
機器學習模型的開發過程中,為了讓模型效能更好,通常資料科學家會設計實驗,擬定要嘗試的模型並對各個模型嘗試不同的超參數組合,以便從中找出表現最好的組合。正是因為要嘗試的組合非常多,可以想像過程中所產生的結果也不可計數,過往需要仰賴人工手動填寫表格,以利管理。
哪些工具能幫助資料科學家開發深度學習模型?
為了讓 AI 專案團隊可以更有效率的管理模型的版本,已有許多廠商針對這一塊需求推出能針對實驗紀錄與版本比較進行管理的產品或工具,例如 MLflow、ClearML、Comet ML 等。除了免去額外開發一套系統的負擔外,由於這些產品多半具有圖形化介面及內建的視覺化工具,就算不熟悉指令列也能快速上手。此外,如果有多 GPU 的主機,還能使用分散式訓練,達到加速的效果。但是,在常見的深度學習框架如PyTorch上,如果要達到分散式訓練,必須修改模型程式碼,如 PyTorch 所提供的簡單範例(*註1),從中會發現模型需要先經過 DistributedDataParallel 處理,開發者必須花更多時間在程式碼撰寫上。
什麼是超參數?更方便的超參數調教工具介紹
提到機器學習模型時,超參數是控制訓練過程的設定值,需要在訓練前就做好設定,不同於自動從數據中學習的模型參數。需要調整的超參數,如學習率、批次大小、迭代次數等,都會對模型的性能、收斂速度和泛化能力產生重要影響。因此,超參數的實驗結果必須被追蹤紀錄,除了手動記錄外,也可以利用工具協助。Hewlett Packard Enterprise(HPE)所提出的 Machine Learning Development Environment(MLDE)解決方案,提供了自動化超參數(Hyperparameter)搜尋,開發者僅需以 MLDE 指定的方式建立模型(下一段的範例有詳細說明),再用一份 YAML 檔指定要搜尋的超參數範圍以及要使用的 GPU 數量,就能以一列指令完成超參數搜尋,並且模型訓練能以分散式運算來執行。訓練完成後,MLDE 內建幾種視覺化工具,可以將實驗結果呈現出來。
實際在 MLDE 上進行卷積神經網路的訓練
為此,我們嘗試以簡單的範例,在 MLDE 上進行實戰演練。這個範例是以 PyTorch 框架訓練簡單的卷積神經網路(Convolutional Neural Network, CNN),來辨識手寫數字。(*註2)若要以 MLDE 來開發,就必須先建立工作資料夾,這個資料夾包含以下幾個檔案:
- model_def.py:用來建立模型物件。
- data.py:處理資料讀取。
- layers.py:用來定義模型中的各層,以此範例來說就是定義CNN裡的各個卷積層(Convolutional layers)
- hp_search.yaml:設定超參數搜尋的範圍以及演算法。
我們先從 model_def.py 開始看起,底下是這份 py 檔中與模型建立有關的程式碼(*註3),其目的是定義模型架構。因為想要做超參數的搜尋,首先得把要嘗試的超參數以 self.context.get_hparam("超參數名稱")的格式取代,再到 hp_search.yaml 中設定 hp_name 的範圍。例如下面程式碼中我們會看到 nn.Conv2d(1, self.context.get_hparam("n_filters1"), 3, 1) 中,輸出通道數填入 self.context.get_hparam("n_filters1"),其他層的超參數,甚至是學習率也都能依照同樣方式取代。
接著就是 hp_search.yaml,這份 YAML 檔設定了實驗中的超參數,要在什麼範圍內搜尋,以及要使用的演算法,以下是範例中的 hp_search.yaml 內容(*註4):
我們看到 n_filters1 與其他在模型建立時填入的的超參數,都分別指定了要搜尋的範圍,在最底下的 searcher 則指定了搜尋方式與次數,例如這份檔案就是指定使用準確率(Accuracy),以及嘗試 128 次。resources.slots_per_trial 則是設定分散式運算要使用的 GPU 數量。最後的 entrypoint 則要填入模型定義的 py 檔以及其中模型的物件名稱。在這份YAML中,最上面的data指定了資料來源,這邊的範例是以下載連結的方式來指定,設定資料的儲存位址後,藉由以下的data.py將資料下載到執行的容器內:
從程式碼可以看出在以PyTorch的dataset的方式製作成資料集,模型訓練時再藉由DataLoader批次讀入模型。如果訓練資料位於本機端,就只需要以一般使用PyTorch框架訓練模型的做法,於model_def.py裡面的「def build_training_data_loader():」建立PyTorch dataset,再回傳DataLoader的方式,就能讀取訓練資料了。
接著簡單說明實驗的執行方式。由於 MLDE 需要在 Docker 容器中執行,所以先安裝 Docker 後,接著透過 pip 安裝 MLDE,即可在本機端啟動一個叢集(Cluster),指令如下:
移動到工作資料夾,於終端機執行以下指令即可開始執行實驗:
接著終端機將輸出:
依顯示的實驗號碼,MLDE 會建立一個實驗紀錄的網站(*註5)。進到首頁後點選「Uncategorized」,再點選實驗號碼,就能進入這次實驗的頁面,例如這個範例就是 20 。)
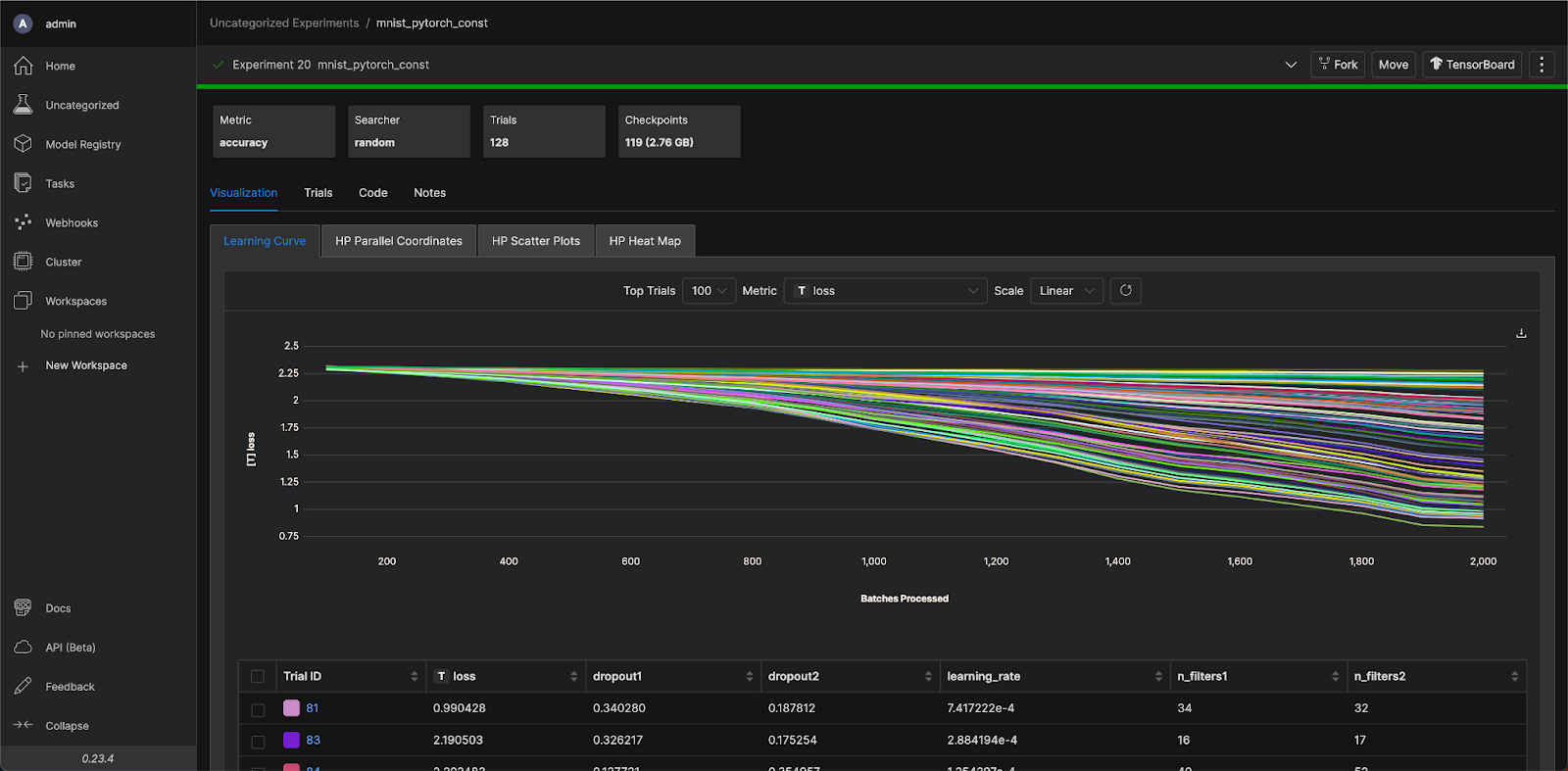
模型的訓練成效好不好? 請觀察 Loss 的變化
至於模型訓練的成效好不好,通常會透過觀察 Loss 的變化作為評估,例如圖 1 中可以清楚觀察到不同實驗中的 Loss 下降情形。
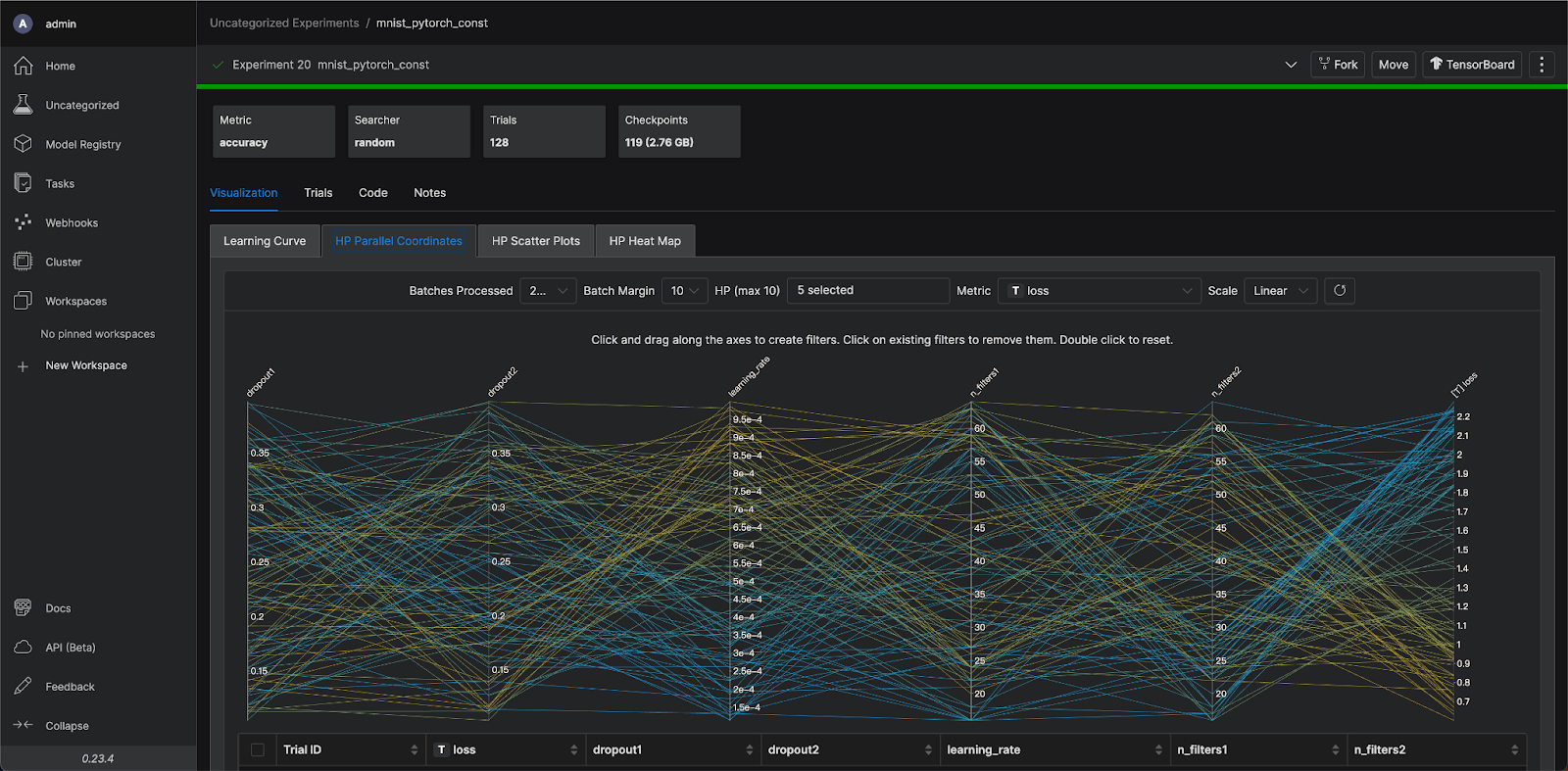
若切換到「HP Parallel Coordinates」( HP 為 Hyperparameter 於 MLDE 平台上的簡寫),如圖 2 所示,就能看到不同的超參數組合對應到的模型指標,包括 Loss 或 Accuracy。MLDE 提供了許多互動式圖表,以 HP Parallel Coordinates 來說,我們能篩選特定區間的超參數或指標,過濾出我們關注的實驗。開發過程中,隨著訓練資料不斷增加或是採用不同演算法,會訓練出不同版本的模型,因此資料科學家必須選擇可以使用的模型,或標記出版本,以便掌控要使用哪一個版本進行上線。
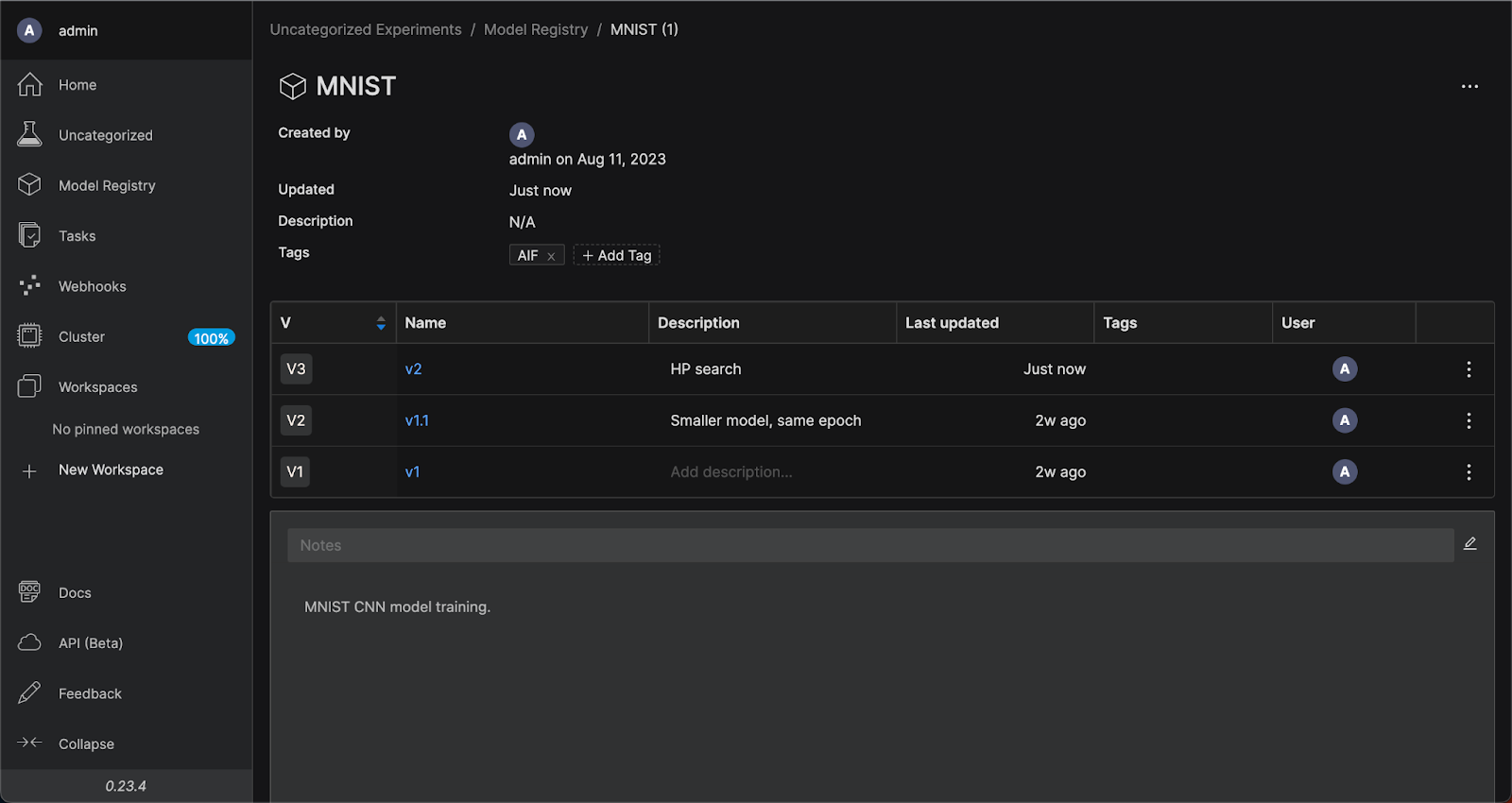
使用 MLDE 訓練模型後,可在「Model Registry」頁面進行模型註冊,每一步驟都能以圖形化介面完成,如圖 3。「Cluster」能即時監控資源使用狀況,例如各使用者的 GPU 時數,以及系統運行紀錄(*註6)。
MLDE 帶給資料科學家的好處
總結目前資料工程師的需求與 MLDE 提供的功能,以往需要耗費大量時間的超參數搜尋,現在只要在 YAML 檔輸入各個超參數的搜尋範圍,不需進入模型程式碼修改就能完成,若設備有多個 GPU,更能以內建的分散式運算縮短訓練時間。從 UI 切入,MLDE 以直覺且可互動的圖表,將實驗結果視覺化,讓訓練過程的 Loss、Accuracy 等指標一目了然。
特別的是,系統預設的顏色看起來就不錯,即使直接用來報告也不會顯得簡陋。不前 MLDE 只支援部分的GPU種類,經測試無法使用 PyTorch 的 MPS (Metal Performance Shaders),主要原因是 MLDE 會開啟 Docker 容器來運行實驗,目前 Docker 的映像檔無法提供 macOS 上的 MPS 功能,在運算設備選擇上稍微受限。模型的版本控制對開發來說也是重要的一環,MLDE 提供模型註冊的功能,模型訓練與版本控制都能在單一平台完成,可以減少其他平台的學習時間,提升開發效率。而如果在開發過程中還需要更多功能,對於資料的版本控制,則可另外使用 HPE 的MLDM解決方案(*註7) 或是 DVC (*註8) 進行版控,或是對於排程如有需求,也能導入 Prefect(*註9) 來實現。
這篇文章的目的是以簡單的範例,模擬只使用單一電腦時,如何進行快速的實驗。當開發團隊的資源較豐富,可能會以多台機器來進行分散式運算,此時就要以較進階的方式來將資源進行整合,關於這部分建議繼續閱讀《手把手部署HPE Machine Learning Development Environment》
Machine Learning Development Environment 相關文章:
系列文(一):用 Machine Learning Development Environment 平台實作 PyTorch 卷積神經網路模型
系列文(二):手把手部署HPE Machine Learning Development Environment
(撰稿工程師:吳宇翔)
參考資料與連結
註1:https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
註2:範例來源請參考https://hpe-mlde.determined.ai/latest/tutorials/pytorch-mnist-tutorial.html
註3:本實作完整程式碼可於以下網址取得 https://github.com/AIF-TW/HPE-MLDE_MNIST-PyTorch
註4:檔案可在註3連結中取得。
註5:如果在本機安裝的話,網址為 http://localhost:8080/(首次使用需輸入帳號 determined,密碼為空白。詳見 https://hpe-mlde.determined.ai/latest/tutorials/quickstart-mdldev.html
註6:如果想用訓練好的模型進行推論,可參考以下程式碼 https://github.com/AIF-TW/HPE-MLDE_MNIST-PyTorch/blob/main/MLDE_MNIST_pred.ipynb
註7:MLDM 解決方案 https://www.pachyderm.com
註8:DVC 網址 https://dvc.org
* 本篇文章由人工智慧科技基金會、HPE與AMD共同合作。





