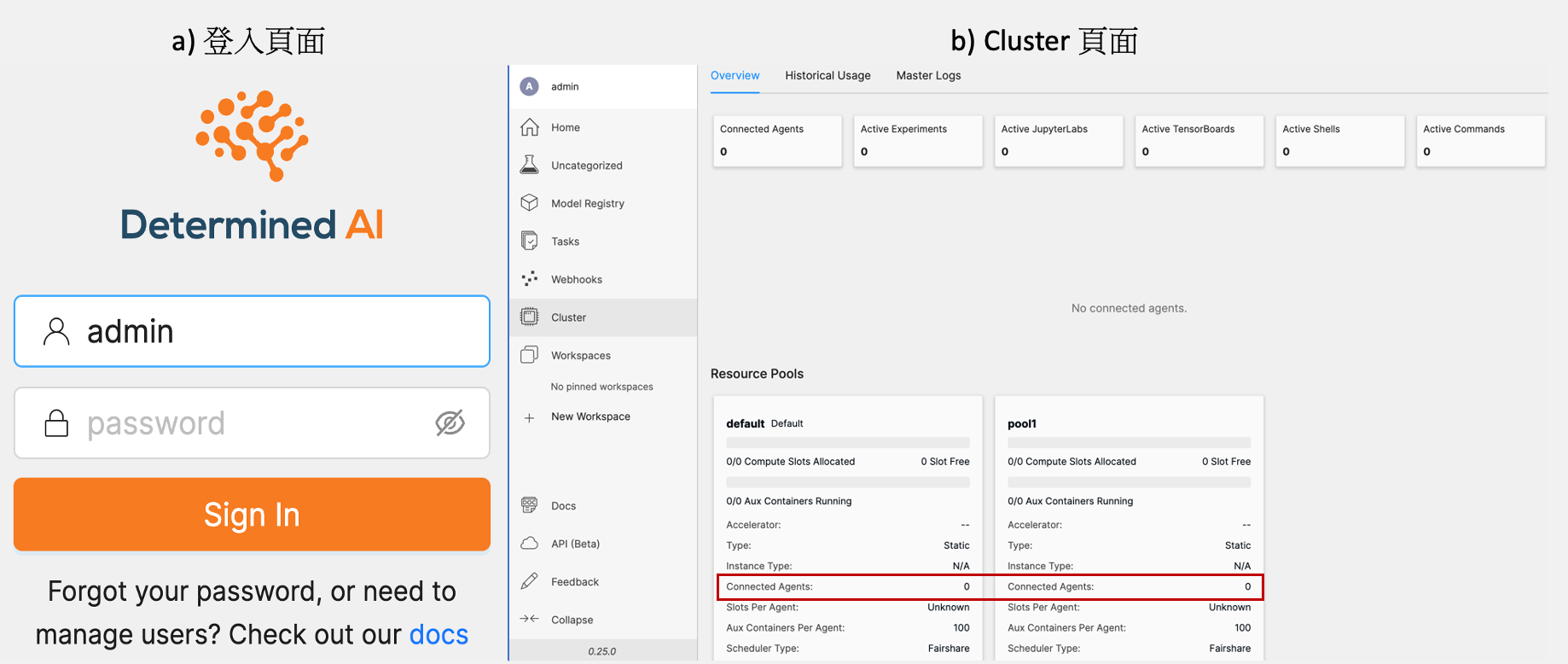
det deploy local master-up --master-config-path ./master.yaml啟動後便可以在瀏覽器輸入 MASTER_IP:8080 進入到 Web UI 的登入頁面(如圖三a),預設帳號有 admin 、determined 兩組,分別為管理員、一般用戶,皆無密碼。 而 MASTER_IP 如果在 master.yaml 中沒有特別設定,將使用該電腦的 預設 HOST_IP。
取得
預設 HOST_IP方式參考# 在終端機運行 # linux ifconfig $(ip route | awk '/default/ {print $5}') | awk '/inet/ {print $2}' | head -n 2 # mac ifconfig $(netstat -rn | awk '/default/ {print $4}' | head -n 1) | awk '/inet/ {print $2}' # linux/mac 輸出範例 # fe80::f1e6:5c46:af01:7b34 --> IPv6 # 172.16.110.13 --> IPv4 , 請使用這個作為 MASTER_IP # windows ipconfig # windows 輸出範例 # 無線區域網路介面卡 Wi-Fi: # 連線特定 DNS 尾碼 . . . . . . . . : # 連結-本機 IPv6 位址 . . . . . . . : fe80::4bdb:1045:4d34:f1a4%13 # IPv4 位址 . . . . . . . . . . . . : 172.16.110.107 --> 請使用有「預設閘道」的 IPv4 作為 MASTER_IP # 子網路遮罩 . . . . . . . . . . . .: 255.255.255.0 # 預設閘道 . . . . . . . . . . . . .: 172.16.110.1
在 Web UI 的 Cluster 頁面(如圖三b)上可以看到 master.yaml 設定的兩個 resource_pools — default 、pool1 。此時,兩個 Resource Pool 都還沒有與 Agent Node(s) 相連,故 Connected Agents 皆為 0。
步驟 4 — 設定 Agent Node,請先建立 agent.yaml 如下:
# agent.yaml
# 設定 Agent ID (必須唯一)
agent_id: agent1
# 設定連接的 Resource Pool
resource_pool: default
# 設定使用哪些 GPU,可以透過 nvidia-smi 或 rocm-smi 的 CLI 查詢 gpu index
visible_gpus: 0更多關於 agent.yaml 的設定
如果有多個 Agent Nodes,請分別設定各自的agent.yaml,如agent-1.yaml、agent-2.yaml。其中,agnet.yaml的agnet_id必須唯一。因此,需要避免與現有agent_id重複。此外,多個 Agent Nodes 可以設定在相同或不相同的電腦上,該agent.yaml將使用存放電腦的運算資源。
步驟 5 — 啟動 Agent Node:
# 在終端機運行
# 請將 ./agent.yaml 換成 自己的檔案路徑
# 請將 MASTER_IP 做更換(可參考步驟 3)
# GPU 版 Agent (本文示範 GPU 版)
det deploy local agent-up --agent-config-path ./agent.yaml MASTER_IP
# CPU 版 Agent (將自動忽略 visible_gpus 的設定)
det deploy local agent-up --agent-config-path ./agent.yaml --no-gpu MASTER_IP如果有多個agent.yaml,可以替換步驟 5中的--agent-config-path參數後,再次執行步驟 5。而如果要在不同電腦啟動 Agent Node(s),須在該電腦存放agent.yaml並執行步驟 5。
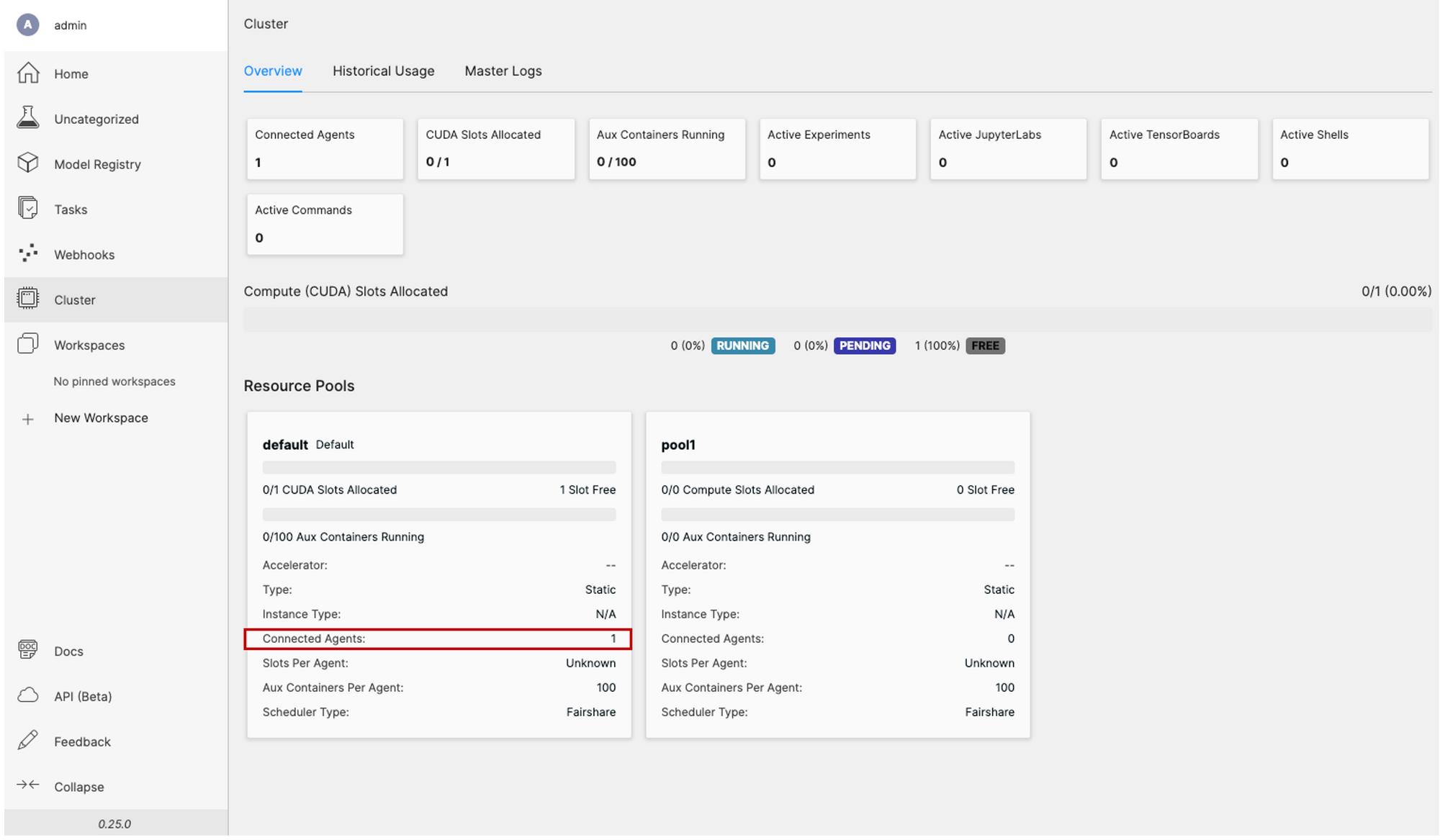
啟動後就可以在 Web UI 的 Cluster 頁面(如圖四)看到多了 CUDA 的資源,並在 Resource Pools default 中看到 Connected Agents 變成 1。
步驟 6 — 完成,可以將您的模型實驗任務上傳到 MLDE 執行囉!上傳的電腦可以與Master Node 、 Agent Node 不同,但也是要安裝 determined 套件 (如步驟1),上傳方法如下:
# 在終端機運行
# 請將 MASTER_IP 做更換(可參考步驟 3)
# 請將 experiment.yaml 換成自己的 模型實驗任務設定檔
# 方法一:
det -m http://MASTER_IP:8080 experiment create experiment.yaml .
# 方法二:
export DET_MASTER=MASTER_IP:8080 # 指定 Master Node 的位址,此指令在同一個環境只需執行一次
det experiment create experiment.yaml .系列文(一)中因為 Master Node 與上傳experiment.yaml都在同一台電腦,所以不用另外設定上傳experiment.yaml的MASTER_IP。如果讀者上傳experiment.yaml的電腦與 Master Node 不同,那就必須要設定MASTER_IP,如此才能將模型實驗任務上傳成功。
更多關於模型實驗任務的程式碼、設定檔內容,請參考官方的模型實驗任務設定檔說明、模型實驗任務範例、系列文(一)
使用 CLI 移除節點
在部署完 Master Node 與 Agent Node(s) 後,可能會因為團隊的資源調整而需要移除節點,或是需要透過移除並重新部署節點的方式修改當前節點的設定。因此,接下來我將分別針對如何移除 Agent Node 與 Master Node(s) 做介紹。
移除 Agent Node(s)
在各自 Agent Node(s) 的電腦上執行:
# 在終端機運行
# 移除當前電腦所有的 Agent Node
det deploy local agent-down --all
# 移除當前電腦指定名稱的 Agent Node ,如移除 agent1
det deploy local agent-down --agent-name agent1檢查 Master Node 的 Agent Node(s) 連線狀況,在 Master Node 的電腦執行:
# 在終端機運行
det agent
# 輸出範例(移除前):
# Agent ID | Version | Registered Time | Slots | Containers | Resource Pool | Enabled | Draining | Addresses
# ----------------+-----------+--------------------------+---------+--------------+-----------------+-----------+------------+----------------
# agent1 | 0.25.0 | 2023-09-04 08:50:59+0000 | 1 | 0 | default | True | False | 172.16.110.13 移除 Master Node
在 Master Node 的電腦上執行:
# 在終端機運行
det deploy local master-down總結
本文透過介紹MLDE的系統架構、事前準備、使用 CLI 部署及移除節點,讓讀者可以快速部署客製化的模型實驗平台在 Docker 環境中。MLDE 主要分成 Master Node 與 Agent Node(s)兩個部分,因此文中分別針對兩個部分進行設定與部署。當然 MLDE 也可以部署在AWS、GCP、Kubernetes等多種環境當中,如有需要可以參考官方說明。最後,針對要如何將自己的模型實驗任務上傳到 MLDE 的實作,不妨參考系列文(一),或是官方的模型實驗任務範例,希望大家有個美好的模型實驗體驗。
Machine Learning Development Environment 相關文章:
系列文(一):用 Machine Learning Development Environment 平台實作 PyTorch 卷積神經網路模型
系列文(二):手把手部署HPE Machine Learning Development Environment
撰稿工程師:許睦辰
參考資料
https://hpe-mlde.determined.ai/latest/index.html
* 本篇文章由人工智慧科技基金會、HPE與AMD共同合作。
docker ps
# 正常運行時,將至少出現以下內容
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES




