
深度學習在影像辨識領域上成功掀起了一波AI革命,但是出乎人們意料的是這些模型其實都非常脆弱,脆弱到我們只要針對性的加入一些微小的擾動,就可以讓模型完全失效。
本文作者: 財團法人人工智慧科技基金會 陳宗彥
深度學習發展至今,其中最為成功的莫過於在影像辨識領域上的發展,我們現在有各種各樣強大的基於CNN(卷積神經網路)的影像辨識模型。像是ResNet50,EfficientNet等等。
這些模型在影像上的分類能力非常驚人,甚至超過了人類。
舉例來說,利用EfficientNet架構的EfficientNet-B7已經可以在ImageNet資料集上達到84.4%的Top1 準確率和97.1%的Top5 準確率。而人類的Top5 準確率則是大約94.9%。
深度學習在影像辨識領域上成功掀起了一波AI革命,但是出乎人們意料的是這些模型其實都非常脆弱,脆弱到我們只要針對性的加入一些微小的擾動,就可以讓模型完全失效。
所謂的對抗樣本就是在輸入的圖片中添加一些人類無法察覺的細微干擾,這些干擾就算加了,我們人類也不會覺得圖片有發生什麼改變。但是這些加了干擾的圖片卻會使我們的模型以很高的置信度給出一個完全錯誤的分類。

這些微擾訊號並不是雜訊,而是被刻意選擇的訊號,雖然這些訊號對人類來說跟似乎就和雜訊沒有兩樣,但是機器卻能夠偵測到這些訊號並且認為這些訊號帶有重要資訊,於是給出完全錯誤的判斷。
一些研究還發現這些對抗樣本具有可遷移性(https://arxiv.org/pdf/1610.08401.pdf),同樣一份微擾訊號加在不同張圖片上都可以導致模型錯誤判斷。甚至同樣一份微擾訊號可以導致不同模型都給出錯誤判斷。
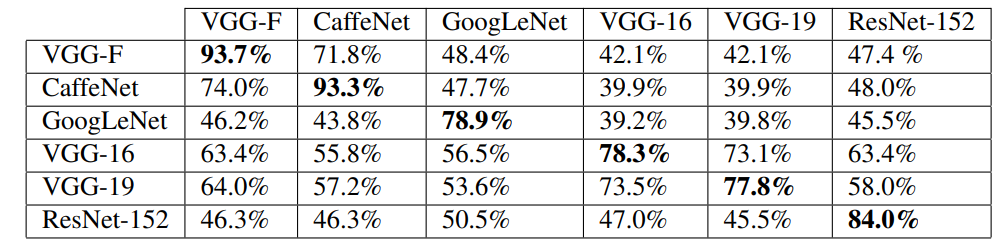
可以從上面的圖片看出,在VGG-F上訓練的對抗樣本,遷移到ResNet-152使用也能使ResNet-152有47.4%的分類錯誤率。
模型如此的容易被攻擊導致很多的問題。如果有人能夠找到一個微擾訊號可以攻擊各種不同模型,那只要將這個訊號實際印出來帶在身上,我們就可以用這個訊號來誤導模型的識別,而這在有時候甚至可以是致命的(例如在自駕車的判斷上將不可通過的區域錯誤的判斷為道路)

也因為如此,對抗樣本的研究也是深度學習中一個很熱門的領域。事實上對抗樣本除了具有可遷移性外,它也能夠攻擊深度學習以外的模型,所以在其他的機器學習模型中,我們也需要擔心對抗樣本攻擊的問題。而且雖然我們到目前為止展現給大家看的都是圖片的例子,但是其實在文字或語音等資料也都存在著對抗樣本問題。
做個簡單的小結 :
對抗樣本具有可遷移性(同一個微擾訊號可以用在不同模型)
對抗樣本具有全域性(同一個微擾訊號可以用在不同圖片)
不只在圖片有對抗樣本,文字或語音等所有其他資料型態也都存在對抗樣本
對抗樣本不在深度學習模型中存在,在機器學習模型也都存在
對抗樣本的存在是AI發展的一大隱憂,如果我們不能很好的抵擋惡意攻擊,我們利用AI所建立的系統將很容易被壞人利用。
Adversarial Examples Are Not Bugs, They Are Features
到目前為止人們還不是很明白為何對抗樣本會存在,而在2019年有一篇MIT的paper試圖解釋對抗樣本出現的原因,以及對抗樣本到底是什麼。
Paper的標題是"對抗樣本不是BUG,它們是特徵" (Adversarial Examples Are Not Bugs, They Are Features)。這篇paper的內容以一句話概括的話就是
我們以為是微擾雜訊的東西其實是存在於資料中的特徵,只是人類察覺不到
作者指出現實中的影像其實包含兩種特徵,強健特徵(Robust Feature)和非強健特徵(Non-robust Feature)。
強健特徵是那些能夠被人類辨識出來的特徵(像是鼻子、眼睛、耳朵、毛髮、紋理等等),而非強健特徵是不能夠被人類辨識出來(看起來就只是一些雜訊),但卻能夠被機器學習到的特徵。
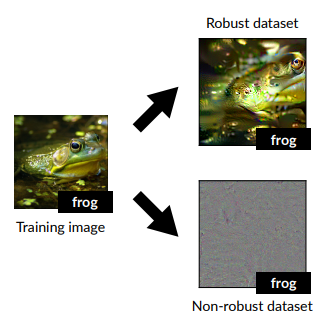
這聽起來很瘋狂,畢竟這些高頻信號的影像在人類看來就只是一些毫無意義的雜訊,而現在要說這些信號其實是特徵,而且它們廣泛的存在於自然界實在很難讓人相信。
作者做了兩個實驗試圖證明這些雜訊其實是特徵。在第一個實驗中,作者將資料集分為只由強健特徵構成資料集的和只由非強健特徵構成的資料集。作者用同一個模型架構在這兩個資料集上進行訓練。使用強健特徵資料訓練出來的模型在正常樣本的準確率和對抗樣本的準確率都是好的,而使用非強健特徵資料訓練出來的模型在正常樣本的準確率是好的,但在對抗樣本的準確率卻是差的。
在第二個實驗中,作者製作了一個被"錯誤標註"的資料集。作者在一般的圖片中加上了非強健特徵,並且將這個圖片的標註改為非強健特徵的標註。(EX: 在一張狗的圖片中加入貓的非強健特徵(利用對抗樣本的原理產生),然後將這張狗的圖片標註為貓)
將利用這個資料集訓練完的模型再拿去對正常的圖片進行預測,會發現它對正常圖片有好的預測準確率。
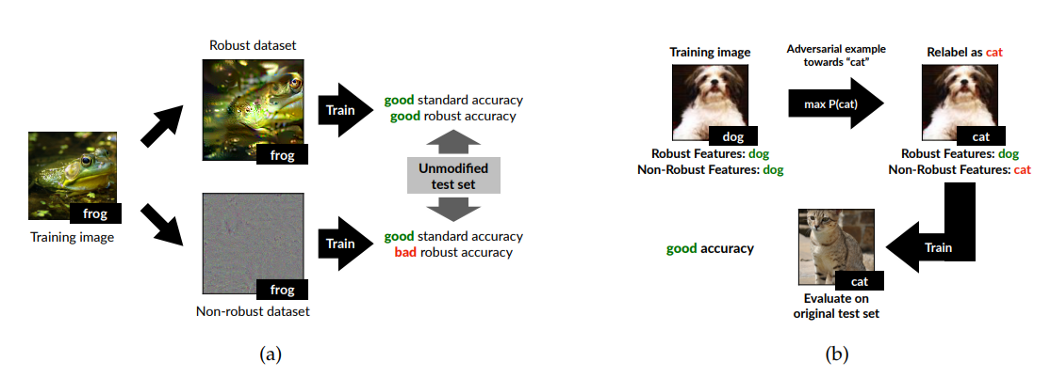
這兩個實驗都是為了展現一個事實,利用非強健特徵訓練出的模型也能夠辨識正常圖片。非強健特徵廣泛存在於自然界中,只不過人類並不利用這些特徵來辨識圖片。而不巧的,機器學習模型會把所有可以幫助分類的特徵都學習起來,所以這些狀似高頻雜訊的特徵被機器學習模型給學習到,並且用來對圖片進行分類。
接著我們來講講第一個實驗:
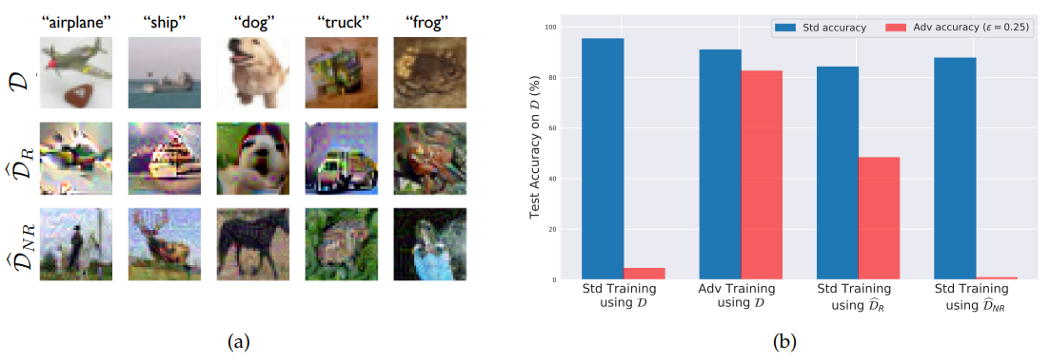
左上那張圖片展示了作者利用CIFAR-10切分出來的兩個資料集,分別是原始資料集,由強健特徵組成的資料集和由非強健特徵組成的資料集。右上那張圖片則是利用不同訓練方式和不同訓練資料集在正常樣本和對抗樣本測試的結果。
可以從圖片裡看見利用正常資料用正常訓練方式訓練的模型對於對抗樣本毫無抵抗能力,而利用正常資料加上對抗訓練方式(此訓練方式可參考https://arxiv.org/pdf/1706.06083.pdf)訓練的模型則能夠抵擋對抗樣本攻擊。
用正常訓練方式在強健資料集上訓練的模型則是有好的正常準確率和較高的對抗樣本準確率,用正常訓練方式在非強健資料集上訓練的模型則是有好的正常準確率和很低的對抗樣本準確率。這是一個正常資料集裡確實包含非強健特徵的證據。
而在第二個實驗中,作者則是在正常資料中加入非強健特徵,並且重新標註了這批資料。接著訓練模型後測試其在正常資料上的準確度。
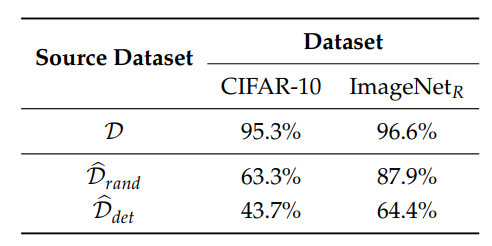
這個實驗中,加入非強健特徵的資料集分為Drand和Ddet。在Drand中,作者在各種不同類別的圖片中加入特定類別的非強健特徵(EX: 在各種不同圖片都加入貓的非強健特徵)。而在Ddet中,作者做了一次標籤順序的交換,只在特定類別的圖片加入另一個特定類別的非強健特徵(EX:在特定類別(例如狗)的圖片加入貓的非強健特徵)。
這個實驗證明了模型可以只靠非強健特徵來判斷正常圖片,在Ddet訓練的模型因為強健特徵也會對應到某個特定的標籤,所以在測試時的準確度較低。
這篇文章的重點就是在我們的生活中,到處都充斥著人類察覺不到的特徵,而這些特徵能夠被機器發現。假設對抗樣本的微擾訊號真的是特徵的話,就可以很輕易地解釋為何對抗樣本會具有可遷移性,也可以解釋為何同一個微擾訊號可以同時作用在許多不同圖片上並且也能夠誤導模型。
但是另一方面來說,即使有部分對抗樣本的微擾訊號真的是某種特徵可以幫助我們辨識正常樣本,我們也不能說全部的微擾訊號都是特徵(有些可能對辨識正常樣本無幫助),這篇文章並不能排除模型本身依然存在問題的可能性。
這個嶄新的想法也激起了學界許多的討論,正反兩面的意見都有。作者在此篇文章中只利用了CIFAR-10和MNIST資料集來做實驗,這兩者的圖片解析度都很低,這是因為作者在論文中使用的算法難以在大解析度圖片上使用。這個論文的結果能否在如ImageNet的資料集上重現是一個重要的問題。
另一個問題是假設這些非強健特徵真的存在,那它們到底代表什麼? 會不會有其他生物能夠察覺到這些特徵?
Google發了一篇blog討論這篇文章,文章連結在此: https://distill.pub/2019/advex-bugs-discussion/ 各位有興趣的話可以參考看看。
今天的對抗樣本介紹就到此結束,希望各位會喜歡。
本篇論文導讀原文連結:https://arxiv.org/pdf/1905.02175.pdf




